System Design Questions (Try Exponent)
1 - Design a URL Shortener
Watch Jacob, Dropbox SWE, answer the technical system design question "Design a URL shortener."
Note: This one's a bit technical! You likely won't be asked to go into this depth for a PM interview, but it's good to review so you can understand a bit more about the architecture-type questions you may be asked about.
2 - Design Instagram
In this interview, Jacob (Dropbox Software Engineer) answers a system design interview question of designing Instagram, commonly asked in software engineering and technical program management (TPM) interviews.
3 - Design a landmark recognition system
Jimmy (Amazon ML Engineer) answers the interview question, "Design a landmark recognition system."
4 - Design a rate limiter
Watch Hozefa, Engineering Manager @ Meta, design a rate limiter.
5 - Design Amazon Prime Video
Watch Abhishek, Engineering Manager @ Flipkart and ex-startup founder, answer a system design question on designing Amazon Prime Video.
6 - Design a parking garage
Neamah asks Tim to design a reservation and payment system for a parking garage.
7 - Design YouTube
In this mock system design interview, Hozefa (Wealthfront EM) answers the interview question, "Design YouTube or a YouTube like service."
Key Concepts:
- Reliable and Resilient Infrastructure: A video streaming service must be highly available and resilient to failures to ensure a seamless viewing experience for users.
- Load Balancing: Load balancing is important for ensuring that incoming requests are distributed evenly across available resources, allowing for efficient processing of large amounts of video data.
- Building Distributed Systems: Distributed architectures, messaging protocols, and consistency models are important for building a scalable and reliable video streaming service.
Efficient Video Streaming: YouTube-like systems need to serve both content creators and viewers. Creators should be able to upload videos from any device, and the system should process them. Viewers should be able to watch videos on any device.
Non-Functional Requirements: For non-functional requirements, the system must be highly available. It should prioritize reads over writes.
Content Creation: To help creators, the system should have an API for uploading video metadata and the video itself.
Large videos can be uploaded through an open socket connection. The system can use a queueing system to process videos into different formats and resolutions.
Videos can be stored in a relational database and blob storage, like S3. The system can split the databases by creator to scale it.
Content Consumption: Viewers can use a streaming service with a Content Delivery Network (CDN) that checks the database to validate permissions and retrieves the video from the blob storage. The system can partition videos by creator.
An adaptive bitrate system can adjust streaming quality based on the viewer's connection speed. An in-memory cache can be used to prevent overload during high-traffic periods, and an invalidation strategy can be used to remove outdated videos from the CDN.
For analytics, a stream or analytics system can be set up.
Improvements: One suggestion for improving the design is to add more fault tolerance measures, such as a master-safe slave configuration for the database.
Additionally, space and cost optimization should be considered, especially for a data-heavy system like a video streaming service.
8 - Design TikTok
Watch Adam Schneider, Google TPM, answer the system design question "Design TikTok."
Key Concepts
- Reliable and Resilient Infrastructure: TikTok's system must be able to handle a large number of users and always be available.
- Load Balancing: TikTok must be able to handle a significant increase in traffic. A load balancer can help distribute traffic and ensure that the system is able to handle the load.
- Choosing a Database: TikTok will need to store and link structured user data objects. Choosing the right database is important to ensure that the system can handle the load and respond quickly.
Consider the Scale of the System: To store compressed video files and user metadata, you need a system that is always available, responds quickly, and can grow to support more users. TikTok has one million users who use it every day, so the system must be able to handle that many people.
API and Database Schema Design: An API can be designed with endpoints such as "Upload Video" and "Get User Activity".
A relational database system, such as PostgreSQL, can be used to store and link structured user data objects.
To reduce the load on the database and improve latency, preloading a cache of the top ten videos for each user can be implemented.
Video UUID and ID Field: To associate user activity, such as liking and following videos, with specific videos, a video UUID and ID field is required.
