Fundamentals of System Design (Try Exponent)
1 - Introduction to system design
Great coding skills will get you far in a software engineering career, but strong system design skill will get you further. Senior software engineers' (SWE) performance in system design interviews is often more important than coding rounds, and for engineering managers and up, system design replaces coding entirely.
Why? Because system design interviews are as real as it gets in terms of assessing true on-the-job performance. Great engineers must understand how distributed systems work — how each component processes information, communicates, and scales up or down — because this high-level view is critical to strategic decision-making. Anything else is reactive.
Goals of the course
- Discuss the necessary tradeoffs between reliability, scalability, and maintainability in real-world systems.
- Review common components of distributed systems and design strategies and describe what they are, why they're important, and when to use them.
- Apply a framework to system design questions to arrive at a high-quality system design quickly.
- Identify and avoid common pitfalls in system design interviewing.
The purpose of this course is to give you the resources you need to feel confident in system design interviews. You'll orient yourself to your interviewers' perspective and practice a framework for working through vague problems, review fundamental concepts and must-know components, learn common design strategies and when to use them, and, of course, practice.
How to get the most out of your system design prep
We recommend following the below study plan.
- Read through the next lesson on the system design interview to get a sense of what interviewers are looking for to orient yourself to the course. System design and system design interviews are a bit different. You'll want to practice your communication skills as thoroughly as your design fundamentals.
- Next, read through the framework for acing system design questions and note the timing. We've designed the framework such that you can cover everything important in your 45-minute round. Keep the cadence in mind, and begin to practice as soon as you can.
- Watch a few system design mock interviews to get a sense of how SWEs and EMs answer these questions in interviews. Try to get a feel for where your own weak areas are conceptually - this will help you prioritize your fundamentals practice. Once you know what to focus on, we recommend you start by browsing through the system design glossary to re-familiarize yourself with important terms before beginning the system design fundamentals course.
- Read about the architecture(s) in place at your target company to get in the right mindset. After you're familiar with the format, choose a practice question asked recently at your target company. When you're ready for live practice, sign up for a peer mock interview. System design mocks run twice daily at 8:00am and 6:00pm PST. Sign up now!
2 - The system design interview
System design is a squarely technical interview, right? ...Not quite.
System design rounds are categorized as technical interviews, much like coding rounds, but they differ in a few significant ways. For example:
- Most prompts are intentionally vague. Coding challenges are clear, system design prompts are not. You choose which direction to take — which is why asking clarifying questions and following a framework are so important. You're time-bound, so staying on track is key.
- There is no "right" answer. It's true that there are good designs and bad designs, but as long as your choices are justifiable and you articulate tradeoffs, you can let your creativity shine.
- You're engaged in a two-way dialogue. This is critical. In a real-world scenario, you would never go off on your own with only a vague idea of what to build, right? We hope not. You want to work with your interviewer every step of the way. Spend a good amount of time clarifying requirements in the beginning, check-in throughout, and make sure to spend time summarizing and justifying your choices at the end.
Even the most brilliant engineer can tank the system design interview if they forget that communication skills are being assessed too. Unlike most coding rounds, the system design interview mimics real-world conditions. It's not often that you're given clear requests with features neatly outlined. Mostly, you'll have to tease out specifics yourself. The best engineers are able to take fuzzy customer or business requests and build a working system, but not before asking a lot of questions, thinking through tradeoffs, and justifying their choices. Keep this in mind as we walk you through the basics.
Which roles will encounter system design questions?
Nowadays, we're all working hard to build scalable applications. System design skills are applicable to more roles than ever before, but it should make sense that the rubric for an engineering manager with 15 years of experience will be very different from a junior software engineer, which will differ from a technical program manager. Whatever your role, we believe that it's worth spending a significant amount of your interview prep time studying system design because it will help you perform better at your job.
What is the format?
Typically, you'll be given 45 minutes to an hour to design a system given a vague prompt like "Design a global file storage and sharing service." Companies like to ask you to design systems that will solve problems they're actually facing, so it's good practice to orient your prep to the types of questions you're likely to be asked.
For example, if you interview at Google, focus on search-related questions. At Facebook, practice designing systems that handle large file storage. At Stripe, practice API design or authentication-oriented questions.
You'll likely use the whiteboard (if you're in person) or an online tool such as Google Drawings to outline your design.
If you have an interview scheduled, ask your recruiter how you'll present and practice answering questions within that medium. If you're told you can choose, we recommend picking one tool and practicing consistently. This will help alleviate anxiety on the big day.
In the next lesson, we'll show you a framework for working through these open-ended questions. You have a lot of freedom to adjust the framework to suit you, but we strongly recommend sticking to some sort of framework as it's easy to get off track.
How will I be assessed?
The business of technology is complex. Every problem is custom and every organization wants to accomplish the most with the least; minimizing waste and error and maximizing output and performance. To stay competitive in this environment, employers are looking for self-starting problem solvers who can anticipate obstacles and choose the best options at every turn. But how do you know what's best? The first step is understanding the landscape. To understand the problem space, you need to do two things:
- Basic knowledge of the fundamentals of good software design. That is, efficiency in terms of reliability, scalability, maintainability, and cost.
- Communication skills that allow you to scope out the problem, collect feature and non-feature requirements, justify your choices, and pivot when necessary.
Let's take a look at how this maps to a sample FAANG company interview rubric.
This rubric is mostly applicable for junior or mid-level engineers. The expectations for an advanced candidate will be higher, especially around identifying bottlenecks, discussing tradeoffs, and mitigating risk.
Bad Answer (No Hire)
- The candidate wasn't able to take the lead in the discussion.
- The candidate didn't ask clarifying questions and/or failed to outline requirements before beginning the design.
- The candidate failed to grasp the problem statement even after hints.
- The candidate missed critical components of the architecture, and/or couldn't speak to the relationship between components.
- Design flow was vague and unclear and the candidate couldn't give a detailed explanation even after hints.
- The design failed to meet specs.
- The candidate failed to discuss tradeoffs and couldn't justify decisions.
Fair Answer (On-the-Fence Hire)
- The candidate attempted to take the lead but needed significant guidance/hints to stay on track, or didn't interact much with their interviewer.
- The candidate defined some features, but the user journey/use case narrative was vague or incomplete.
- During requirements definition, important features were left out (but were hit upon later), or the candidate had to be given a few hints before a fair set of features was defined.
- The candidate identified most of the core components and understood the general connection between them (possibly with a hint or two.)
- The architecture may have had some issues but the candidate addressed them when they were pointed out, or the design flow, in general, could be improved.
- The candidate identified bottlenecks, but had trouble discussing tradeoffs and missed important risks.
Great Answer (Hire/Strong Hire)
- The candidate took the lead immediately and "checked in" regularly.
- If/when the interviewer asked to dive deeper into one or more areas, the candidate switched gears gracefully.
- The candidate identified appropriate, realistic non-functional requirements (e.g. business considerations like cost, serviceability) as well as functional requirements, and used both to define design constraints and guide decision-making.
- The high-level design was complete, component relationships were explained, and appropriate alternatives were discussed given realistic shifts in priorities.
- Bottlenecks were identified, alternatives were offered, and a quick summary of the pros and cons of each was given. Notice how there is both a knowledge and a communication component to each. For example:
- A candidate who creates a reasonable architecture but who rushes through a design likely be an on-the-fence candidate.
- A candidate who fails to take the lead on the discussion will likely be a no-hire.
- Consistently — great answers are both technically complete and are communicated well, with tradeoffs and bottlenecks identified and continuously tied back to requirements defined early on.
As you can imagine, arriving at great system designs in an interview scenario takes a lot of practice. It also takes a structured approach. We'll walk you through a framework in the next lesson.
3 - How to answer system design questions
What's the purpose of the system design interview?
The system design interview evaluates your ability to design a system or architecture to solve a complex problem in a semi-real-world setting.
It doesn't aim to test your ability to create a 100% perfect solution; instead, the interview assesses your ability to:
- Design the blueprint of the architecture
- Analyze a complex problem
- Discuss multiple solutions
- Weigh the pros and cons to reach a workable solution
This interview and the manager or behavioral interview are often used to determine the level at which you will be hired.
This lesson focuses on the framework for the system design interview.
Why use a system design interview framework?
Unlike a coding interview, a system design interview usually involves open-ended design problems.
If it takes a team of engineers years to build a solution to a problem, how can one design a complicated system within 45 minutes?
We need to allocate our time wisely and focus on the essential aspects of the design under tight time pressure. We must define the proper scope by clarifying the use cases.
An experienced candidate would not only show how they envision the design at a higher level but also demonstrate the ability to dive deep to address realistic constraints and tricky operational scenarios.
We also aim to maintain a clear communication style so that our interviewers understand why we want to spend time in certain areas and have a clear picture of our path forward.
Establishing a system design interview framework helps us:
- Better manage our time
- Reinforce our communication with the interviewer
- Lead the discussion toward a productive outcome
Once you're familiar with the framework, you can apply it every time you encounter a system design interview.
Anatomy of a system design interview
A system design interview typically consists of 5 steps:
- Step 1: Define the problem space. Here, we understand the problem and define the scope of the design.
- Step 2: Design the system at a high level. We lay out the most fundamental pieces of the system and illustrate how they work together to achieve the desired functionality.
- Step 3: Deep dive into the design. Either you or your interviewer will pick an interesting component, and you will discuss its details.
- Step 4: Identify bottlenecks and scaling opportunities. Think about the current design's bottlenecks and how we can change the design to mitigate them and support more users.
- Step 5: Review and wrap up. Check that the design satisfies all the requirements and potentially identify directions for further improvement.
A typical system design interview lasts about 45 minutes. A good interviewer leaves a few minutes in the beginning for self-introductions and a couple of minutes at the end for you to ask questions.
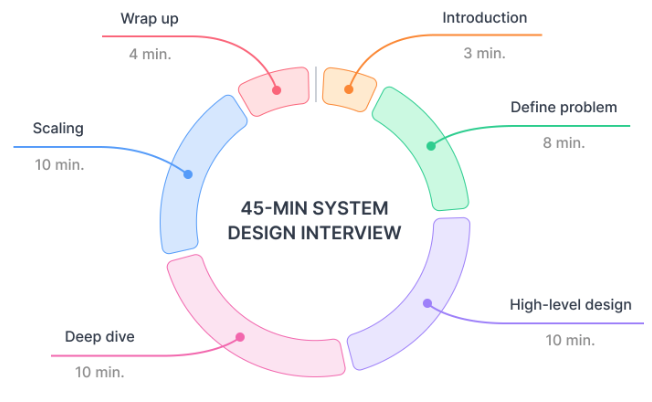
Therefore, we usually only have about 45 minutes for technical discussion. Here's an example of how we can allocate the time for each of the steps:
- Step 1: 8 minutes
- Step 2: 10 minutes
- Step 3: 10 minutes
- Step 4: 10 minutes
- Step 5: 4 minutes
The time estimate provided is approximate, so feel free to adjust it based on your interview style and the problem you're trying to solve. Integrating all the steps into a structured interview framework is important.
Step 1: Define your problem space
Time estimate: 8 minutes
It's common for issues to be unclear at this stage, so it's your job to ask lots of questions and discuss the problem space with your interviewer to understand all the system constraints.
One mistake to avoid is jumping into the design without first clarifying the problem.
It's important to capture both functional and non-functional requirements. What are the functional requirements of the system design? What's in and out of scope?
For instance, if you're designing a Twitter timeline, you should focus on tweet posting and timeline generation services instead of user registration or how to follow another user.
Also, consider whether you're creating the system from scratch. Who are our clients/consumers? Do we need to talk to pieces of the existing system?
Non-functional requirements
Once you've agreed with your interviewer on the functional requirements, think about the non-functional requirements of the system design. These might be linked to business objectives or user experience.
Non-functional requirements include: availability, consistency, speed, security, reliability, maintainability, cost.
- Availability
- Consistency
- Speed
- Security
- Reliability
- Maintainability
- Cost
Some questions you might ask your interviewer to understand non-functional requirements are:
- What scale is this system?
- How many users should our app support?
- How many requests should our server handle? A low query-per-second (QPS) number may mean a single-server design, while higher QPS numbers may require a distributed system with different database options.
- Are most use cases read-only? If so, that could suggest a caching layer to speed up reading.
- Do users typically read the data shortly after someone else overwrites it? That may indicate a strongly consistent system, and the CAP theorem may be a good topic to discuss.
- Are most of our users on mobile devices? If so, we must deal with unreliable networks and offline operations.
If you've identified many design constraints and feel that some are more important than others, focus on the most critical ones.
Make sure to explain your reasoning to your interviewer and check in with them. They may be interested in a particular aspect of your system, so listen to their hints if they nudge you in one direction.
Estimate the amount of data
You can do some quick calculations to estimate the amount of data you're dealing with.
For example, you can show your interviewer the queries per second (QPS) number, storage size, and bandwidth requirements. This helps you choose components and give you an idea of what scaling might look like later.
You can make some assumptions about user volume and typical user behavior, but check with your interviewer if these assumptions match their expectations.
Keep in mind that these estimates might not be exact, but they should be in the right range.
Step 2: Design your system at a high level
Time estimate: 10 minutes
Based on the constraints and features outlined in Step 1, explain how each piece of the system will work together.
Don't get into the details too soon, or you might run out of time or design something that doesn't work with the rest of the system.
You can start by designing APIs (Application Programming Interfaces), which are like a contract that defines how a client can access our system's resources or functionality using requests and responses. Think about how a client interacts with our system.
Maybe a client wants to create/delete resources, or maybe they want to read/update an existing resource.
Each requirement should translate to one or more APIs. You can choose what type of APIs you want to use Representational State Transfer, [REST], Simple Object Access Protocol [SOAP], Remote Procedure Call [RPC], or GraphQL, and explain why. You should also consider the request's parameters and the response type.
Once the APIs are established, they should not be easily changed and become the foundation of our system's architecture.
How will the web server and client communicate?
After designing the APIs, think about how the client and web server will communicate. Some popular choices are:
- Ajax Polling
- Long Polling
- WebSockets
- Server-Sent Events
Each has different communication directions and performance pros and cons, so make sure you discuss and explain your choice with your interviewer.
Create a high-level system design diagram
After designing the API and establishing a communication protocol, the next step is to create a high-level design diagram. The diagram should act as a blueprint of our design and highlight the most critical pieces to fulfill the functional requirements.
To illustrate the data and control flow in a system design question for a "Design Twitter" project, draw a high-level diagram. In this diagram, we've abstracted the design into an API server, several services we want to support, and the core databases.
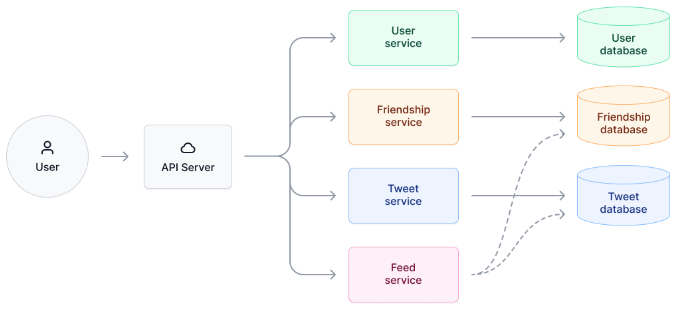
At this stage, we should not dive deep into the details of each service yet. Instead, we should review whether our design satisfies all the functional requirements. We should demonstrate to the interviewer how the data and control flow look in each functional requirement.