User activity can be stored in a database, and an API endpoint can be developed for a GET request to return a list of the user's likes and followers.
Content Delivery Network and Load Balancer: To handle a 10x increase in traffic, a Content Delivery Network (CDN) can be used to cache and route video content traffic to the closest node.
A load balancer can also be used for scaling deployments and performing zero downtime deployments.
Regional Database Sharding and Pre-Caching Service: A regional database sharding service can facilitate the distribution of load between databases and a read-only worker.
A pre-caching service can be implemented to manage GET requests and preloading video content
9 - Design typeahead for search box
In this mock interview video, Andreas (Modern Health SWE), answers the interview question, "Design a typeahead box for a search engine."
10 - Design the payment system for the Amazon Kindle
Watch Karan, Sr. Software Engineer @ Curebase, answer a system design question where he is asked to design the payment system for the Amazon Kindle.
11 - Design Facebook Messenger
Watch Jacob, Exponent co-founder and Dropbox software engineer, answer the system design question "Design Facebook Messenger"
12 - Design a Web Crawler
Design a web crawling system that will download and save the contents of every webpage, given a starting URL or set of URLs. Web crawlers (also known as bots or spiders) are used by Google and other search engines to index the Internet, but they can be used for a variety of different purposes, such as data extraction, automated monitoring and testing, and generating previews of websites.
Requirements:
- Should accept a starting URL or set of URLs
- Should save and output HTML from all pages that it visits
- Should scale to millions of webpages and store data efficiently
Hint 1
Start with a simple approach before tackling the entire problem. Think about how you would design a single web crawler.
Hint 2
Where can we store the large amount of data we're collecting? What part of our system will be responsible for storing or retrieving this data?
Hint 3
Consider using a multithreaded or distributed approach to crawling. What would have to change about your system to support this?
Challenge 1
How much space would it take to save a million webpages? How much time would this process take? Are there any ways to improve the time or space requirements of your system?
Challenge 2
How would your crawling algorithm work? How do you decide which pages to visit next? How would you deal with cycles where several pages link to each other?
Challenge 3
Let's imagine we want to save different 'snapshots' of webpages over time so we can analyze changes between visits. How would you update your system to support this?
Full Solution
Designing a web crawler is a great real-world problem that also gets asked frequently in system design interviews. Answering this question successfully requires demonstrating a thorough understanding of how the web works at a conceptual level and also explaining the technical approaches to process and store data at a large scale.
1. Define problem space
The first step is to explore and clarify what features and requirements are in scope for the discussion. Besides the requirements we're given, are there any other clarifications or constraints we should ask about? Here are some examples you might ask:
- Should we prioritize crawling certain webpages over others (e.g. internal links vs. other websites) or visit them in the order they appear?
- Is there a maximum depth that we should crawl to, or any constraints on the amount of data we can store?
- Can we assume that all pages contain HTML? Should we store other document or media types?
2. High-level Design
We can loosely divide the problem of building a web crawler into the following steps or components:
- Crawler implementation
- Data processing and storage
- Parallelization techniques
3. Define each part of our system
Next, we'll dive into the details of each component of our system. First, let's talk about how to actually build a web crawler conceptually.
Crawler implementation
All web crawlers must fundamentally perform some variation of the following behavior:
- Visit the next URL and load the contents
- Parse or extract the contents to find URLs (e.g. anchor tags)
- Add URLs to the list of pages to visit next
- Repeat until there are no more URLs left to visit.
There are many ways to implement this procedure. Ultimately, we must decide whether we will take a breadth-first or depth-first approach to visiting pages. Let's assume we want to take the breadth-first approach, meaning we want to visit URLs in the order we discover them. One way to implement this would be to use a queue-like data structure to store the URLs we have yet to visit, initializing it to first contain only the starting URLs we are given. Since queues are a first-in-first-out (FIFO) data structure, we would visit URLs in the order we add them to the queue.
Next, our program must visit the page and download its contents. By "visit" we actually mean we will make an HTTP request to the URL and load the contents of the page, which includes HTML metadata and content which may contain text and links to images and videos.
It's worth noting that many modern websites are not simple HTML, but rather contain rich JavaScript applications that load content via scripts and APIs. Let's assume these kinds of websites are not our primary focus for now.
After we've loaded the page, we'll want to parse the raw HTML and extract any links that it contains. This sounds complex but is usually handled quickly by any number of standard HTML libraries. Once we have a list of links, we can append these links to our queue, and return to the first step.
Data processing and storage
In order to build an Internet-scale web crawling system, we'll need to have a storage system that supports a massive amount of data. How much storage space will we need? Let's assume that the average page size is 200KB. This means to store 1 million web pages (10^6), we would need
10^6 * 200 * 10^3 = 200 * 10^9 = 2 * 10^11 bytes = 200 gigabytes
More realistically, there are at least a billion (10^9) webpages on the Internet:
10^9 * 200 * 10^3 = 2 * 10^14 = 200 terabytes
We will definitely need a lot of space, but our exact choice of storage system will depend on the anticipated use cases of our system.
For example, if we want to download and store the contents for offline archival or research, we could simply compress and store all the contents with a low-cost cloud storage provider. On the other hand, if we want to use the content for real-time search or lookup, we may instead choose to store the content in a large distributed database—-e.g. HDFS, Google's BigTable, or Apache Cassandra-—that could better support querying and search.
In either case, there is simply too much data for our program or server to store in memory, so we will need to progressively upload or move the contents to the storage system as we are crawling, otherwise we will run out of space before we finish. Thus, we can imagine our crawling system as a kind of data pipeline that repeatedly downloads, extracts, and moves the content to long-term storage. This process is commonly known as "ETL" (for "extract, transform, load").
Parallelization
In order to make our web crawling system more efficient, we can parallelize our actions across many processes or machines working in tandem. In general there are several techniques for achieving concurrency and parallelization:
- Use a multi-threaded or asynchronous approach to increase throughput of the program
- Run multiple instances of the program as separate processes on the same machine
- Run multiple machines or 'workers' with a shared job queue
There's no reason we can't combine all of these approaches to achieve faster results. Using a distributed pool of workers, however, will require a change to the way URLs are queued and prioritized: in order to share the load evenly across many machines, we'll need to centralize queueing or URL prioritization system, otherwise we are likely to end up with imbalanced load on a subset of workers while others are idle.
13 - Design a Web Crawler (Video)
In this video, Andreas answers how to design a web crawler.
Key Takeaways
- Load Balancing: The crawler is expected to handle a large volume of data. It's important to distribute the workload evenly across multiple servers or instances to prevent bottlenecks and improve performance.
- Distributed Systems: Since the crawler can be implemented with multiple components and distributed across multiple servers, understanding common design patterns for distributed systems can help ensure that the crawler is scalable, reliable, and fault-tolerant.
- Choosing a Database: Since the web crawler requires storage for the data it collects, it is important to choose a database that can handle the volume of data and provide efficient indexing and retrieval. Understanding the tradeoffs between SQL and NoSQL databases can help make an informed decision.
Step 1: Define the Problem Space: This mock interview explains how to design a web crawler capable of handling HTML pages and HTTP protocols. The crawler should also be expandable to other media and protocols, as well as scalable, extensible, and fresh.
Step 2: Design the System at a High Level: The crawler's process begins with seed URLs and uses a priority ranking system to determine the order in which to crawl the next URLs.
The fetcher or renderer component handles the fetching and rendering process and can be implemented with multi-threaded systems.
For 50 billion pages, the web crawler requires approximately 6 petabytes of storage, which can be optimized using annotated indexing and compression.
Step 3: Deep Dive into the Design: The process of crawling websites involves obtaining content from URLs. This is done using a DNS resolver as an intermediate step for optimized routing.
Next, short-term and long-term storage options are chosen.