In the Twitter design example above, we might want to explain to our interviewer how the following flows work:
- How a Twitter user registers or logs in to their account
- How a Twitter user follows or unfollows another user
- How a Twitter user posts a tweet
- How a Twitter user gets their news feed
If the interviewer explicitly asks us to design one of the functionalities, we should omit the rest in the diagram and only focus on the service of interest.
We should be mindful not to dive into scaling topics such as database sharding, replications, and caching yet.
We should leave those to the scaling section.
Step 3: Deep-dive
Time estimate: 10 minutes
Once you have a high-level diagram, it's time to examine system components and relationships in more detail.
The interviewer may prompt you to focus on a particular area but don't rely on them to drive the conversation. Check in regularly with your interviewer to see if they have questions or concerns in a specific area.
How do your non-functional requirements impact your design?
Consider how non-functional requirements impact design choices.
For example, if our system requires transactions, consider using a database that provides the ACID (Atomicity, Consistency, isolation, and Durability) property.
If an online system requires fresh data, think about how to speed up the data ingestion, processing, and query process.
If the data size fits into memory (up to hundreds of GBs), consider putting the data into memory. However, RAM is prone to data loss, so if we can't afford to lose data, we must find a way to make it persistent.
If the amount of data we need to store is large, we might want to partition the database to balance storage and query traffic.
Remember to revisit the data access pattern, QPS number, and read/write ratio discussed in Step 1 and consider how they impact our choices for different databases, database schemas, and indexing options.
We might need to add some load balancer layers to distribute the read/write traffic.
Keep in mind that we are expected to present different design choices along with their pros and cons, and explain why we prefer one approach over the other.
Remember that the system design question usually has no unique "correct" answer.
Therefore, weighing the trade-offs between different choices to satisfy our system's functional and non-functional requirements is considered one of the most critical skill sets in a system design interview.
Step 4: Identify bottlenecks and scale
Time estimate: 10 minutes
After completing a deep dive into the system components, it's time to zoom out and consider if the system can operate under various conditions and has room to support further growth.
Some important topics to consider during this step include:
- Is there a single point of failure? If so, how can we improve the robustness and enhance the system's availability?
- Is the data valuable enough to require replication? How important is it to keep all versions consistent if we replicate our data?
- Do we support a global service? If so, must we deploy multi-geo data centers to improve data locality?
- Are there any edge cases, such as peak time usage or hot users, that create a particular usage pattern that could deteriorate performance or even break the system?
- How do we scale the system to support 10 times more users? As we scale the system, we may want to upgrade each component or migrate to another architecture gradually.
Concepts such as horizontal sharding, CDN (content delivery network), caching, rate-limiting, and SQL/NoSQL databases should be considered in the follow-up lessons.
Step 5: Wrap up
Time estimate: 4 minutes
This is the end of the interview where you can summarize: review requirements, justify decisions, suggest alternatives, and answer questions. Walk through your major decisions, providing justification for each and discussing any tradeoffs in terms of space, time, and complexity.
Throughout the discussion, we recommend to refer back to requirements periodically.
4 - System design principles
Purpose of System Design
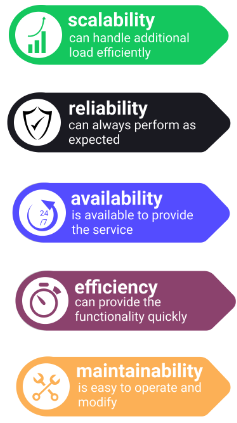
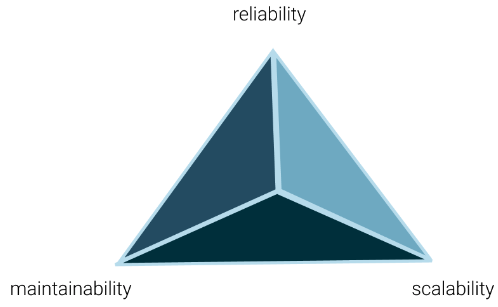
How do we architect a system that supports the functionality and requirements of a system in the best way possible? The system can be "best" across several different dimensions in system-level design. These dimensions include:
- Scalability: a system is scalable if it is designed so that it can handle additional load and will still operate efficiently.
- Reliability: a system is reliable if it can perform the function as expected, it can tolerate user mistakes, is good enough for the required use case, and it also prevents unauthorized access or abuse.
- Availability: a system is available if it is able to perform its functionality (uptime/total time). Note reliability and availability are related but not the same. Reliability implies availability but availability does not imply reliability.
- Efficiency: a system is efficient if it is able to perform its functionality quickly. Latency, response time and bandwidth are all relevant metrics to measuring system efficiency.
- Maintainability: a system is maintainable if it easy to make operate smoothly, simple for new engineers to understand, and easy to modify for unanticipated use cases.
What do these things mean in the context of system-level design? Let's take a look at a simple example of a distributed system to see what we mean.
Simple Distributed System Example
Let us consider a simple write system. The web service is designed to allow users to write and save information, and get an associated URL with the associated text that they have written (like PasteBin).

- Scalable. The use of load-balancers and caches and the choice of databases (object storage S3 and noSQL) will help facilitate additional load on the system from additional users.
- Reliable. The system will be able to reliably handle the functionality (i.e. where some number of clients are able to write text and get an associated URL with the text they have written) and by how the APIs are defined (not shown), should be able to handle user mistakes.
- Efficient. The introduction of the caching allows for greater efficiency for read requests by the user. The load-balancing also distributes the load more evenly across servers to make the system more efficient.
- Available. The load-balancers are distributing the load across multiple servers, meaning there is less likelihood of failure that will cause the system to crash. Additional databases can be used for redundancy in the case of error or failures.
- Maintainability. The APIs (not pictured here) are designed in a way that allows for modularity (i.e. separation of read and write calls). This allows for easy maintainability of the system.
You should always have the above distributed system properties (scalability, reliability, efficiency, availability and maintainability) in the back of your mind as you walk through each of the steps in the system-design interviews!
System Design Toolbox
There are so many components, algorithms, and architectures that support optimality in the above dimensions of distributed system design.
You will quickly find that each element in the system design toolbox may be great with respect to one dimension but at the cost of being low-performing in another (i.e. a component might be extremely efficient but not as reliable, or a certain design choice might be really effective at supporting one functionality like providing read access but not as efficient with write access).
In other words, there are tradeoffs that you must consider as you make informed system design choices. The best way to understand these tradeoffs is to understand how each of these components, algorithms and architectural designs work. In particular it is helpful to know how each element (tool):
- Works independently.
- Compares to other tools that perform similarly.
- Fits together in the bigger picture of system-level design.
5 - How to answer web protocol questions
How do networked computers actually talk to each other? Distributed systems would be completely impossible without the networks' physical infrastructure including client machines and servers, and rules and standards for sending and receiving data over that infrastructure. Those rules and standards are called network protocols.
Why are network protocols important?
It's easy to imagine the chaos that would ensue if communication between networked machines wasn't standardized. Network protocols have been around since the beginning, but the modern internet has converged on two models to describe how systems interact.
Two models for networked computer systems
The easiest way to think of the following networking models is as a stack of layers (hence the term "tech stack."). Generally, lower layers package data according to certain protocols which transmit upward where it is received as input by the next layer. This happens again and again until the data reaches its intended destination.
Data is transferred first through physical means like ethernet, then between computers through IP networks, and finally from user to user via the internet over the top, or "application" layer.
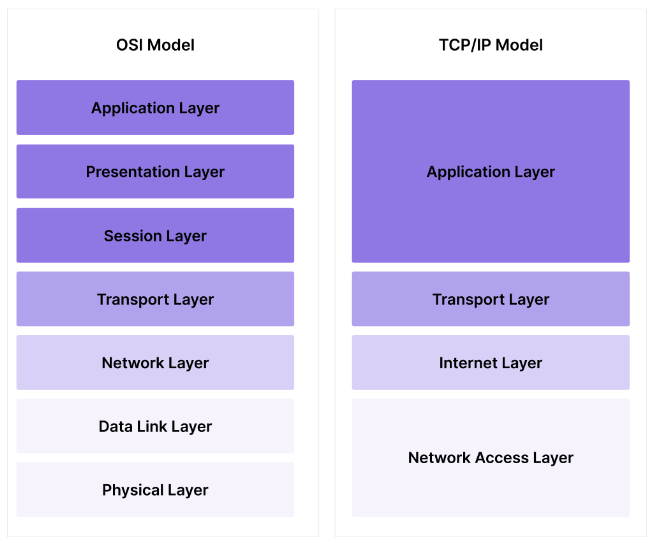
There are two models to be aware of. The TCP/IP model which maps more directly to protocols, and the more conceptual 7-layer OSI model.
TCP/IP Model
The TCP/IP model, named after its two main protocols which we will describe in more detail below, has four layers, starting with the base:
- The Network Access Layer or Link Layer, which represents a local network of machines; the "hardware" layer.
- The Internet Layer, which describes the much larger network of devices interconnected by IP addresses according to IP protocols (IPv4 or IPv6.)
- The Transport Layer which includes protocols for sending and receiving data via packets, e.g. TCP and UDP.
- The Application Layer, which describes how data is sent to and from users over the internet, e.g. HTTP and HTTPS.
OSI Model
The OSI Model or Open Systems Interface model is useful at a conceptual level. It's protocol-agnostic and more detailed. Instead of 4 layers, it breaks the Link Layer and Application Layer of the TCP/IP model into a few more pieces.
TCP (Transmission Control Protocol) and IP (Internet Protocol)
TCP/IP is the most commonly used protocol suite used today. It includes both the IP (via the internet layer) and TCP (via the transport layer) protocols. How does it work? Data packets are transmitted across network nodes. The Internet Layer connects these nodes through IP addresses and TCP protocol operating the transport Layer provides flow-control, establishes connections, and reliable transmission. TCP is a necessary "intermediary" because data packets sent over IP are often lost, dropped, or arrive out-of-order. TCP protocol was built with an emphasis on accuracy, so it's best used in applications where accuracy is more important than speed of delivery.
IPv4 vs. IPv6: You may have come across two different IP protocols — version 4 and version 6. IPv4 addresses include 4 numbers from 0 to 255 separated by periods. This standard was created in the 1980s when the number of available addresses, over 4 billion, seemed like plenty. Obviously, this isn't the case today. IPv6 allows for effectively unlimited IP addresses and includes useful new features (like the ability to stay connected to multiple networks at the same time) and better security, but the two protocols coexist today.
UDP (User Datagram Protocol)
UDP is a simpler alternative to TCP that also works with the IP protocol to transmit data. It's connectionless, making it much faster than TCP, but because it has none of the error-handling capabilities of TCP, it's error-prone. UDP is mainly used for streaming applications such as Skype, where users accept occasional delays in exchange for real-time service.
Together, TCP and UDP make up most internet traffic at the Transport Layer.
TCP vs. UDP
TCP emphasizes accurate delivery rather than speed and enforces the "rules of the road", similar to a traffic cop. How? It's connection-oriented, which means that the server must be "listening" for connection requests from clients, and the client and server must be connected before any data is sent. Because it's a stateful protocol, context is embedded into the TCP segment ("packaged" segments of the data stream including a TCP header), meaning that TCP can detect errors (either lost or out-of-order data packets) and request re-transmission.
HTTP and HTTPS
HTTP (Hypertext Transport Protocol) is the original request-response application layer protocol designed to connect web traffic through hyperlinks. It's the main protocol used by everything connected to the Internet. HTTP defines:
- A set of request methods (GET, POST, PUT, etc. - the same methods RESTful APIs use)
- Addresses (known as URLs)
- Default TCP/IP ports (port 80 for HTTP, port 443 for HTTPS).
Every time you visit a site with a http:// link, your browser makes a HTTP GET request for that URL.
HTTP is still in use, but it's been largely replaced by HTTPS (Hypertext Transport Protocol Secure), which serves the same purpose but with much better security features. In 2014, Google announced that it would give HTTPS sites a bump in rankings. That, combined with the increasing need for encrypted data transmission, resulted in much of the web over migrating to HTTPS.
TLS Handshake Procedure
HTTPS works on top of TLS (Transport Layer Security) by default. TLS is a protocol used to encrypt communications in the transport layer, preventing unauthorized parties from listening in on communications. The process for initiating a secure session through TLS is called a TLS handshake. Here's what happens.
- The client requests to establish a secure connection with a server, usually by using port 443 which is reserved for TLS connections.
- The client and server agree to use a particular cipher suite (ciphers and hash functions.)
- The server submits a digital certificate which serves as proof of identity. Digital certificates are issued by 3rd party Certificate Authorities (CAs) and effectively vouch for the server.
- If the certificate is accepted by the client, the client will generate a session key which is used to encrypt any information transmitted during the session.
Once the session key is created, the handshake is finished and the session begins. All data transmitted will now be encrypted.
WebSocket vs HTTP
WebSocket is a newer communications protocol designed as an alternative which helps solve some key issues. HTTP was designed to be strictly unidirectional; the client must always request data from the server, and only one HTTP request can be sent per session. Lots of modern applications require longer session times and/or continuous updates from the server. Long-polling, a technique that keeps client-server connections open longer, helps, but it doesn't solve the problem — and it's very resource-intensive.
The WebSocket protocol works similarly to HTTP, but with some improvements (and tradeoffs.) It allows servers to send data to clients in a standardized way without first receiving a request, and it allows for multiple messages to be passed back and forth over the same connection. It's fully compatible with HTTP (and HTTPS), and it's much less computationally demanding than polling.
There are some drawbacks to WebSocket as compared to HTTP, namely:
- WebSocket has no built-in, standardized API semantics like HTTP's status codes or request methods.
- Keeping communications open between each client and server is more resource-intensive and adds complexity.
- It's less widespread, so development can take longer.
Most WebSocket use cases require real-time data. In a system design interview, consider WebSocket vs. HTTP for applications where updates are frequent, and up-to-date information is critical. Think messaging services, gaming, and trading platforms.
When to bring this up in an interview
Web protocols might not be an area you're likely to deep-dive or discuss explicitly in your interview, but having a thorough understanding of the architecture underpinning the internet will be extremely helpful in designing anything built to transmit data over the web. If you are asked specific follow-ups, remember:
- At the transport layer, you're likely to choose either the TCP or UDP protocol to send data. Choose TCP if you're more concerned with data accuracy, and UDP if quick transmission is needed (with tolerance for some errors — like in a video streaming application.)
- At the application layer, you have some choices to make as well. You'll probably choose HTTPS over HTTP for security reasons. If you need to maintain open client-server communications (for example, if you're building a fast-paced two-player game and you need to maintain up-to-date scores) you may choose WebSocket over HTTP.
- If you're designing a service with an API, consider HTTP (HTTPS) over WebSocket as you'll be able to make use of HTTPs standardized request methods and status codes; important if you're designing a RESTful API.
Further reading
- Check out this article on Slack's engineering blog to learn about how Websockets works at scale within Slack.
- Google's security blog has covered the migration from HTTP to HTTPS migration from the beginning.
6 - How to cover load balancing
A load balancer is a type of server that distributes incoming web traffic across multiple backend servers. Load balancers are an important component of scalable Internet applications: they allow your application(s) to scale up or down with demand, achieve higher availability, and efficiently utilize server capacity.

Why we need load balancers
In order to understand why and how load balancers are used, it's important to remember a few concepts about distributed computing.
First, web applications are deployed and hosted on servers, which ultimately live on hardware machines with finite resources such as memory (RAM), processor (CPU), and network connections. As the traffic to an application increases, these resources can become limiting factors and prevent the machine from serving requests; this limit is known as the system's capacity. At first, some of these scaling problems can be solved by simply increasing the memory or CPU of the server or by using the available resources more efficiently, such as multithreading.
At a certain point, though, increased traffic will cause any application to exceed the capacity that a single server can provide. The only solution to this problem is to add more servers to the system, also known as horizontal scaling. When more than one server can be used to serve a request, it becomes necessary to decide which server to send the request to. That's where load balancers come into the picture.
How load balancers work
A good load balancer will efficiently distribute incoming traffic to maximize the system's capacity utilization and minimize the queueing time. Load balancers can distribute traffic using several different strategies:
- Round robin: Servers are assigned in a repeating sequence, so that the next server assigned is guaranteed to be the least recently used.
- Least connections: Assigns the server currently handling the fewest number of requests.
- Consistent hashing: Similar to database sharding, the server can be assigned consistently based on IP address or URL.
Since load balancers must handle the traffic for the entire server pool, they need to be efficient and highly available. Depending on the chosen strategy and performance requirements, load balancers can operate at higher or lower network layers (HTTP vs. TCP/IP) or even be implemented in hardware. Engineering teams typically don't implement their own load balancers and instead use an industry-standard reverse proxy (like HAProxy or Nginx) to perform load balancing and other functions such as SSL termination and health checks. Most cloud providers also offer out-of-the-box load balancers, such as Amazon's Elastic Load Balancer (ELB).
When to use a load balancer
You should use a load balancer whenever you think the system you're designing would benefit from increased capacity or redundancy. Often load balancers sit right between external traffic and the application servers. In a microservice architecture, it's common to use load balancers in front of each internal service so that every part of the system can be scaled independently.
Be aware, load balancing cannot solve many scaling problems in system design. For example, an application can also succumb to database performance, algorithmic complexity, and other types of resource contention. Adding more web servers won't compensate for inefficient calculations, slow database queries, or unreliable third-party APIs. In these cases, it may be necessary to design a system that can process tasks asynchronously, such as a job queue (see the Web Crawler question for an example).
Load balancing is notably distinct from rate limiting, which is when traffic is intentionally throttled or dropped in order to prevent abuse by a particular user or organization.
Advantages of Load Balancers
- Scalability. Load balancers make it easier to scale up and down with demand by adding or removing backend servers.
- Reliability. Load balancers provide redundancy and can minimize downtime by automatically detecting and replacing unhealthy servers.
- Performance. By distributing the workload evenly across servers, load balancers can improve the average response time.
Considerations
- Bottlenecks. As scale increases, load balancers can themselves become a bottleneck or single point of failure, so multiple load balancers must be used to guarantee availability. DNS round robin can be used to balance traffic across different load balancers.
- User sessions. The same user's requests can be served from different backends unless the load balancer is configured otherwise. This could be problematic for applications that rely on session data that isn't shared across servers.
- Longer deploys. Deploying new server versions can take longer and require more machines since the load balancer needs to roll over traffic to the new servers and drain requests from the old machines.
7 - How to answer questions about CDNs
Problem Background
When a client sends a request to an external server, that request often has to hop through many different routers before it can finally reach its destination (and then the response has to hop through many routers back). The number of these hops typically increases with the geographic distance between the client and the server, as well as the latency of the request. If a company hosting a website on a server, in an AWS datacenter in California (us-west-1), it may take ~100 ms to load for users in the US, but take 3-4 seconds to load for users in China. The good thing is that there are strategies to minimize this request latency for geographically far away users, and we should think about them when designing/building systems on a global scale.
What are CDNs?
CDNs (Content Distribution/Delivery Networks) are a modern and popular solution for minimizing request latency when fetching static assets from a server. An ideal CDN is composed of a group of servers that are spread out globally, such that no matter how far away a user is from your server (also called an origin server), they'll always be close to a CDN server. Then, instead of having to fetch static assets (images, videos, HTML/CSS/Javascript) from the origin server, users can fetch cached copies of these files from the CDN more quickly.
Note: Static assets can be pretty large in size (think of an HD wallpaper image), so by fetching that file from a nearby CDN server, we actually end up saving a lot of network bandwidth too.
Popular CDNs
Cloud providers typically offer their own CDN solutions, since it's so popular and easy to integrate with their other service offerings. Some popular CDNs include Cloudflare CDN, AWS Cloudfront, GCP Cloud CDN, Azure CDN, and Oracle CDN.
How do CDNs Work?
Like mentioned above, a CDN can be thought of as a globally distributed group of servers that cache static assets for your origin server. Every CDN server has its own local cache and they should all be in sync. There are two primary ways for a CDN cache to be populated, which creates the distinction between Push and Pull CDNs. In a Push CDN, it's the responsibility of the engineers to push new/updated files to the CDN, which would then propagate them to all of the CDN server caches. In a Pull CDN, the server cache is lazily updated: when a user sends a static asset request to the CDN server and it doesn't have it, it'll fetch the asset from the origin server, populate its cache with the asset, and then send the asset to the user.
Push CDN
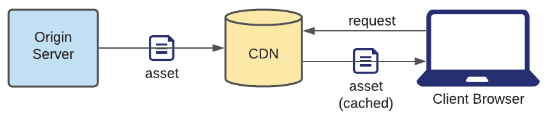
The origin server sends the asset to the CDN, which stores it in its cache. The CDN never makes any requests to the origin server.
Pull CDN
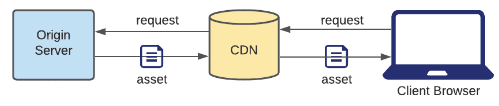
If the CDN doesn't have the static asset in its cache, then it forwards the request to the origin server and then caches the new asset.
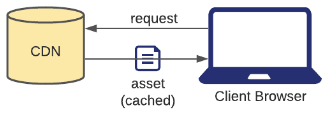
If the CDN has the asset in its cache, it returns the cached asset.
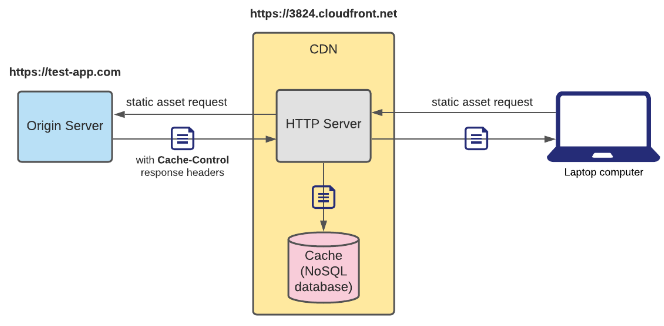
There are advantages and disadvantages to both approaches. In a Push CDN, it's more engineering work for the developers to make sure that CDN assets are up to date. Whenever an asset is updated/created, developers have to make sure to push it to the CDN, otherwise the client won't be able to fetch it. On the other hand, Pull CDNs require less maintenance, since the CDN will automatically fetch assets from the origin server that are not in its cache. The downside of Pull CDNs is that if they already have your asset cached, they won't know if you decide to update it or not, and to fetch this updated asset. So for some period of time, a Pull CDN's cache will become stale after assets are updated on the origin server. Another downside is that the first request to a Pull CDN will always take a while since it has to make a trip to the origin server.
Even with its disadvantages, Pull CDNs are still a lot more popular than Push CDNs, because they are much easier to maintain. There are also several ways to reduce the time that a static asset is stale for. Pull CDNs usually attach a timestamp to an asset when cached, and typically only cache the asset for up to 24 hours by default. If a user makes a request for an asset that's expired in the CDN cache, the CDN will re-fetch the asset from the origin server, and get an updated asset if there is one. Pull CDNs also usually support Cache-Control response headers, which offers more flexibility with regards to caching policy, so that cached assets can be re-fetched every five minutes, whenever there's a new release version, etc. Another solution is "cache busting", where you cache assets with a hash or etag that is unique compared to previous asset versions.
If a user is fetching the static asset image.png, they would fetch it at https://3284.cloudfront.net/image.png. If the CDN doesn't have it, then the CDN would fetch the asset from the origin server at https://test-app.com/image.png.
When not to use CDNs?
CDNs are generally a good service to add your system for reducing request latency (note, this is only for static files and not most API requests). However, there are some situations where you do not want to use CDNs. If your service's target users are in a specific region, then there won't be any benefit of using a CDN, as you can just host your origin servers there instead. CDNs are also not a good idea if the assets being served are dynamic and sensitive. You don't want to serve stale data for sensitive situations, such as when working with financial/government services.
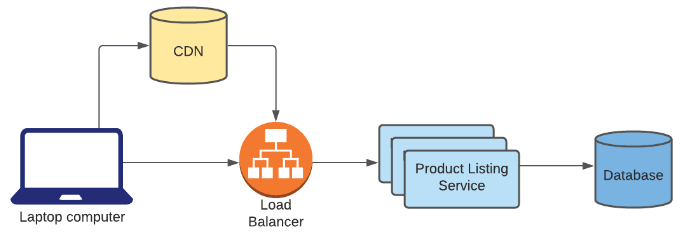
Exercise You're building Amazon's product listing service, which serves a collection of product metadata and images to online shoppers' browsers. Where would a CDN fit in the following design?

Answer
8 - APIs
An Application Programming Interface (API) is a way for different systems to talk to each other.
It's like a contract that says how one system can use another system's resources or functionality by sending requests and receiving responses.
A web API is a type of API that works between web servers and web browsers and typically uses a Hypertext Transfer Protocol (HTTP) to send and receive data.
Why do we need APIs?
Imagine that you own an international flight booking management company that maintains several databases, including flight information, ticket inventory, and ticket prices.
In a world without APIs, you would need to develop an application that allows individual customers and travel agencies to check flight availability and book tickets within your application.
However, developing such an application might be expensive and challenging to maintain globally. Furthermore, customers in many parts of the world might not even have access to your application.
Now, consider the world with the assistance of APIs to perform this business logic.
There are several benefits:
- Travel agencies can access provided APIs to aggregate data for their use, such as adjusting commissions, sending price change alerts, and tracking ticket prices.
- The booking management company can change internal services without affecting clients if the API interface remains unchanged.
- Other third parties can use the available public APIs to develop their business logic, which could increase ticket sales and revenue.
- The booking management company has precise permission controls and authentication methods provided by API gateways and/or the API itself using tokens or encryption.
Generally, an API is a contract between developers detailing the service or library's functionality.
When a client sends a request in a particular format, the API defines how the server should respond.
API developers must consider carefully what public API they offer before releasing it:
- APIs for third-party developers — APIs allow third-party developers to build applications that can securely interact with your application with your permission. Without APIs, developers would have to deal with the entire infrastructure of a service every time they wanted to access it.
- APIs for users — As a user, APIs save you from dealing with all of that infrastructure.
This simplification creates business opportunities and innovative ideas; for example, a third-party tool that uses public APIs to access Google Maps data for advertising, recommendations, and more.
In summary, APIs provide access to a server's resources while maintaining security and permission control. They simplify software development by providing a layer of abstraction between the server and the client.
API design is essential to any system architecture and is a common topic in system design interviews.
How APIs work
APIs deliver client requests and return responses via JavaScript Object Notation (JSON) or Extensible Markup Language (XML), usually over the Internet (web APIs). Each request-and-response cycle is an API call.
A request typically consists of a server endpoint Uniform Resource Locator (URL) and a request method, usually through HTTP. The request method indicates the desired API action. An HTTP response contains a status code, a header, and a response body.
Common status codes include:
200(OK)401(unauthorized user)404(URL not found)500(internal server error)
The response body varies depending on the HTTP request, which could be the server resource a client needs to access or any application-specific messages.
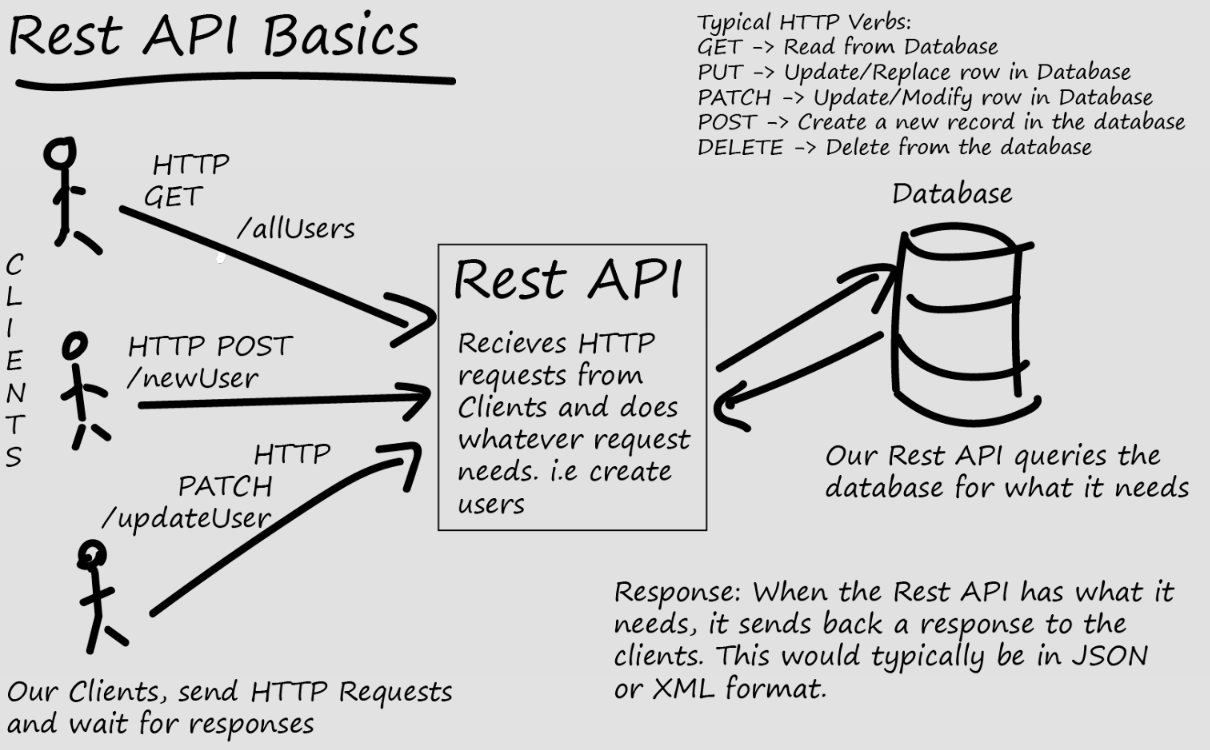
To streamline communication, APIs often converge on a few popular specifications to standardize information exchange. By far, the most common is REpresentational State Transfer (REST).
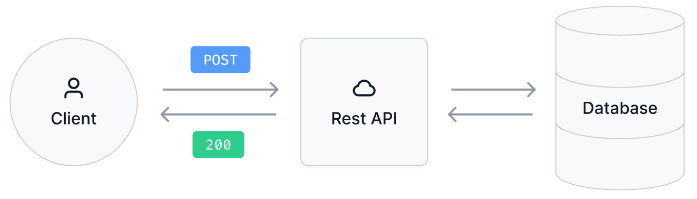
REST APIs
REpresentational State Transfer (REST) APIs focus on server resources and limit the set of methods to those based on HTTP methods that access resources.