Responses are queued up and duplicates are cleared. URLs are normalized using a Bloom filter data structure and distributed file system.
It is also important to prioritize crawling using timestamps to ensure politeness and individual website limitations.
Step 4: Identify Bottlenecks and Scaling Opportunities: Further discussion is needed to fully understand fault tolerance/bottlenecks and ensuring that another crawler can take over if one of the distributed crawlers dies.
Adding features such as malware detection as separate services could improve the overall system.
Step 5: Review and Wrap Up: This interview provides a comprehensive and informative overview of designing a web crawler, emphasizing the importance of scalability, extensibility, and freshness in the crawling process.
It's important to consider fault tolerance and bottlenecks in the design to ensure the crawler can handle high volumes of data.
14 - When should you use HTTP vs. HTTPS?
Web services using HTTP and HTTPS are one of the most common calling patterns in most products (e.g. Mobile Apps, Desktop applications, middle-tier services etc.). Almost all TPMs would have had to work with HTTP/S web services at some point or the other, and are expected to know about them. So, this question can be used by the interviewer to judge the following:
- Whether the candidate has any relevant TPM experience. A sub-par answer can be a rather significant negative.
- The depth of technical knowledge that the TPM has. A good TPM should know why they (or their dev team) is making the choices that they're making.
- A good knowledge of the trade-offs involved in this decision, and whether the candidate can make the right recommendation for the right situation.
Our answer:
A good structure to this answer would be to start off by talking about how HTTP works, and the underlying problem that is solved by HTTPS. Then describe, at a high level, how HTTPS works and why it's a good solution for the problem faced by HTTP. End by demonstrating clearly that you're aware of the tradeoffs between HTTP and HTTPS, and indicate which option to prefer under what circumstances.
Going into the details of how certificates and trust relationships works can be skipped unless the interviewer specifically asks follow-up questions in that direction.
HTTP, or HyperText Transfer Protocol, is a text-based protocol used for communicating between a client and a server. Typically, an interaction is initiated by the client, which requests a particular resource on the server.
For HTTP requests, the client connects to a well-known port (typically, 80) on the server, and sends additional information as plain text on the connection. A sample request where the client sends web form data to the server looks like the following:
POST /test/myform HTTP/1.1
Host: example.org
Authorization: Bearer eJW6t....
name1=value1&name2=value2
Since all this is sent as plain text, it's very easy for a man-in-the-middle (such as a proxy server) to intercept and read, or even modify, all the data going to the server. This includes authorization tokens, headers, and other forms data (like the user's address and credit card number).
HTTPS, or Secure HTTP, uses Secure Sockets Layer (aka SSL) to establish a secure connection between the client and server that's highly resistant to interception.
When a client attempts to connect to a URL via HTTPS, it establishes a connection to a different port (typically, 443). After the connection is established, the client receives the server's X509 Certificate that identifies the server.
If the client trusts the server's certificate, it uses the public key embedded in the client certificate to encrypt the HTTP headers and body being sent to the server. Since only the server has the certificate's private key, only the server is able to decrypt the contents of the connection.
Almost all SSL certificates use modern encryption algorithms such as SHA256, and are backed by 128-bit keys, which makes it nearly impossible for an attacker to brute-force guess the public/private key pair. As a result, the payload is an opaque encrypted blob that can no longer be decrypted by any proxy server or man-in-the-middle.
Trusting the server:
How does the client decide whether the server's certificate is valid?
The server certificate is actually composed of a certificate chain, or a list of certificates that identify a chain of certificate issuers that have a trust relationship with each other. For example, the certificate of www.tryexponent.com is issued by Let's Encrypt Authority X3, which is in turn issued by DST Root CA X3. This means that the DST Root CA X3 has done its due dilligence and validated the identity and credentials of the intermediate certificate authority (Let's Encrypt). The intermediate Certificate Authority has in turn validated tryexponent.com.