The most common request methods are:
GET(to retrieve)POST(to create)PUT(to update)DELETE(to delete/remove)
REST APIs access resources through URLs, just like the URLs in your browser. The URLs are accompanied by a method that specifies how you want to interact with the resource.
REST APIs focus on resources rather than database entries. In many cases, these two are not identical.
For instance, creating a calendar event (a resource) can involve sending email invitations to attendees, creating events for each attendee, checking for conflicts, reserving meeting places, updating video conference schedules, and granting permissions to related documents.
A single calendar event might trigger updates from multiple services and databases.
Although REST APIs are among the most popular choices, a downside is that a client might have to deal with redundant data when making REST API calls.
For example, to fetch the name and members of a musical band, requesting the dedicated resources for that band would retrieve the name and its members (possibly from multiple endpoints) and also other information (such as its albums, founding year, and so on), depending on how the resources are organized by the server.
Learn more about REST API Basics:
Other popular APIs
Other than REST APIs, there are other popular APIs, such as Remote Procedure Call (RPC), GraphQL, and Simple Access Protocol (SOAP):
RPC
A requester selects a remote procedure to execute, serializes the parameters, and then sends the lightweight binary data to the server. The server decodes the message and executes the operation, sending the result back to the requester.
Its simplicity and light payloads have made it a de facto standard for many inter-service data exchanges on the backend.
GraphQL
GraphQL was developed to allow clients to execute precise queries and retrieve only the data they are interested in, typically from a graph database.
To achieve this process, servers need to predefine a schema that describes all possible queries and their return types. This reduces the server payload and offers the client a great amount of flexibility during query time.
However, performance can suffer when the client has too many nested fields in one request. Additionally, there is a steep learning curve that requires extensive knowledge.
Therefore, GraphQL users need to find a balance between its benefits and implementation costs.
SOAP
A precursor to REST. SOAP works like an envelope that contains a bulky, text-based message. It is much slower than binary messaging protocols, such as RPC.
However, the standardized text format and security features make enforcing legal contracts and authentication easy throughout the API's processing.
SOAP is a legacy protocol and is still heavily used in high-security data transmission scenarios, such as billing operations, booking, and payment systems.
API design patterns
When a Google search query returns thousands of URLs, how can we gracefully render the results to a client? API design patterns provide a set of design principles for building internal and public-facing APIs.
Pagination
One user experience design pattern uses pagination, where users can navigate between different search results pages using links, such as "next," "previous," and a list of page numbers.
How do we implement a search query API that supports pagination?
For simplicity, let's assume that Google stores the result of the queried word "Wikipedia" at "https://www.google.com/some_storage_path/wikipedia/*".
Our API request to fetch the search result for "Wikipedia" would look like this:
GET "[https://www.google.com/some_storage_path/wikipedia](https://www.google.com/storage/wikipedia/)?limit=20"
- The
limit=20parameter means that we only want to list the first 20 results on the first page. - If everything goes well, our API request receives a response with a
200OKstatus code and a response body containing the first 20 pages that match our search word "Wikipedia". - The response also contains a link to the next page that shows the following 20 available matching pages, and an empty link to the previous page.
- Then, we can send a second API request asking for the following 20 pages by specifying the offset of the search results.
Use the following GET request to retrieve the first page of results:
- The response body could contain the results for the first page, a valid link to the next page, and an empty previous page link. If we have exhausted all the result pages, the following page link will be empty.
- It is good design practice to add pagination from the start. Otherwise, a client that is unaware of the current
GETAPI that supports pagination could mistakenly believe they obtained the full result when in fact, they only obtained the very first page.
In addition to pagination as a solution to navigate between a list of pages, other design patterns include load more and infinite scrolling. Learn more about pagination vs. load more vs. infinite scrolling design patterns.
Long-running operations
When using the DELETE API, an appropriate return value depends on whether or not the DELETE method immediately removes the resource. If it does, the server should return an empty response body with an appropriate status code, such as 200 (OK) or 204 (No Content).
For example:
- If the object the client tries to delete is large and takes time to delete, the server can embed a long-running operation in the response body so that the client can later track the progress and receive the deletion result.
- When the
POSTAPI creates a large resource, the server could return a202status code forAcceptedand a response body indicating that the resource is not yet ready for use.
API Idempotency
A client may experience failures, such as timeouts, server crashes, or network interruptions, while trying to pay for a service. If the client retries the payment and is double-charged, it could be due to any of the following scenarios:
There are 3 potential scenarios when a payment request is made:
- The initial handshake between the client and server could fail, preventing the payment request from being sent. In this case, the client can retry the request and hope for success without risking double charging.
- The server receives the payment request but has not yet begun processing it when a failure occurs. The server sends an error code back to the client, and there is no change to the client's account.
- The server receives the payment request and successfully processes it or is processing it when a failure occurs. However, the failure happens before the server can return the
200status code to the client. In this scenario, the client may not realize that their account has already been charged and may initiate another payment, leading to double charging.
Overall, the first two scenarios are acceptable, but the last scenario is problematic and could result in unintentional double charging.
Possible solution
To address this problem, we need to develop an idempotent payment API. An idempotent API ensures that only the first call generates the expected result and subsequent calls are no-ops.
- Require clients to generate a unique key in the request header when initiating a request to the payment server.
- The key is sent to the server along with other payment-related information.
- The server stores the key and process status.
- If the client receives a failure, it can safely retry the request with the same key in the header, and the payment server can recognize this as a duplicate request and take appropriate action.
For example, if the previous failure interrupted an ongoing payment processing, the payment server might restore the state and continue processing.
Non-mutating APIs, such as GET, are generally idempotent.
Mutating APIs, such as PUT, update a resource's state. This means that executing the same PUT API multiple times updates the resource only once, while subsequent calls overwrite the resource with the same value. Therefore, PUT APIs are usually idempotent.
Similarly, the mutating API, DELETE, only takes effect during the first call, returning a 200 (OK) status, while subsequent calls return 404 (Not Found).
The last mutating API, POST, creates a new resource.
However, receiving multiple requests can cause servers to allocate different places for the new resource. Therefore, the POST API is usually not idempotent.
API gateways
Although APIs offer security to the systems on either end, they are susceptible to overuse or abuse. If you're concerned about this, you may want to implement an API gateway to collect requests and route them accordingly.
An API gateway is a reverse proxy that acts as a single entry point for microservices and back-end APIs.
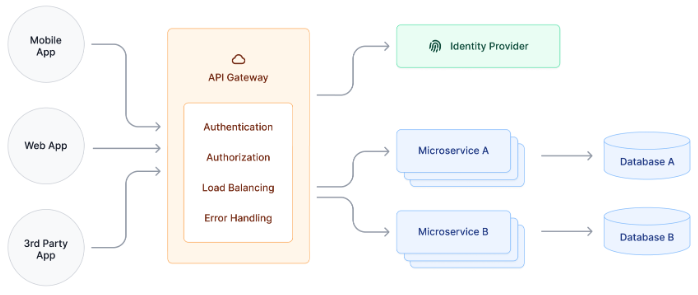
All client requests are routed to the gateway, which directs them accordingly — to the API if it is available, or redirected if the request fails to meet security standards.
Generally, use cases for API gateways include user authentication, rate limiting, and billing if you're monetizing an API.
Learn more
- Netflix's Engineering Blog: Engineering Trade-Offs and The Netflix API Re-Architecture and Beyond REST (learn about the engineering team's experiments with microservices over the years)
- REST API response codes and error messages (IBM)
- Pagination vs. infinite scrolling vs. load more: Best practices on Oracle Help Center (Oracle)
9 - Understanding CAP theorem
The CAP theorem is an important database concept to understand in system design interviews. It's often not explicitly asked about, but understanding the theorem helps us narrow down a type of database to use based on the problem requirements. Modern databases are usually distributed and have multiple nodes over a network. Since network failures are inevitable, it's important to decide beforehand the behavior of nodes in a database, in the event that packets are dropped/lagged or a node becomes unresponsive.
Partition Tolerance and Theorem Definition
CAP stands for "Consistency", "Availability", and "Partition tolerance". A network partition is a (temporary) network failure between nodes. Partition tolerance means being able to keep the nodes in a distributed database running even when there are network partitions. The theorem states that, in a distributed database, you can only ensure consistency or availability in the case of a network partition.
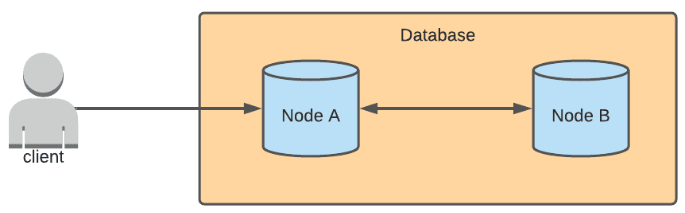
Example Scenario
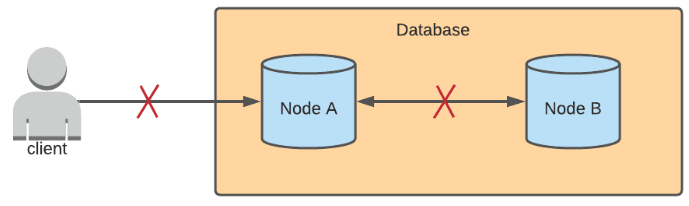
To better understand the situation with network partitions, we give an example scenario. In a multi-primary architecture, data can be written to multiple nodes. Let's pretend that there are two nodes in this example database. When a write is sent to Node A, Node A syncs the update with Node B, and any read requests sent to either of the two nodes will return the updated result.
If there is a network partition between Node A and Node B, then updates cannot be synced. Node B wouldn't know that Node A received an update, and Node A wouldn't know if Node B received an update. The behavior of either node after receiving a write request depends on whether the database prioritizes consistency or availability.
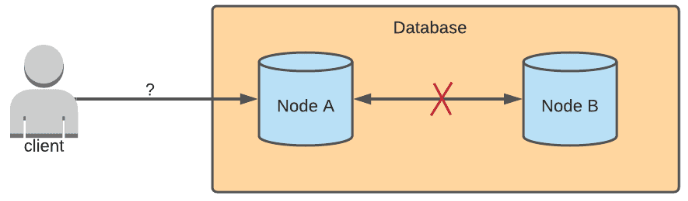
Consistency
Consistency is the property that after a write is sent to a database, all read requests sent to any node should return that updated data. In the example scenario where there is a network partition, both Node A and Node B would reject any write requests sent to them. This would ensure that the state of the data on the two nodes are the same. Or else, only Node A would have the updated data, and Node B would have stale data.
Availability
In a database that prioritizes availability, it's OK to have inconsistent data across the nodes, where one node may contain stale data and another has the most updated data. Availability means that we prioritize nodes to successfully complete requests sent to them. Available databases also tend to have eventual consistency, which means that after some undetermined amount of time when the network partition is resolved, eventually, all nodes will sync with each other to have the same, updated data. In this case, Node A will receive the update first, and after some time, Node B will be updated as well.
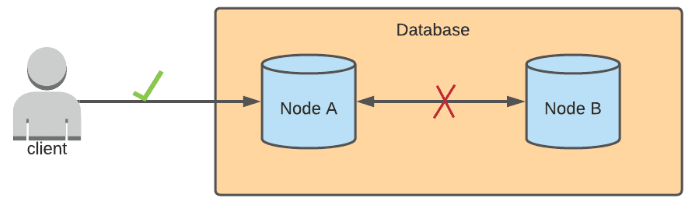
When should Consistency or Availability be prioritized?
If you're working with data that you know needs to be up-to-date, then it may be better to store it in a database that prioritizes consistency over availability. On the other hand, if it's fine that the queried data can be slightly out-of-date, then storing it in an available database may be the better choice. This may seem kind of vague, but check out the examples at the end of this post for a better understanding.
Read Requests
Notice that only write requests were discussed above. This is because read requests don't affect the state of the data, and don't require re-syncing between nodes. Read requests are typically fine during network partitions for both consistent and available databases.
SQL Databases
SQL databases like MySQL, PostgreSQL, Microsoft SQL Server, Oracle, etc, usually prioritize consistency. Primary-secondary replication is a common distributed architecture in SQL databases, and in the event of a primary becoming unavailable, the role of primary would failover to one of the replica nodes. During this failover process and electing a new primary node, the database cannot be written to, so that consistency is preserved.
Popular Databases that Prioritize Consistency vs. Availability
| Prioritize Consistency | Prioritize Availability |
|---|---|
| SQL databases | Cassandra |
| MongoDB | AWS DynamoDB |
| Redis | CouchDB |
| Google BigTable | |
| HBase |
Does Consistency in CAP mean Strong Consistency?
In a strongly consistent database, if data is written and then immediately read after, it should always return the updated data. The problem is that in a distributed system, network communication doesn’t happen instantly, since nodes/servers are physically separated from each other and transferring data takes >0 time. This is why it’s not possible to have a perfectly, strongly consistent distributed database. In the real world, when we talk about databases that prioritize consistency, we usually refer to databases that are eventually consistent, with a very short, unnoticeable lag time between nodes.
I’ve heard the CAP Theorem defined differently as "Choose 2 of the 3, Consistency, Availability or Partition Tolerance"?
This definition is incorrect. You can only choose a database to prioritize consistency or availability in the case of a network partition. You can’t choose to forfeit the "P" in CAP, because network partitions happen all the time in the real world. A database that is not partition tolerant would mean that it’s unresponsive during network failures, and could not be available either.
Short Exercises
Question 1: You’re building a product listing app, similar to Amazon’s, where shoppers can browse a catalog of products and purchase them if they’re in-stock. You want to make sure that products are actually in-stock, or then you’ll have to refund shoppers for unavailable items and they get really angry. Should the distributed database you choose to store product information prioritize consistency or availability?
Answer: Consistency. In the case of a network partition and nodes cannot sync with each other, you’d rather not allow any shoppers to purchase any products (and write to the database) than have two or more shoppers purchase the same product (write on different nodes) when there is only one item left. An available database would allow for the latter, and at least one of the shoppers would have to have their order canceled and refunded.
Question 2: You’re still building the same product listing app, but the PMs have decided, through much analysis, that it’s more cost effective to refund shoppers for unavailable items than to show that the products are out-of-stock during a network failure. Should the distributed database you choose still prioritize consistency or availability?
Answer: Availability. Canceling and refunding the order of a shopper would be preferable to not allowing any shoppers to purchase the product at all during a network failure.
10 - Caching strategies
Caching is a data storage technique that is ubiquitous throughout computer systems and plays an important role in designing scalable Internet applications. A cache is any data store that can store and retrieve data quickly for future use, enabling faster response times and decreasing load on other parts of your system.
Why We Need Caching
Without caching, computers and the Internet would be impossibly slow due to the access time of retrieving data at every step. Caches take advantage of a principle called locality to store data closer to where it is likely to be needed. This principle is at work even within your computer: as you browse the web, your web browser caches images and data temporarily on your hard drive; data from your hard drive is cached in memory, etc.
In large-scale Internet applications, caching can similarly make data retrieval more efficient by reducing repeated calculations, database queries, or requests to other services. This frees up resources to be used for other operations and serve more traffic volume. In a looser sense, caching can also refer to the storage of pre-computed data that would otherwise be difficult to serve on demand, like personalized newsfeeds or analytics reports.
How Caching Works
Caching can be implemented in many different ways in modern systems:
In-memory application cache. Storing data directly in the application's memory is a fast and simple option, but each server must maintain its own cache, which increases overall memory demands and cost of the system.
Distributed in-memory cache. A separate caching server such as Memcached or Redis can be used to store data so that multiple servers can read and write from the same cache.
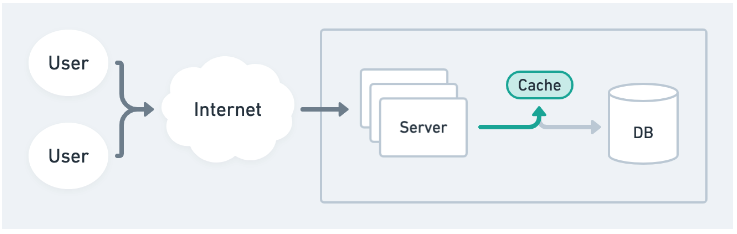
Database cache. A traditional database can still be used to cache commonly requested data or store the results of pre-computed operations for retrieval later.
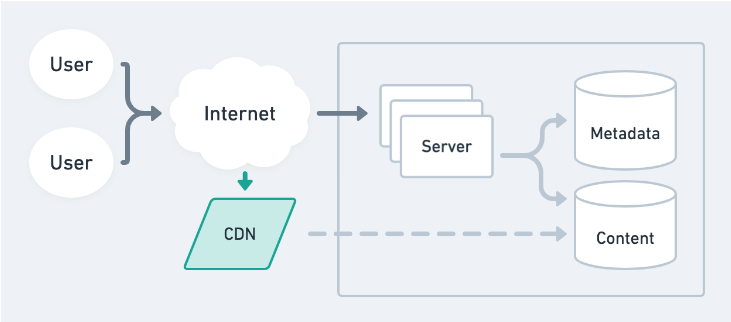
File system cache. A file system can also be used to store commonly accessed files; CDNs are one example of a distributed file system that take advantage of geographic locality.
Caching Policies
One question you may be wondering is, "If caching is so great, why not cache everything?"
There are two main reasons: cost and accuracy. Since caching is meant to be fast and temporary, it is often implemented with more expensive and less resilient hardware than other types of storage. For this reason, caches are typically smaller than the primary data storage system and must selectively choose which data to keep and which to remove (or evict). This selection process, known as a caching policy, helps the cache free up space for the most relevant data that will be needed in the future.
Here are some common examples of caching policies:
- First-in first-out (FIFO). Similar to a queue, this policy evicts whichever item was added longest ago and keeps the most recently added items.
- Least recently used (LRU). This policy keeps track of when items were last retrieved and evicts whichever item has not been accessed recently. See the related programming question.
- Least frequently used (LFU). This policy keeps track of how often items are retrieved and evicts whichever item is used least frequently, regardless of when it was last accessed.
In addition, caches can quickly become out-of-date from the true state of the system. This speed/accuracy tradeoff can be reduced by implementing an eviction policy — most commonly by limiting the time-to-live (TTL) of each cache entry, and updating the cache entry before or after database writes (write-through vs. write-behind).
Cache Coherence
One final consideration is how to ensure appropriate cache consistency given our requirements.
- A write-through cache updates the cache and main memory simultaneously, meaning there's no chance either can go out of data. It also simplifies the system.
- In a write-behind cache, memory updates occur asynchronously. This may lead to inconsistency, but it speeds things up significantly.
Another option is called cache-aside or lazy loading where data is loaded into the cache on-demand. First, the application checks the cache for requested data. If it's not there (also called a "cache miss") the application fetches the data from the data store and updates the cache. This simple strategy keeps the data stored in the cache relatively "relevant" - as long as you choose a cache eviction policy and limited TTL combination that matches data access patterns.
| Cache Policy | Pros | Cons |
|---|---|---|
| Write-through | Ensures consistency. A good option if your application requires more reads than writes. | Writes are slow. |
| Write-behind | Speed (both reads and writes.) | Risky. You're more susceptible to issues with consistency and you may lose data during a crash. |
| Cache-aside or Lazy Loading | Simplicity and reliability. Also, only requested data is cached. | Cache misses cause delays. May result in stale data. |
Further Reading
- In 2013, Facebook engineers published Scaling Memcache at Facebook, a now-famous paper detailing improvements to memcached. The concept of leases, a Facebook innovation addressing the speed/accuracy problem with caching, is introduced here.
- This blog series written by Stack Overflow's Chief Architect on the company's approach to caching (and many other architectural topics) is both informative and fun.
Concept Check
There are 3 big decisions you'll have to make when designing a cache.
- How big should the cache be?
- How should I evict cached data?
- Which expiration policy should I choose?
Summarize a few general data points you'd consider when making your decisions.
Full Solution
How big? At a high level, consider how latency reduction will impact your users vs. the added cost of increased complexity and expensive hardware. Then consider anticipated request volume and the size and distribution of cached objects. From there, design your cache such that it meets your cache hit rate targets.
Eviction? This will depend on your application, but LRU is by far the most common option. It's simple to implement and works best under most circumstances.
Expiration? A common, simple approach is to set an absolute TTL based on data usage patterns. Consider the impact of stale data on your users and how quickly data changes. You likely won't get this right the first time.
11 - SQL vs. NoSQL? How to choose a database
In system design interviews, you will often have to choose what database to use, and these databases are split into SQL and NoSQL types. SQL and NoSQL databases each have their own strengths (+) and weaknesses (-), and should be chosen appropriately based on the use case.
SQL Databases
- (+) Relationships SQL databases, also known as relational databases, allows easy querying on relationships between data among multiple tables. These relationships are defined using primary and foreign key columns. Table relationships are really important for effectively organizing and structuring a lot of different data. SQL, as a query language, is also both very powerful for fetching data and easy to learn.
- (+) Structured Data Data is structured using SQL schemas that define the columns and tables in a database. The data model and format of the data must be known before storing anything, which reduces room for potential error.
- (+) ACID Another benefit of SQL databases is that they are ACID (Atomicity, Consistency, Isolation, Durability) compliant, and they ensure that by supporting transactions. SQL transactions are groups of statements that are executed atomically. This means that they are either all executed, or not executed at all if any statement in the group fails. A simple example of a SQL transaction is written below:
BEGIN TRANSACTION transfer_money_1922;
UPDATE balances SET balance = balance - 25 WHERE account_id = 10;
UPDATE balances SET balance = balance + 25 WHERE account_id = 155;
COMMIT TRANSACTION;
$25 is being transferred from one account balance to another.
- (-) Structured Data Since columns and tables have to be created ahead of time, SQL databases take more time to set up compared to NoSQL databases. SQL databases are also not effective for storing and querying unstructured data (where the format is unknown).
- (-) Difficult to Scale Because of the relational nature of SQL databases, they are difficult to scale horizontally. For read-heavy systems, it’s straightforward to provision multiple read-only replicas (with leader-follower replication), but for write-heavy systems, the only option oftentimes is to vertically scale the database up, which is generally more expensive than provisioning additional servers.
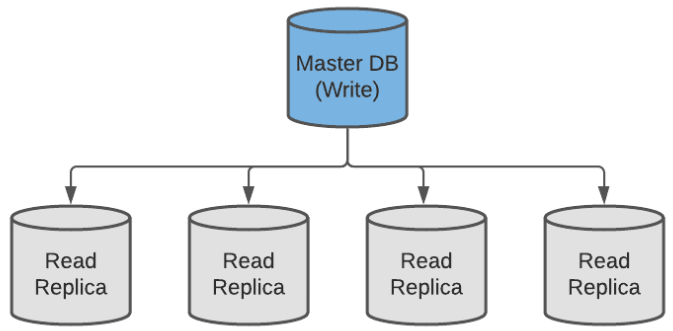
Leader-Follower Replication
Related Note 1: By increasing the number of read replicas, a trade-off is made between consistency and availability. Having more read servers leads to higher availability, but in turn, sacrifices data consistency (provided that the updates are asynchronous) since there is a higher chance of accessing stale data. This follows the CAP theorem, which will be discussed more as a separate topic. Related Note 2: It’s not impossible to horizontally scale write-heavy SQL databases, looking at Google Spanner and CockroachDB, but it’s a very challenging problem and makes for a highly complex database architecture. Examples of Popular SQL databases: MySQL, PostgreSQL, Microsoft SQL Server, Oracle, CockroachDB.
NoSQL Databases
- (+) Unstructured Data NoSQL databases do not support table relationships, and data is usually stored in documents or as key-value pairs. This means that NoSQL databases are more flexible, simpler to set up and a better choice for storing unstructured data.
- (+) Horizontal Scaling Without table relationships, data in NoSQL databases can be sharded across different data stores, allowing for distributed databases. This makes horizontal scaling much easier, and very large amounts of data can be stored without having to purchase a single, expensive server. NoSQL databases can flexibly support both read-heavy and write-heavy systems. With data spread out across multiple shards/servers, hashing and consistent hashing are very important techniques for determining which shard(s) to route application queries to.
MongoDB uses a query router, which is a reverse proxy that accepts a query and routes it to the appropriate shard(s). The router then sends the query response back to the calling application. Note that the query router is very similar to a load balancer.
(-) Eventual Consistency NoSQL databases are typically designed for distributed use cases, and write-heavy systems can be supported by having multiple write shards for the same data partition (called peer-to-peer replication). However, the tradeoff is a loss of strong consistency. After a write to a shard in a distributed NoSQL cluster, there’ll be a small delay before that update can be propagated to other replicas. During this time, reading from a replica can result in accessing stale data. This weakness of the data eventually being up-to-date, a.k.a eventual consistency, was actually seen earlier with leader-follower replication (which can be used for SQL or NoSQL). Eventual consistency isn’t exactly a fault of NoSQL databases, but distributed databases in general. A single shard NoSQL database can be strongly consistent, but to fully take advantage of the scalability benefits of NoSQL, the database should be set up as a distributed cluster.
Examples of Popular NoSQL Databases: MongoDB, Redis, DynamoDB, Cassandra, CouchDB
Short Exercises
Question 1 The goal is to build a service for tens of millions of Amazon shoppers, which will store each shopper’s past 100 viewed products. The stored data is shopper specific, and should be used for targeted product advertisements towards that shopper. It’s fine if this data is a little out-of-date. What kind of database should be used? Hint: The last sentence mentions it’s fine if the data is a bit stale. Hint 2: There is a lot of data that needs to be stored.
Solution: NoSQL
Question 2
A company has been experiencing some scaling pains as the engineering team has been building a lot of new microservices and many of them make read requests to the main SQL database regarding customer metrics. The goal is to build a cache service that sits in front of the database to offload some of these read queries. This cache service should look up the query and if it hasn’t been cached in the last 10 minutes, then query the database for the result and cache it. Else, the cache service just gets the result from the cache without querying the main database. What kind of database should be used to build the cache? Hint: This database should be able to look up the cached result by the SQL query (string). Hint 2: The stored data is non-relational.
Solution: NoSQL
Question 3
The goal is to build a service at PayPal that can allow users to apply for loans through the app. The service needs a database to store loan applications. In addition to the loan amount, the application also needs information regarding the user’s current balance and prior transaction history. What kind of database should be used? Hint: This is a financial application where data consistency is very important. Hint 2: Data about the loan, user’s balance and transaction history all need to be stored, and there’s relationships between these data.
Solution: SQL
12 - Replication strategies
Database replication is basically what you think it is: copying data from one data source to another, thus replicating it in one or more places. There are many reasons for copying data - to protect against data loss during system failures, to serve increased traffic, to improve latency when pursuing a regional strategy, etc. We'll cover some more specific use cases below. There are several strategies you should be aware of.
This lesson specifically covers replication strategies for databases, but replication is viable for other data sources like caches, app servers, and object/file storage. Amazon S3 or Google Cloud Storage are good examples.
Why replication matters
Replication is a natural complement to modern distributed systems. With data spread out across multiple nodes and the notorious unreliability of networks (review the CAP theorem lesson for details), it's obvious that storing data in multiple places to prevent data loss is a good idea.
You can also think of replication as a proactive strategy to help applications scale. With data replicated across multiple nodes, latency decreases, performance increases, and users have a consistent experience regardless of their location and system load.
How does it work?
Replication is simple if data doesn't change much. However, that's not the case with most modern systems. How do write requests cascade across multiple, identical databases with any consistency, let alone timeliness? There are a few strategies you can choose from, though, as always, there are tradeoffs for each.
Probably the most common strategy is leader-follower (or primary-replica), where a query writes to a single designated leader. The leader then replicates the updated data to followers.
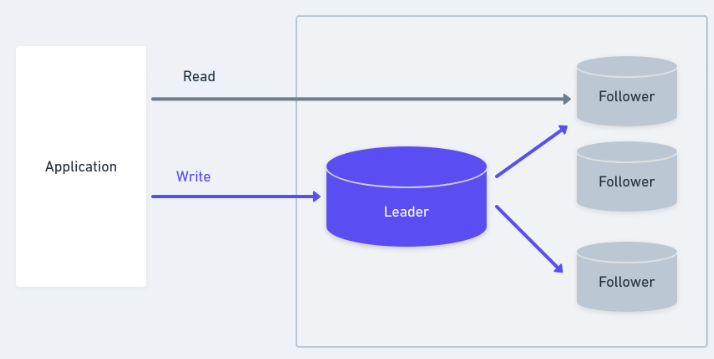
What's the problem? This can be slow, if done synchronously.
Synchronous replication requires that both the leader and followers must commit before the write is considered successful. While this ensures follower data is up-to-date, the real-world implications can be tricky or even unacceptable. If a follower in the chain goes down, the write query will fail, and even if the whole system is up, waiting for a follower located halfway across the world will raise latency considerably.
Asynchronous replication may be an option for use cases where transaction speed is more important than consistently accurate data. With asynchronous replication, the leader sends writes to its followers and moves on without waiting for acknowledgment. Faster, yes, but this introduces inconsistency between the leader and followers, which can be a huge problem if the leader goes down and the most up-to-date data is lost.
Make no mistake — leader failures will happen. In the case of a simple leader-follower strategy when the leader fails (also called a failover), the replica is promoted to be the leader and takes over.
Failover is a huge problem under asynchronous replication, but it's not great under synchronous either. Without a leader, you lose the ability to handle writes. It's absolutely critical to talk through leader failure in your system design interview. Luckily, there are a few tweaks to the base leader-follower framework that can help.
Leader failures and consensus algorithms
A simple way to mitigate leader failure is to designate more than one leader. Leader-leader or multi-leader replication simply means that more than one database is available to take writes, meaning, if one leader goes down, the other can step in. This does introduce a slight lag as data must be replicated to both (or more) leaders and engineers must contend with more complexity — mainly conflict resolution when discrepancies arise between leaders — but the added durability mostly outweighs the additional lag time in the real world.
Consensus algorithms can be used to "elect" a new leader if one of more leaders goes down, adding another layer of protection to the system. The most common consensus algorithm is Paxos. Many consider it a difficult algorithm to understand, perhaps because the leader election process is part of a larger process which aims to reach agreement through data replication.
Trivia: Google, which uses Paxos as the foundation of Spanner, its scalable-yet-synchronously-replicated distributed database, published a paper on its struggles to create a fault-tolerant system based on Paxos.
A newer alternative to Paxos called Raft effectively breaks the agreement process into two steps, thereby making leader election easier to understand.
Leaderless replication
Why maintain the leader-follower hierarchy at all if leader election and conflict resolution are so painful? Amazon's DynamoDB re-popularized the idea of leaderless replication, and now most cloud providers include something similar.