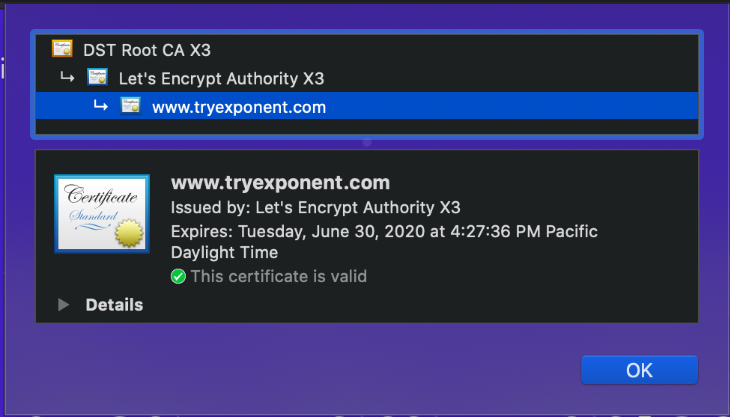
On the client, if DST Root CA X3 is present in the Trusted Root Certificate Store, then Exponent's SSL certificate will be trusted implicitly, because the client trusts DST Root CA, which trusts Let's Encrypt, which trusts tryexponent.
The client also performs additional checks on the certificate chain, such as:
- Verifying that the certificate isn't expired.
- Verifying that the Subject Alternate Name list in the certificate matches the domain of the server that is responding.
- The certificates in the chain have not been revoked by the CA.
Having this trust relationship and additional validation allows the clients to trust that the website is what it claims to be.
When to use HTTPS vs. HTTP?
The initial step of establishing a secure connection, downloading and validating the certificate takes much longer than a simple HTTP connection. As a result, HTTPS connection establishment latency becomes a potential issue when dealing with very high-speed or low-latency situations.
Typically, external clients deal with this by using connection pooling and keeping connections warm. Similarly, data centers are configured such that the HTTPS connection terminates at the entry load-balancer, and all internal high-speed communication within a DC (over very fat pipes) is done over HTTP.
In general, HTTPS is strongly recommended for any client-server communication, except in cases where the connection establishment latency is a significant factor and the communication is otherwise secure by hardware limitations (e.g. intra-Data-Center).
15 - Break a monolith into microservices
Let's come up with a plan to break our monolith into microservices. Some context is that our company is growing rapidly enough that the monolith codebase is starting to slow down developer velocity. Additionally, having only one deployed application results in less availability to customers because an outage in one portion of the application affects the entire application.
Hint 1
How do you break up a single application into many applications and who all would be involved in such a process?
Hint 2
What kind of application is it (consumer, enterprise, etc.) and what would each service be for?
Hint 3
First, ask clarifying questions to understand the scope of the question better. Second, use a whiteboard or piece of paper to sketch out the parts of a program (planning, implementation, and closure). Third, start detailing steps within each part of the program, ultimately coming up with rough timelines.
Challenge 1
Do you have a clear and cohesive diagram of your approach?
Challenge 2
Do you have a list of stakeholders?
Challenge 3
Do you have a list of risks with potential mitigations?
Challenge 4
Do you have a contingency plan? What happens if we don't hit the timeline?
Full solution
Note: In this lesson we explore a classic system design question typically asked of Technical Program Managers.
Approach
Let's draw out our approach following the TPM framework for a program (planning, implementation, and closure) and iterate as we learn more information.
This is a question that is quite huge in scope technically so let's keep it high-level to get an idea of the overall plan, diving deeper as needed for any technical considerations.
Solution
Oh, I've done this in a prior job and it is a huge effort! Let's start off with some clarification questions and then we can begin to formulate a program to tackle this.
What is the timeline? A quarter.
How many resources do we have for this project? A development team of 5 software engineers, an engineering manager, and a quality assurance (QA) team of 2 QA engineers.
What is considered success? When we hit a certain number of services or when the entire monolith can be retired or deprecated? Entire monolith can be retired.