...If you hear nothing but "anarchy" when someone mentions leaderless replication, you wouldn't be alone. However, there are some clever methods for dealing with the chaos that comes with managing a network of read-AND-write-capable replicas.
- Read repair allows clients to detect errors (e.g. several nodes return a consistent value, but one node returns something else) and fix them by sending a write request to the inconsistent node.
- Background processes that fix errors exist in many cloud-based products. For example, Amazon's DynamoDB uses an "anti-entropy" function. Read more below.
- Quorums allow replicas to pull up-to-date information quickly in asynchronous leaderless replication by specifying a minimum number of replicas that need to accept a write before reading.
When to implement a replication strategy
There are so many reasons to include replicas and so many strategies to choose from, we generally recommend including replicas in anything more than the most basic server-database system. The key is choosing the right strategy.
- Need to service lots of reads? Go with a simple leader-follower replication strategy. Read replicas are simple and cheap. This is the best option if you have a read-heavy application like an online news source, or if your read-heavy system is scaling globally and you want to provide a consistent user experience.
- Need to increase the reliability of your system? Go with multi-leader replication so that if and when a leader goes down, you can continue to operate without data loss. You will have to include some sort of conflict resolution strategy, though. More specifically, multi-leader is most often used when you're scaling across multiple data centers, because you'd want to have one leader in each data center that can perform writes — and then replicate to other data centers.
- Need to service lots of writes or scale-up globally? Consider a leaderless solution. If your system runs on-premise as opposed to in the cloud, make sure you build in appropriate conflict resolution strategies.
- Pursuing a multi-region strategy? Use replicas as database backups for disaster recovery on a per-region basis. For example, you want to be able to handle major outages or natural disasters that affect particular regions, so you implement a multi-leader strategy in affected regions to handle writes in case of failover.
Further Reading
- Read Amazon's original DynamoDB paper for an interesting discussion around the challenges the team faced in fusing techniques like consistent hashing, quorum, anti-entropy-based recovery, and more.
- Try your luck with Paxos Made Simple, the slightly frustrated attempt by brilliant computer scientist Leslie Lamport to explain his widely-used but little-understood consensus algorithm.
13 - Database sharding techniques
What is Database Sharding?
Traditionally, data has been stored in an RDBMS (Relational Database Management System), where data is stored in tables as rows and columns. For data with 1-to-N or N-to-N relationships, a process of normalization would instead store the data in separate tables joined together by Foreign Keys, which ensure that the data in these tables do not get out of sync with each other, and can be joined to get a complete view of the data.
However, as data size increases, traditional database systems run into bottlenecks on CPU, Memory or Disk usage. As a result, they will need increasingly high-end and expensive hardware in order to maintain performance. Even with top-quality hardware, the data requirements of most successful modern applications far exceed the capacity of a traditional RDBMS.
Sometimes, the structure of the data is such that the tables holding data can be broken up and spread across multiple servers. This process of breaking up large tables into horizontal data partitions, each of which contains a subset of the whole table, and putting each partition on a separate database server is called sharding, and each partition is called a shard.
Sharding techniques
Most times, the technique used to partition data will depend on the structure of the data itself. A few common sharding techniques are:
Geo-based sharding
Data is partitioned based on the user’s location, such as the continent of origin, or a similarly large area (e.g. "East US", "West US"). Typically, a static location is chosen, such as the user’s location when their account was created.
This technique allows users to be routed to the node closest to their location, thus reducing latency. However, there may not be an even distribution of users in the various geographical areas.
Range-based sharding
Range-based sharding divides the data based on the ranges of the key value. For example, choosing the first letter of the user’s first name as the shard key will divide the data into 26 buckets (assuming English names). This makes partition computation very simple, but can lead to uneven splits across data partitions.
Hash-based
This uses a hashing algorithm to generate a hash based on the key value, and then uses the hash value to compute the partition. A good hash algorithm will distribute data evenly across partitions, thus reducing the risk of hotspots. However, it is likely to assign related rows to different partitions, so the server can’t enhance performance by trying to predict and pre-load future queries.
Manual vs. Automatic
Some database systems support automatic sharding, where the system will manage the data partitioning. Automatic sharding will dynamically re-partition the data when it detects an uneven distribution of the data (or queries) among the shards, leading to higher performance and better scalability.
Unfortunately, many monolithic databases do not support automatic sharding. If you need to continue using these databases, but have increasing data demands, then the sharding needs to be done at the application layer. However, this has some significant downsides.
- One downside is a significant increase in development complexity. The application needs to choose the appropriate sharding technique, and decide the number of shards based on the projected data trends. If those underlying assumptions change, the application has to figure out how to re-balance the data partitions. At runtime, the application has to figure out which shard the data resides in, and how to access that shard.
- Another challenge with manual sharding is that it typically results in an uneven distribution of data among the shards, especially as data trends differ from what they were when the sharding technique was chosen. Hotspots created due to this uneven distribution can lead to performance issues and server crashes.
- If the number of shards chosen initially is too low, re-partitioning will be required in order to address performance regression as data increases. This can be a significantly complex operation, especially if the system needs to have no downtime.
- Operational processes, such as changes to the database schema, also become rather complex. If schema changes are not backward compatible, the system will need to ensure that all shards have the same schema copy and the data is migrated from the old schema to the new one correctly on all shards.
Advantages
- Sharding allows a system to scale out as the size of data increases. It allows the application to deal with a larger amount of data than can be done using a traditional RDBMS.
- Having a smaller set of data in each shard also means that the indexes on that data are smaller, which results in faster query performance.
- If an unplanned outage takes down a shard, the majority of the system remains accessible while that shard is restored. Downtime doesn’t take out the whole system.
- Smaller amounts of data in each shard mean that the nodes can run on commodity hardware, and do not require expensive high-end hardware to deliver acceptable performance.
Disadvantages
- Not all data is amenable to sharding.
- Foreign key relationships can only be maintained within a single shard.
- Manual sharding can be very complex and can lead to hotspots.
- Because each shard runs on a separate database server, some types of cross-shard queries (such as table joins) are either very expensive or not possible.
- Once sharding has been set up, it is very hard (if not impossible) on some systems to undo sharding or to change the shard key.
- Each shard is a live production database server, so needs to ensure high-availability (via replication or other techniques). This increases the operational cost compared to a single RDBMS.
Further Reading
- This post, featured on Square's engineering blog has it all — technical detail, business context, drama, and a few helpful gifs.
14 - How do computers handle memory management
While memory management largely depends on the programming languages a company is built on (and therefore not up to much debate), questions about memory management can serve as a good test case to gauge general knowledge. Different systems employ different techniques for memory management, each with its own advantages and disadvantages, and being able to speak to the pros and cons of each will help you in your interviews.
Why Memory Management is Important
Memory management deals with how the system allocates and frees up memory during the execution of a program. Most older, popular, programming languages, such as C and C++, do not have any kind of automatic memory management. Developers have to allocate and release memory explicitly (by calling malloc()/free() in C, new/delete in C++).
There are two kinds of memory storage — Stack and Heap. Management on the stack is automatic on all platforms, so the question is primarily about Heap storage. Allocation works much the same on all systems; the question primarily deals with techniques to free up unused memory. Let’s focus on that.
A critical requirement for managing memory effectively is that each allocation be matched by exactly one de-allocation.
- If the developer forgets to release allocated memory, the system cannot reclaim it and the memory leaks, i.e. becomes unusable until the program terminates. Over time, this would result in the program running out of memory and crashing, which would be especially problematic if this were to happen in a server or in the operating system.
- If the developer accidentally attempts to release previously de-allocated memory, it would end up releasing memory that’s currently in use, leading to unpredictable and often disastrous consequences such as a crash or a security exploit.
How it Works
Though manual memory management adds the least amount of overhead to the program, it also results in the most bugs because it relies on developers never forgetting to call the appropriate de-allocation functions. It’s difficult for developers to figure out who’s responsible for releasing memory when using third-party libraries, and has led to innumerable issues in the past. Most modern programming languages therefore rely on automatic mechanisms to manage memory. The two most common patterns are Garbage Collection and Automatic Reference Counting.
Garbage Collection
This is by far the most common pattern for de-allocating memory, and is used by Java, .Net, and Go, among various others. When the system detects that a program is running low on memory, it pauses execution of the program and runs a Garbage Collector (GC). The GC does the following:
- Marks all the in-use memory that’s reachable from the current program state.
- Compacts the heap by moving all reachable memory into the beginning of the heap, and updates references to the new locations.
- Releases all unreachable memory.
The Garbage Collector also optimizes the number of times it runs, by figuring out which memory is short-lived and which one has to persist for longer. It does so by assigning a generation to each piece of memory. Memory that persists across multiple runs of the GC is promoted from Gen0 to Gen1 and finally to Gen2. Older generations are cleared much less frequently by the GC because they typically indicate storage that persists through the lifetime of the process.
Automatic Reference Counting (ARC)
An alternative approach is to maintain a reference count to each piece of allocated memory, and update it as the program executes. When a variable refers to an object in memory, the reference count of that object is incremented. When the variable stops referencing the object, the reference count is decremented. When the reference count of an object reaches zero, the memory is freed immediately. This approach is used by Apple in both Objective-C and Swift on iOS.
When to use ARC vs. Garbage Collection
Garbage collection is the most developer-friendly option, since it removes the mental overhead of managing references. However, it could result in the program being paused at random points during execution, which makes it less suitable for real-time and user-interactive applications. This was a big reason why Apple preferred to instead use ARC in iOS.
The developer overhead is higher in ARC, because it requires the developer to be conscious about inadvertently creating reference cycles, which would result in memory leaks. It also requires additional space to store the reference count per object, and incurs a small runtime overhead in incrementing and decrementing reference counts.
In most situations, the development team will not have a choice of which memory management strategy to use, since that will be dictated by the platform/language that the product is built on. The development team will have to figure out how to optimize the experience within the limitations of the strategy that the platform employs.
Further Reading
- This article on Uber's Engineering Blog offers a detailed account on the company's experiments with GC tuning to improve service performance, throughput, and reliability.
15 - How to answer encryption questions
Cryptography is the study of encrypting and decrypting information for secure transmission between two parties. Generally, there are two steps:
- Encryption is the process of converting plain text into code, or ciphertext.
- Decryption is the reverse — converting ciphertext back to plaintext.
Why encryption matters
At a high level, businesses have three powerful tools to help keep both user data and internal data out of the wrong hands. These are encryption, authentication, and authorization (the latter two will be covered in the next lesson.)
Given the tradeoff between security and user experience, tools which are more or less invisible to users are ideal.
Encryption is a perfect example of a non-intrusive security measure.
How it works
Generally, an encryption algorithm translates (encodes) plaintext into ciphertext, making it unreadable and therefore useless to anyone without the decryption key. There are two basic types of encryption.
Symmetric encryption
Symmetric encryption uses the same key for both encryption and decryption. It's fast and easy, provided that the key stays secret.
This might sound risky, but it isn't provided that you follow a few guidelines. The strength of the key depends on:
- Its length
- Its entropy (or, the "randomness" inherent in creating it)
- How easy it is to deconstruct
Symmetric algorithms (or ciphers) take one of two forms: block or stream. Block ciphers encrypt data in blocks, where stream ciphers encrypt data one bit at a time. AES, or the Advanced Encryption Standard is a block cipher used across the internet. Key lengths range from 128 to 256-bits, which is quite long. AES using a 256-bit key is considered unbreakable.
Asymmetric encryption
Asymmetric encryption uses two different keys for encryption and decryption. The encryption (public) key is visible to all, while the decryption key stays private. Asymmetric encryption takes longer, but it's considered to be more secure.
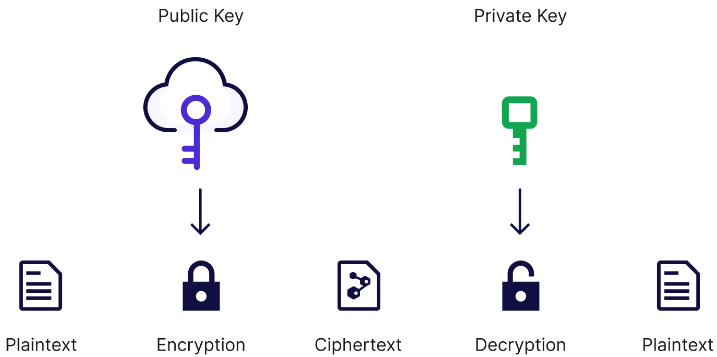
Some well-known examples of asymmetric encryption algorithms include RSA, which was developed alongside early TLS (Transport Layer Security). While RSA is considered less robust than Diffie-Hellman Key Exchange, Diffie-Hellman doesn't authenticate and RSA does. Both use mathematics to generate decryption keys that are all but impossible for attackers to deconstruct, and both are used extensively today.
Symmetric and asymmetric encryption work together in SSL/TLS
Symmetric encryption is considered less secure than asymmetric, but it's faster and uses less computing power. To provide security over a network, these two methods are used in tandem.
SSL (Secure Sockets Layer) is an older form of TLS (Transport Layer Security), a protocol running on the application layer of the Internet that's designed to secure web communications through a TLS handshake. To establish a TLS connection, the client can either:
- Make a request using port 443 (reserved for encrypted HTTPS traffic), or
- Request that the server switch to TLS. If the server agrees, a handshake is initiated.
An asymmetric cipher generates a session-specific shared key while further communication is symmetrically encrypted. The overall connection is protected with the more secure asymmetric cipher, but beneath that, symmetric encryption is used to protect the data without slowing down transmission.
Password protection with bcrypt
Data transmitted over TLS is considered safe, but what about sensitive data stored in a database, like user passwords? Generally, the best practice is to hash and salt passwords using a powerful, time-tested algorithm like bcrypt. Hashing mathematically scrambles the data, making it difficult to reverse-engineer. But since passwords are short and can be predictable — like "MyPassword", hashed passwords may still be susceptible to brute-force attacks. Salting helps address both of these by adding a unique value to the end of a password before hashing. This makes it longer and increases entropy. Bcrypt, which has been around for decades, hashes and salts passwords in a way that slows down brute force attacks even as computing power increases. Even though it's old by some standards, it's considered industry-grade and plenty of popular authentication & authorization platforms depend on it to protect passwords.
Don't confuse encryption with hashing. Using bcrypt (or similar methods) irreversibly hashes (scrambles) the password so that it isn't stored anywhere. Even those with direct database access can't see them.
When to bring up encryption in an interview
It's unlikely you'll have to go into detail, but it's good to know best practices for encryption. Generally, you should encrypt both in transit and at rest. Encrypting in transit these days mainly means using HTTPS rather than HTTP, making use of TLS protocols above.
Encrypting at rest means protecting data while in storage. Most modern databases allow for encryption, often AES 256-bit. The best practice for password protection is to both hash and salt passwords using something like bcrypt.
Depending on your application, you may also want to encrypt while processing (for example, if you're working in fintech.) Cloud architecture offers great options.
Finally, modern messaging apps like iMessage, Whatsapp, and Signal often use end-to-end encryption (E2EE). In these, the message is actually encrypted from one user to another, so the unencrypted message is never stored anywhere except on the user's device.
Further reading
- Most big cloud providers use symmetric encryption at rest. Check out these links for details on how Microsoft Azure and Salesforce manage encryption.
16 - Authentication and authorization
In the last lesson, we mentioned that companies have three basic tools to keep secure data safe, and we described the first (encryption) in detail. This lesson will cover the other two: authentication and authorization.