When do our external users typically use the platform? During normal business hours.
Do external users use our application programming interfaces (APIs) and will we need to maintain API contracts during this transition? Yes and yes.
Are we just spinning up a service or are we also creating separate databases (DBs) for each microservice? Good question. We'd likely want separate DBs to make our system as distributed as possible.
Which internal customers ingest data from the platform? The business analytics team ingests data from our platform regularly to power dashboards used by executives to make critical decisions.
Great, this helps us better understand the ask. Now, let's talk about the first part, which is planning. Planning involves defining the ask and relevant constraints, knowing who the stakeholders are, delineating risks and possible contingency plans, and identifying timelines. I'm going to write down what I think are answers to these points based on my current understanding. Let me know if I'm misunderstanding anything.
The next part is implementation. The immediate task here would be to have the engineering team break down the work into digestible chunks while pushing for approaches that would minimize downtime and any upstream changes to consumers of the platform. Let's say the eng team decides to break the monolith into 10 key services and that each service will take 1 week to migrate code, test it locally, spin up the service and relevant DB in production, and switch over traffic to the service. That is about 2.5 months, giving us an extra few weeks of cushion in case unexpected things come up. If we feel like things aren't going as quickly as planned halfway through this project, we can escalate that risk and make the case to management of bringing in another team of engineers to speed up progress. The key metric to monitor progress during this monolith to microservices phase is the number of total running services. Also, during this process of spinning up services, we'd want to be thinking about the following things:
- the switch of traffic from the current application to the new service should be done during non-business hours so downtime, if there is any, is not noticed
- the new deployment pipelines that need to be present for each new service
- functionality parity of the service to the current application should be verified by the QA team
- other stakeholders (external API consumers or internal teams like the business analytics team) need to be kept in the loop of any interface or contract changes and any expected downtime
The last part is closure. As each part of the monolith is migrated successfully into a service, that part of the monolith needs to be deprecated and/or deleted. Documentation needs to be updated if anything has changed to consumers of the platform. To ensure that the project met its initial goals, the new services need to have metrics to be measured against such as availability and developer velocity. Developers need to be on-boarded to the new codebases. And, assuming the initial goal of migrating the monolith entirely to micro-service has been met, there should be a celebration to reward the folks who worked on the project.
Example whiteboard diagram:
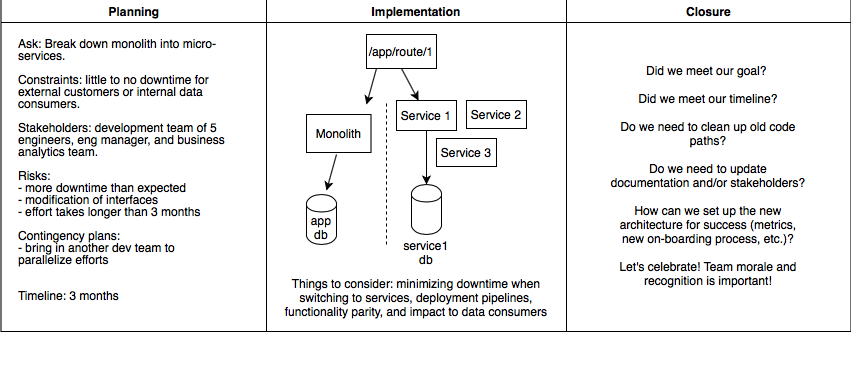
Takeaways
Be conversational, inquisitive, and comprehensive. Obviously, the response and diagram above were written under non-interview conditions but the overall approach should be similar (ask questions, define a program to meet the needs, and iterate).
With any technical question, the whiteboard and/or paper are your friends; they're also used by your interviewers as supporting material to judge how your interview went.
Experience helps so ask yourself if you have been involved in such an endeavor before. What considerations did you have when performing the monolith to microservices transition? Bringing these considerations up shows personal involvement which brings color to something theoretical.