- Authentication is the process of proving you are who you say you are when accessing an application.
- Authorization is the process of defining and enforcing access policies - that is, what you can do once you're authenticated.
Why authentication and authorization matter
Keeping data secure means ensuring that the right people (and only the right people) have access to sensitive data. Identifying and vetting users every time access is requested is hard to do, and authentication tools help automate the process.
Authorization goes one step further. For example, say a salesperson needs access to their company's CMS system which stores sensitive customer data. The authentication system will confirm they are legitimate. But do they need access to mergers & acquisitions data? Probably not. An authorization policy ensures that different users have different access depending on their needs.
How it works
A secure system includes both, and authentication comes first.
Authentication (or AuthN)
The most common authentication factors are usernames and passwords. When the right credentials are given, a system considers the identity valid and grants access. This is known as 1FA or single-factor authentication, and it's considered fairly insecure. Why? Because users are notoriously bad at keeping their login information secure. Multi-factor authentication (MFA) is a more secure alternative that requires users to prove their identity in multiple ways. This could be through:
- Single-use PIN numbers
- Authentication apps run by a secure 3rd party
- Biometrics
When choosing an authentication process, there are a few things to keep in mind.
First, remember that security measures shouldn't overly inconvenience users unless they're forced to use your service. Don't ask for biometrics if you're running a free online chess game.
Second, there's an adage in cybersecurity that says "security is only as good as its weakest link." The weakest link is often users. Whether through password apathy, vulnerability to clever phishing schemes, or pure negligence, companies have their work cut out for them. Instituting policies that require good password hygiene can help (requiring long passwords with numbers and special characters, regular password updates, timed log-off, etc.)
Luckily, you don't have to build authentication/authorization platforms yourself. Auth0 is a well-known platform that sits between your application(s) and Identity Providers like Google or Facebook that offer Single Sign-on (SSO), connecting and securing you and your data through standard APIs. How? Through a token-based authentication method called JWT (JSON Web Token) which is good for stateless applications (and protocols, like HTTP). Another method for authentication over the web uses sessions and cookies.
Session vs. Token-Based Authentication
Maintaining authentication (without hassling users) across a stateless HTTP connection is an important problem because no one wants to enter their password every time they make a request.
Session-based authentication (an older method) relies on the server to track authentication. When a user logs in to a website on a browser, the server creates a session for that user. A session ID is assigned and stored in a cookie in the user's browser, preserving authentication while the user is on the site. Typically, cookies are deleted when a user logs off, but some browsers use session restoring, which keeps the session cookies in memory even after the user logs off. Much easier than logging in each time you want to access a page.
Token-based authentication is different. When a user logs in, the server creates an encrypted token that allows users to perform any activity on the site. Instead of the server storing session IDs, the client stores the token, either in memory or in a cookie (much like session IDs.)
The main difference between token and traditional session-based authentication is that session-based authentication is very stateful. The server stores the session ID and user info in memory or in a separate session cache, which can become complex as the system or number of users scale.
Token-based authentication is not always stateless, though. Many API tokens are still stored in a database table so they can be verified or revoked.
JWTs are a particularly popular flavor of token-based authentication because they save user data inside the token and can be validated without the database lookups mentioned above. This makes them well-suited for serverless and stateless applications.
JWTs are:
- Small (they transmit quickly)
- Secure (they're asymmetrically encrypted)
- Widely-used (JSON objects are everywhere; virtually all programming languages have JSON parsers, and almost every big web API uses JSON)
- Transparent (their structure makes it easy to verify senders and that contents haven't been tampered with)
JWTs are not without their drawbacks. While they are encrypted, they cannot easily be revoked or invalidated on the server-side, introducing risk. Because of this, they typically use shorter expiration times.
Authorization (or AuthZ)
Once a user is authenticated, we still need to ensure that they're only allowed access to certain resources. Because unauthorized access to sensitive data can be so catastrophic, many companies set up access policies according to the principle of least privilege. That is, by default, you're only allowed access to what you absolutely need. A few common ways to segment access are:
- Role-based (RBAC): Users are assigned to a certain group (or role) that comes with set permissions. Some examples may include "admin", "member" or "owner."
- Attribute-based (ABAC): Users are permitted access according to attributes like title, certification, training, and/or environmental factors like location. Sometimes known as "policy-based access control" or PBAC.
- Access Control Lists (ACL): Each user or entity has individual permissions that can be turned on or off, similar to installing a new app on your phone and deciding which permissions to grant (location services, contacts, etc.)
ACL is typically used at a more granular level than either ABAC or RBAC — for example, to grant individual users access to a certain file. ABAC and RBAC are generally instituted as company-wide policies.
RBAC is simple. Our salesperson above would probably be given access to a set of customer data according to their territory. ABAC is more flexible and adaptable to events. Say a security breach happens and it's all-hands-on-deck for the infosec team. There may not be an existing role that grants access to all the systems involved in the breach. Someone would have to create a new role and change each infosec team member's role assignment under RBAC. This should be easier under ABAC, but of course, it all depends on how the policies are written. Another common use case for ABAC is a situation where users might have multiple attributes with different permissions. For instance, your news app may employ editors who also author individual stories. These two roles need access to different pages. Under ABAC, you could set attributes = editor, author.
OAuth 2
Outside of a closed business environment, authorization frameworks are needed to securely connect users across applications like Facebook and Instagram, or PayPal and your banking app. OAuth 2 is a popular framework that uses APIs to extend authorization across connected apps.
Let's go through an example. Let's say you've created a personal assistant app that needs access to a user's Gmail. Google supports OAuth 2, so once you've registered the app with Google and set up your APIs, your app would be able to access your users' Gmail accounts without compromising their usernames and passwords. How does this work?
Four roles are defined:
- Resource Owner or User: Owns the account and wants to grant read and/or write access to an application. Credentials include a username and password. In the above example, this is a user who wants to use your personal assistant app.
- Client: An application that accesses the user's account. It must be authorized by the user and validated by the authorization provider. Credentials include an ID and a client secret (analogous to a username and password, but specific to the client itself.) Your app.
- Resource Server: Houses the application and/or data owned by the user. Will allow access to a client if the client has a valid access token. Gmail in the above example.
- Authorization Server: A 3rd party that verifies the identity of the user and the client, and issues access tokens.
There are 5 different grant types that OAuth 2 uses. Think of each grant type as a way for an application to get an access token. These are:
- Authorization code grant. The most common grant type; the client exchanges an authorization code in exchange for an access token.
- Resource owner credentials grant Allows a client to sign in directly using the resource owner's password.
- Client credentials grant. Mainly used for server-to-server interactions; no resource-owner interaction required.
- Implicit grant. This grant type was previously recommended for single page applications which couldn't keep a client secret. This has been superseded PKCE used with a standard authorization code grant.
When to bring these up in an interview
If you're specifically asked to design an authorization service, be sure to choose carefully (1FA vs. MFA, which factors you'll require if you choose MFA, etc.) because they can have a big impact on the user experience. You have a responsibility to keep sensitive data safe, but you also don't want to drive away users. Otherwise, it's useful to know about existing authentication infrastructure, but it's doubtful you'll be asked specific questions about it.
Authorization policies are less visible to users. If you're building a large, dynamic system in which users' needs change frequently and/or users can embody several different attributes, we recommend going with ABAC, but RBAC works well in simple cases. It's also useful to know how OAuth 2 works if you think you may be asked to design an app that'll interact with identity providers or other apps using APIs. We've linked to the documentation below.
If you're building apps that need access to other services, look into OAuth 2 and standardized API design. There's no need to reinvent the wheel, especially in a system design interview when you probably want to focus on more functional areas.
Further Reading
- Check out this series on the development of OAuth to get a perspective on how early social platforms solved authentication problems in the early 2000s and eventually converged on API standards. It's an interesting case study on the development of open standards driven by a rapidly-changing industry, and it brought us to where we are today.
- This paper on existing multi-factor authentication methods and future trends covers the major operational challenges that block MFA, and proposes some solutions.
17 - How to answer questions about cloud architecture
The main difference between on-premise and cloud-based solutions is where the hardware that runs your software resides. On-premise means that your software runs locally, on machines you own, or that you rent space from within a data center. Cloud-based applications are hosted and maintained entirely by someone else. There are many cloud service providers including the big three:
- Amazon Web Services (AWS)
- Google Cloud (GCloud)
- Microsoft Azure
Why pursue a cloud-based strategy?
Hardware is a huge capital expenditure for most companies, and as you've learned, it can be hard to design a system flexible enough to account for future growth. When you go with a cloud provider, you pay much less (sometimes nothing) upfront and you gain significant peace of mind.
The pros of migrating to the cloud include:
- Affordability. Most providers don't charge upfront; you'll likely "pay-as-you-go" and maintenance costs are included.
- Professional maintenance. Compatibility and upgrades are taken care of for you, and new software deployments can happen much more quickly.
- Security. Huge cloud providers benefit from economies of scale, especially in security. Data centers are able to provide security far beyond what is financially possible for most smaller companies, so you know your data will be safe.
- Scalability. The entire cloud model is based on the principle of "only pay for what you need." Need to scale up quickly? No problem.
This all sounds great, but there are cons to consider as well, including:
- Higher long-term costs. You'll save a lot upfront, but eventually, you would have paid off your initial hardware costs. Hosting your software on the cloud often increases your total cost of ownership on a long-term basis.
- Loss of control. Cloud providers are very flexible, but it's possible that a very complex deployment won't be compatible with a cloud configuration.
- Vendor lock-in. It can be very difficult to switch providers or take your software off of the cloud, should you decide that you made the wrong choice.
- Industry-specific regulations. Some cloud-based services might not be compliant with industry-specific regulations like HIPAA (healthcare), FERPA (education), PCI (payments).
- Physical location. You might need to be physically located in a particular location for legal or security reasons. For example, the US government wouldn't store data in Russia.
- Airgapping. If you have ultra-high security needs, you would want to ensure that your system is airgapped - that is, it isn't connected to any external networks.
What do cloud providers offer?
At a high level, you can expect:
- Compute products in the form of dedicated servers, virtual machines, GPUs, batch processing, or all of the above. There are endless configurations available to suit your needs. You can even go with serverless computing, which is event-driven and paid per execution for ultimate flexibility.
- Containers for your code, isolating it for easy portability and added security.
- Database flexibility. All major providers offer many different database solutions, from traditional RDBMS to graph and time-series databases, in-memory database and caching services, and more.
- Networking. Including tools to maintain microservices, API gateways, DNS, and more.
- Niche tools. In addition to all manner of monitoring and analytics, you'll have access to developer tools, machine learning, and all varieties of application-specific computational resources you can imagine.
Here's a quick reference comparing different services across the "big 3."
| Product | AWS | GCloud | Azure |
|---|---|---|---|
| Compute & Compute Autoscaling | AWS EC2, AWS Autoscaling | Cloud GPUs, Compute Engine, Compute Engine Autoscaler | Azure Virtual Machines (VM), Azure Autoscale, Azure VM Scale Sets |
| Load Balancing | Elastic Load Balancing | Cloud Load Balancing | Azure Load Balancing |
| Serverless Computing | AWS Lambda | Cloud Functions | Azure Functions, Serverless Compute |
| Containers | Elastic Container Service (ECS), Amazon Elastic Kubernetes Service (EKS), AWS App2Container | Google Kubernetes Engine, Migrate for Anthos | Azure Kubernetes Service (AKS), Azure Migrate |
| Object Storage and Database | S3, Amazon DynamoDB (NoSQL), Amazon Aurora, Amazon RDS (SQL) | Cloud Storage, Datastore, Cloud Bigtable (NoSQL), Cloud Spanner (SQL) | Azure Storage, Azure Cosmos DB (NoSQL), Azure SQL Database, Azure Database for PostgreSQL |
| Data Analytics | AWS Glue, Amazon AppFlow, Amazon Data Pipeline | Data Catalog, Cloud Data Fusion | Azure Purview, Azure Data Factory |
| Logging, Monitoring & Performance Tracing | Amazon CloudWatch, CloudWatch Logs, AWS X-Ray | Cloud Logging, Cloud Monitoring, Cloud Trace | Azure Monitor, Monitor Logs, Monitor Application Insights, Distributed Tracing |
| Platform-as-a-Service (PaaS) | AWS Elastic Beanstalk | App Engine | Azure App Service |
Orchestration Services
Orchestration automates the processes needed to monitor and manage a complex, auto-scaling cloud deployment. Two popular orchestration tools to know are Terraform and Kubernetes. Both of these are open-source which is a huge plus when migrating between cloud platforms. They can't be used interchangeably as they excel at orchestrating different "layers" of a complex system — but there is overlap, and they can be used together.
Terraform manages the physical infrastructure of an auto-scaling system. This includes DNS records, virtual machine (VM) instances, etc. Generally lower-layer resources. How? It's an instance of a clever tactic called Infrastructure as Code. The idea here is that by treating your infrastructure as code, you're able to easily document changes. Roll back a version if needed, or scale globally - anything you can do with code, you can pretty much do with your physical infrastructure using Terraform.
Kubernetes, a container orchestration platform, manages upper-layer resources. Building containerized applications has several advantages — each container is isolated from one another, making development, scaling, and maintenance all relatively simple. But as you can imagine, managing a large network of containers can be challenging. Kubernetes treats groups of containers as clusters, and manages the different workflows required by each cluster as needed.
It's very good at its job. In fact, each of the big three cloud providers (and virtually all others) includes a service dedicated to managing Kubernetes clusters.
How do companies switch from on-premise to cloud-based hosting?
It's worth noting that there are a few different strategies businesses can take when deciding to migrate to the cloud. Here are a few popular choices.
- 1) Re-host: Also known as "lift and shift." Simply shift data from on-premise infrastructure to a cloud-based infrastructure. Good for large-scale migrations.
- Pros: Simple, fast, automation tools available
- Cons: Legacy apps might be incompatible, may miss out on some benefits of the cloud
- 2) Re-platform: "Lift, tinker and shift." Rehosting with some minor tweaks to capture full cloud benefits.
- Pros: Capture all the benefits of cloud migration with minimal effort
- Cons: Careful management is needed as re-platforming can easily turn into a full, time-and-resource intensive refactoring.
- 3) Refactor: Fully re-architecting applications to suit the cloud. Often used only as a last resort, or as a strategic choice (for example, when choosing to switch from a monolithic to microservice architecture.)
- Pros: Refactoring at the right time can be a huge boost to a company losing its competitive edge. Successful refactoring means increased speed, scalability, and performance.
- Cons: Risky. Easily the most difficult, expensive, and time-consuming strategy. Can be hugely disruptive to operations if mismanaged.
- 4) Repurchase: A much lighter migration; from an on-premise application to a cloud-based solution. Good for transferring standard business workflows like payroll and accounting or CMS.
- Pros: Simple, fast, and easy
- Cons: Few major risks apart from "switching costs" from having to retrain staff and exit an existing contract
When will I come across this in an interview?
If you're interviewing with a major cloud provider, it's helpful to understand their product offering and how they compare to what else is out there. Many companies like to ask system design questions that reflect a real business need, so we recommend spending significant time learning the landscape of cloud services if you're interviewing with Amazon AWS or within Azure at Microsoft. We recommend checking out our repository of engineering blogs if you haven't already.
If you're interviewing at a non-cloud provider that hasn't yet made the switch, the question of on-premise vs. cloud might be a good topic to dive into if you're looking to showcase your big-picture thinking. Be sure to check in with your interviewer before going into much detail. If you do go down this road, don't forget to circle back to high-level tradeoffs around cost and engineering time.