Be ready to provide very technical answers to some of the high-level things mentioned above. Depending on the technical nature of the interviewers, you might get asked about the actual structure of a microservice from load balancers to database design or actually how to technically minimize downtime or how to maintain data interfaces even though underlying architectures might change. Brushing up on system design will be to your benefit!
Having a framework to fall back on is helpful if you get nervous or forget where to go to next. The Planning, Implementation, and Closure phases of program management is a good one to understand.
Pulling back to see the bigger picture and how this project affects the company as a whole is a bonus. The mentions of pulling in more teams to execute faster or updating internal stakeholders or measuring how switching to services would impact availability all indicate bigger picture thinking as it's not just about the project but how it affects other components at the edge of the scope of this question.
16 - Tips for system design questions
Keys to success:
- Before jumping into a solution, define who and what you are solving for since this will help you easily reason through different tradeoffs along the way.
- At each decision point give multiple options. Then talk through the tradeoffs and state why one of the options you presented is the best in the context of the problem. Interviewers want to see your decision process and that you are able to weigh tradeoffs to come to a conclusion given the constraints of the problem.
- This is an interview that you as the candidate are driving, if done well. The exceptions are if the interviewer answers questions to help set the initial criteria and potentially directs which part of the system to focus in-depth design on.
- The key is to be continually answering the question “Why?” for each decision you are making. Go the extra mile!
Easy pitfalls:
- It is tempting, especially with obvious decisions, to not explain why, however this doesn’t show the interviewer your critical analysis. If the interviewer has asked why you made a certain decision, chances are you missed an opportunity to explain your reasoning upfront.
- It's okay to borrow from the architecture you are most familiar with and have used in the past either on a project or at your current company. The key here, again, is to explain why it is the right choice for this system, otherwise it may look like you only know something because it’s what you’re used to.
- It can be tempting in this type of interview to just ask the interviewer what they may think are the best options. Remember that the purpose of the interview is to see how you make decisions and your ability to discuss tradeoffs.
17 - Design Uber Eats
How would you design a food delivery app like Uber Eats or DoorDash? Watch Neeraj, Engineering Manager at eBay and Exponent coach, as he walks us through his solution to this system design interview question.
Designing a Food Delivery System
The design of UberEats requires attention to both functional and non-functional requirements. To begin, define the needs of all stakeholders – restaurants, customers, and delivery people.
Functional Requirements
The top priority is to design a system that allows restaurants to add their information and customers to view and search for nearby restaurants based on delivery time and distance. This system requires eventual consistency to ensure the accuracy of restaurant information.
Non-Functional Requirements
High availability, security, scalability, and latency are all critical non-functional requirements. The expected numbers of daily views, customers, and restaurants must be taken into account.
Data Modeling
Successful design involves data modeling for restaurant and menu items, including geohashing for optimizing delivery routes.
To optimize proximity comparisons between different locations such as restaurants and customers, the system subdivides the world into smaller grids and maps them into binary values encoded using base 32.
This encoding system optimizes proximity matching between different locations. Data modeling involves the use of relational and noSQL databases for different data tables and optimizing the user experience for uploading new restaurant information.
Services and Components
Employing ElasticSearch service on Cassandra for sharding and scaling with separate databases for optimization purposes is crucial.
Multiple services such as a search service, viewing service, and restaurant service could be employed for efficiency, with the search service incorporating ElasticSearch and geohashing.
Isochrones and polygons are useful for estimating delivery times and identifying delivery areas. The viewing service could include caching frequently viewed menus and leveraging isochrones to estimate delivery times for customers.
The restaurant service could track all events using Kafka queues and implement an API for moderation, optimizing the system's efficiency.
Other Considerations
Scalability, optimization, and customer experience are critical factors in UberEats' design.
A seamless system must be designed to cater to all stakeholders' needs. By considering all stakeholders and their requirements, an efficient system can be developed to provide a seamless experience.