Remember, cloud deployments can decrease or eliminate upfront costs which might be critical in a startup environment, but they often increase total cost of ownership. However, if you expect unpredictable spikes in traffic, you're worried about security, or you decide to offload maintenance tasks so your engineering team can focus on core competencies, a cloud-based solution may make sense.
Further Reading
- When Spotify began to consider switching to the cloud in 2015, they had no idea how complex the project would be. Read this series from their engineering blog to learn about the technical details as well as the business case for switching.
- Check out this exhaustive comparison table of Cloud products by function for GCloud, AWS, and Azure (take with a grain of salt; it's published by Google!)
18 - Strategies for improving reliability
A reliable system can perform its function, tolerate errors, and prevent unauthorized access or abuse. Reliability implies availability, but it's more than that. Building for reliability means added security, error-handling, disaster recovery, and countless other contingencies.
Why? Because things will fail. Whether due to network outages, hardware failure, a botched roll-out, or a malicious attack, any system with dependencies must include logic to deal with failures. Most failures in distributed systems come from either:
- Hardware errors: Network outages, server failure, etc. These won't be fixed quickly, and are often called non-transient errors.
- Application errors: Bugs, failure to accommodate spikes in traffic, etc. These should resolve quickly and are also known as transient errors.
It should logically follow that beefing up system reliability will have implications for performance and cost in terms of complexity, engineering time, and money. When implementing reliability techniques in an interview scenario, it's helpful to:
- Refer back to the requirements you've defined upfront. This will help you focus on mitigating the most important / most likely risks.
- Assume failures will happen, and design your system to recover gracefully (in alignment with predefined requirements) from the very beginning.
- Include testing strategies and monitoring techniques to help you benchmark your system in terms of requirements, monitor its health, and make changes as needed. We'll cover a few common strategies in a later lesson.
Here are a few effective reliability strategies to consider.
Retries
Under a simple retry strategy, an application detecting a failure will immediately retry. This might work well if the failure detected is unusual and unlikely to repeat, but for common transient failures (e.g. network failures) repeat retries may overload the downstream system once the network issue is resolved. Delayed retry holds the retry back for a set amount of time allowing the system to recover. Many engineers implement an exponential backoff strategy that systematically decreases the rate of re-transmission in search of an acceptable retry rate.
Use cases
- Simple retry for unusual and transient errors. We recommend implementing some type of request limit to prevent overload.
- Delayed retries using exponential backoff for more common transient errors.
Techniques & considerations
Retry buildup in high-traffic systems can lead to extremely high system load once the error is resolved. This is called the thundering herd problem, and it can cause even more problems than the transient error as your resource(s) struggle to cope with the request volume. A simple solution is to introduce jitter, or "randomness" to the delay intervals so that client requests don't synchronize.
From a UX perspective, keep in mind that in some cases it's better to fail fast and simply let users know. In this case, implement a low retry limit and alert users that they'll need to try again later.
Circuit Breakers
A robust retry policy can alleviate short-lived transient errors... but what about non-transient errors? Or transient errors with uncertain recovery times?
While a retry pattern assumes that the operation will ultimately succeed, a circuit breaker accepts failure and stops the application from repeatedly trying to execute. This saves computing power and helps prevent the cascading failures we discussed above. Importantly, a circuit breaker has a built-in mechanism to test for whether a service has been restored unblock traffic accordingly. Circuit breakers can occupy a few states analogous to physical circuit breakers.
Remind me how a circuit breaker works? Physical circuit breakers cut power as soon as they detect that an electrical system is not working properly. But unlike other failsafes, they're not single-use. Once the circuit has been repaired, you can simply flip the switch, and power is restored. A circuit breaker strategy works similarly. The breaker detects a problem, cuts off requests, and restores access when repairs are complete.
For example, let's say an application sends a request.
All is working well and the circuit breaker is in a closed state. It monitors the number of recent failures, and if this number exceeds a threshold within a given interval, the circuit breaker is set to open. No further requests are let through. A timer is set, giving the system time to fix the issue without receiving new requests. Once the timer expires, the circuit breaker is set to half-open; A few requests are allowed through to test the system. If all are successful, the breaker reverts to its closed state and the failure counter is reset. If any requests fail, the breaker reverts to open and the timer starts again.
Use cases
- Prevents cascading failures when a shared resource goes down.
- Allows for a fast response in cases where performance and response time are critical (by immediately rejecting operations that are likely to timeout or fail).
- Circuit breakers' failure counters combined with event logs contain valuable data that can be used to identify failure-prone resources.
Techniques & considerations
There are a few main points to remember when implementing circuit breakers.
- You'll need to address exceptions raised when a resource protected with a circuit breaker is unavailable. Common solutions are to temporarily switch to more basic functionality, try a different data source, or to alert the user.
- Configure the circuit breaker in a way that makes sense for 1) the recovery patterns you anticipate, and 2) your performance and response time requirements. Setting the timer correctly can be nuanced. It may take some trial and error.
Saga
Saga is a strategy used most often in microservice architecture where completing an action (also known as a distributed transaction) entails successfully completing a set of local transactions across multiple independent services. What if you encounter a failure halfway through? This type of failure can wreak havoc with your system.
Imagine you run an ecommerce site. When a customer buys an item, their cart is updated, their payment is charged, the item is pulled from inventory, shipped, and invoiced. If you fail to pull the item from inventory, you'll need to reverse the charge to your customer — but without any structured compensating transactions in place to reverse the transactions that have already succeeded, you're stuck.
A saga is an alternate structure. Instead of a single distributed transaction, the component local transactions are decoupled, grouped, and executed sequentially. Each string of related local transactions is a saga. If your saga coordinator (more on that below) detects a failure, it invokes a predefined set of "countermeasures", effectively reversing the actions already taken. In the case of our ecommerce site, the inventory number would revert back to its previous state, and payment and cart updates would be reversed.
To implement a saga strategy, you can either coordinate saga participants via choreography, a decentralized approach where each local transaction triggers others, or orchestration, where a centralized controller directs saga participants.
Use cases
- Maintains data consistency across multiple services.
- Well-suited to any microservice application where idempotency (the ability to apply the same operation multiple times without changing the result beyond the first try) is important, like when charging credit cards.
- For microservices in which there aren't many participants or the set of counter transactions required is discrete and small consider choreographed saga as there's no single point of failure.
- For more complex microservices, consider orchestrated saga.
Techniques & considerations
Sagas can introduce quite a lot of complexity into your system. You'll have to build the set(s) of compensating transactions that are triggered by different failures. Depending on your application, this might require substantial work upfront to understand user behavior and potential failure modes.
Fundamentals review
If you haven't already, check out the following lessons on system design fundamentals that relate to system reliability.
- Consistent Hashing
- CDNs
- Load Balancers
- Caching Strategies
- Asynchronous Processing
- Database Sharding
19 - Strategies for improving availability
An available system is able to perform its functionality. This seems obvious; who would ever deploy a system that doesn't do its job? In reality, things are more complicated. High availability (HA) is difficult to achieve for two reasons.
- Scaling, or building a system to accommodate changes in traffic, is hard.
- Networks and hardware will fail.
Availability is usually reported as a percentage of uptime / total time. It's impossible to guarantee 100% availability, but most cloud providers include a high availability guarantee — something approaching the highly-coveted 'five nines', or 99.999% availability — in their service level agreements (SLAs.)
Remember that although availability and reliability are related, they are not the same. Reliability implies availability, but availability doesn't imply reliability. That said, much of the strategies below are also helpful in improving system reliability, so don't be afraid to use them as such.
In your system design interviews, you may be asked a follow-up question around increasing your system's availability. Here are a few effective strategies to consider.
Rate Limiting
Rate limiting refers to capping the number of times an operation can occur within an interval. The main reason you'd want to impose rate limiting is to protect your service from overuse - intentional or not. You may wonder "how does rate-limiting requests improve availability if we're dropping reuests?" It's important to note that you're not rejecting all requests good and bad. You're simply capping usage by particular users, organizations, IP addresses, etc... sometimes even other parts of your system.
It's possible to enforce rate limits on both the client and server-side. Doing this will minimize latency, maximize throughput, and help manage traffic and avoid the excess cost.
Use cases
- Prevent an autoscaling component from running over budget.
- Preserve the availability of a public API given a DoS attack or accidental overuse.
- Help SaaS providers control access and cost on a per-customer basis.
Techniques & considerations
- Token bucket: A token bucket strategy recognizes that not all requests require equal "effort." When a request is made, the service attempts to withdraw a certain number of tokens in order to fulfill the request. A request that requires multiple operations may "cost" multiple tokens. If the bucket is empty, the service has reached its limit. Tokens are replenished at a fixed rate, allowing the service to recover.
- A leaky bucket works similarly. Requests are "held" in a bucket. Each new request fills the bucket higher and higher. When the bucket is full (and the limit has been reached), new requests are discarded, or leaked.
- Fixed and sliding window: Fixed window rate limiting is simplicity itself — for example, 1000 requests per 15-minute window. Spikes are possible, as there's no rule preventing all 1000 requests from coming in within the same 30 seconds. Sliding window "smooths" the interval. Instead of 1000 requests every 15 minutes, you might define a rule such as 15 requests within the last 30 seconds.
Queue-Based Load Leveling
Like rate-limiting, queue-based load leveling is a strategy to protect against service overuse. Instead of dropping requests like rate-limiting does (another way to think about rate-limiting is load "shedding"), load leveling introduces intentional latency.
The problem is most pronounced in cases where multiple tasks demand the same service concurrently. System load can be hard to predict under these circumstances, and if the service becomes overloaded it may fail. In queue-based load leveling, the solution is to decouple the task(s) and service(s) and introduce a queue between the two. A simple message queue will store requests and pass them to the service in an orderly fashion.
A drive-through is the perfect real-world analog for queue-based load leveling. As a restaurateur, you wouldn't try to serve 1000 customers who've all arrived at the same time. Instead, cars are funneled through a queue in a FIFO (first-in-first-out) fashion.
Use cases
Consider this strategy anytime a service is:
- susceptible to overloading
- higher latency is acceptable during spikes, and
- it's important that requests are processed in order.
Techniques & considerations
Be careful when designing your queue and be mindful of the limitations of your downstream service. Queue depth, message size, and rate of response are all important considerations depending on the rest of your system.
Also, this strategy assumes it's easy to decouple tasks from services. In legacy or monolithic architecture this might not be the case.
Gateway Aggregation
Another strategy for dealing with complicated requests, or decreasing client-backend "chattiness" Is to introduce a gateway in front of the backend service. The gateway aggregates requests and dispatches them accordingly before collecting results and sending them back to the client.
Use cases
- Cut down on cross-service "chatter", especially in microservice architecture where operations require coordination between many small services.
- Decrease latency (if your service is complex and users already rely on high latency networks like mobile.)
Techniques & considerations
Gateways are simple, but if yours isn't designed well you'll have built a potential point of failure. Make sure your gateway can handle the anticipated load and scale as you grow. Implement reliable design techniques like circuit breakers or retries and be sure to load test the gateway. If it performs multiple functions, you might want to add an aggregation service in front of the gateway, freeing it up to perform its other functions and route requests correctly and quickly.
Fundamentals review
If you haven't already, check out the following lessons on system design fundamentals that relate to system availability.
Web Protocols Load Balancers APIs Replication Authentication and Authorization Cloud Architecture
20 - Top engineering blogs to read
We always recommend reading through your target company's engineering blog to get an understanding of the challenges their teams face, their system architecture, and company engineering culture. Look for yours in the list below.
- Airbnb Engineering
- Atlassian Developers
- AWS Blog
- Bitly Engineering Blog
- Box Blogs
- Dropbox Tech Blog
- Engineering at Quora
- Ebay Tech Blog
- Evernote Tech Blog
- Etsy Code as Craft
- Facebook Engineering
- Figma Engineering
- Flickr Code
- GitHub Engineering Blog
- Google Research Blog
- Groupon Engineering Blog
- Heroku Engineering Blog
- Hubspot Engineering Blog
- Instagram Engineering
- Intel Software Blog
- LinkedIn Engineering
- Lyft Engineering Blog
- Microsoft Engineering
- Microsoft Python Engineering
- Netflix Tech Blog
- Paypal Developer Blog
- Pinterest Engineering Blog
- Reddit Blog
- Robinhood Engineering Blog
- Salesforce Engineering Blog
- Shopify Engineering Blog
- Slack Engineering Blog
- Snap Engineering Blog
- Spotify Labs
- Stripe Engineering Blog
- Twilio Engineering Blog
- Twitter Engineering
- Uber Engineering Blog
- Yahoo Engineering Blog
- Yelp Engineering Blog
- Zynga Engineering Blog
21 - System design glossary
Here are some technical concepts and system design fundamentals that will help you ace your interview.
- API: Application Programming Interface. Think of this as the way a software system interacts with other systems/ people. For instance, an ATM's "API" includes adding money, withdrawing money, and a few other functions.
- Back-end: The back-end often refers to the server-side of development (e.g. an algorithm to show recommended pages would be hosted on the server).
- Cache: A cache is a software component that helps store information or content so that requests can be quicker. As a simple example, it's easier and quicker to get information from short-term memory than long-term storage via a cache.
- CDN: Content delivery network. This is a network of proxy servers and data centers that provides content to servers. CDNs are used to deliver content efficiently and quickly to clients that results in faster load times with high-traffic sites.
- Client: Clients are one part of the client-server model, where clients (e.g. a local computer) initiates a communication session with a server (e.g. a company server hosted on Amazon EC2).
- CMS: Content management system. This is a system for storing content, and is often hosted inside / used as a database.
- Cookie: A cookie is a piece of data stored on a client's browser from sites a client visits. This data includes volunteered information including visited pages. A common function of a cookie is to help users not have to log in every time they visit a site.
- Database/DBMS: Database management system. This is a software that allows users to create, read, and update entries in a database. For instance, Exponent's user database stores a list of user emails and passwords for each user to log in.
- DNS: Domain name system. This is a naming system to help map domain names to IP Addresses and other pieces of information across the internet.
- Front-end: The front-end often refers to the client-side of development (e.g. the page you're reading right now and how it's formatted).
- Latency: This refers to the load time of an experience. For instance, the latency would be considered high if it takes a long time to download large image files to load a page.
- Load Balancer: Load balancers help to distribute a task over a series of resources as opposed to overloading one resource. This is helpful when there's a risk of a high-traffic data source overloading a particular resource.
- Mobile Web / Native: "Native" often refers to apps downloaded to a smartphone or computer. Web apps are those that are accessed via a URL. For instance, the Facebook app is a native app. The Facebook.com on a mobile Google Chrome browser in one’s smartphone is on the mobile web platform.
- NoSQL: NoSQL ("not only SQL") databases is an alternative to relational databases in that they provide mechanisms for access without tabular relations.
- Refactor: A restructuring of the existing computer code. There are a variety of reasons for a code refactor. Often, refactors are advantageous because they accelerate product development or reduce vulnerabilities.
- REST/RESTful: Stands for Representational State Transfer. REST-compliant systems are stateless, meaning that the client and the server can be implemented independently of one another. Check out this article to learn more.
- Server: Servers provide functions to one or many clients. For instance, a web server serves web pages to clients (e.g. local computers, like the one you're reading this on!)
- Sharding: Sharding is the act of partitioning databases into smaller data shards, to optimize for database speed.