PostgreSQL Exercises
Getting Started
Introduction to the dataset
The dataset for these exercises is for a newly created country club, with a set of members, facilities such as tennis courts, and booking history for those facilities. The Entity Relationship Diagram for this dataset is shown below:
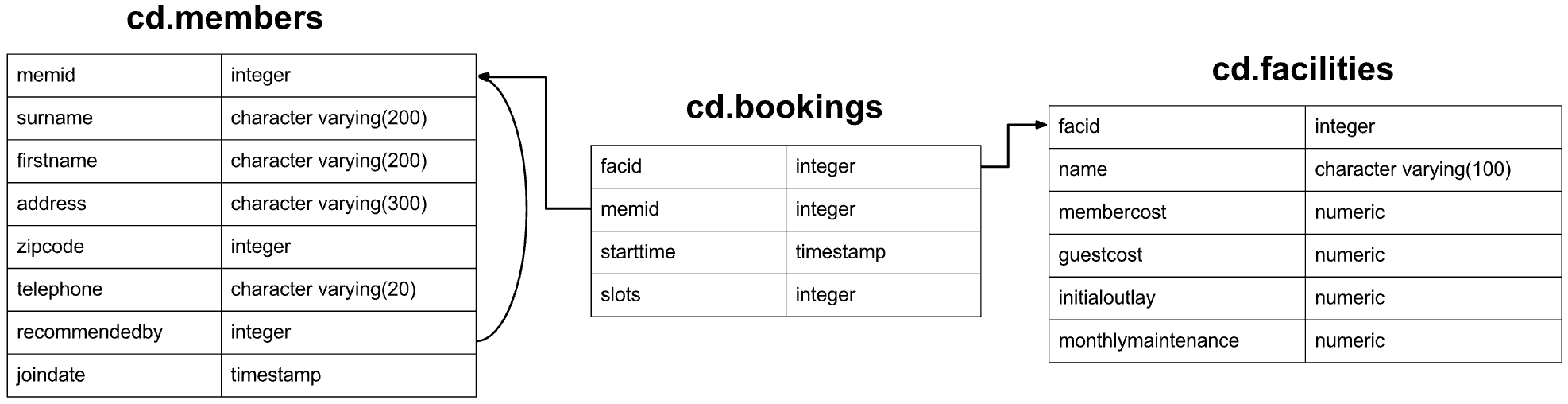
Amongst other things, the club wants to understand how they can use their information to analyse facility usage/demand.
The dataset is designed purely for supporting an interesting array of exercises, and the database schema is flawed in several aspects - please don't take it as an example of good design.
Members table
We'll start off with a look at the cd.members table:
CREATE TABLE cd.members (
memid integer NOT NULL,
surname character varying(200) NOT NULL,
firstname character varying(200) NOT NULL,
address character varying(300) NOT NULL,
zipcode integer NOT NULL,
telephone character varying(20) NOT NULL,
recommendedby integer,
joindate timestamp NOT NULL,
CONSTRAINT members_pk PRIMARY KEY (memid),
CONSTRAINT fk_members_recommendedby FOREIGN KEY (recommendedby)
REFERENCES cd.members(memid) ON DELETE SET NULL
);
Each member has an ID memid (not guaranteed to be sequential), basic address information (surname, firstname, address, zipcode, telephone), a reference (recommendedby) to the member that recommended them (if any), and a timestamp for when they joined (joindate). The addresses in the dataset are entirely (and unrealistically) fabricated.
Facilities table
The cd.facilities table definition is as follows:
CREATE TABLE cd.facilities (
facid integer NOT NULL,
name character varying(100) NOT NULL,
membercost numeric NOT NULL,
guestcost numeric NOT NULL,
initialoutlay numeric NOT NULL,
monthlymaintenance numeric NOT NULL,
CONSTRAINT facilities_pk PRIMARY KEY (facid)
);
The facilities table lists all the bookable facilities that the country club possesses. The club stores id/name information (facid, name), the cost to book both members and guests (membercost, guestcost), the initial cost to build the facility (initialoutlay), and estimated monthly upkeep costs (monthlymaintenance). They hope to use this information to track how financially worthwhile each facility is.
Bookings table
The cd.bookings table definition is as follows:
CREATE TABLE cd.bookings (
bookid integer NOT NULL,
facid integer NOT NULL,
memid integer NOT NULL,
starttime timestamp NOT NULL,
slots integer NOT NULL,
CONSTRAINT bookings_pk PRIMARY KEY (bookid),
CONSTRAINT fk_bookings_facid FOREIGN KEY (facid) REFERENCES cd.facilities(facid),
CONSTRAINT fk_bookings_memid FOREIGN KEY (memid) REFERENCES cd.members(memid)
);
The cd.bookings table is for tracking bookings of facilities. The table stores the facility id (facid), the member who made the booking (memid), the start of the booking (starttime), and how many half hour 'slots' the booking was made for (slots). This idiosyncratic design will make certain queries more difficult, but should provide you with some interesting challenges - as well as prepare you for the horror of working with some real-world databases.
I want to use my own Postgres system
No problem! Getting up and running isn't too hard. First, you'll need an install of PostgreSQL, which you can get from the official Postgres site. Once you have it started, download the PostgreSQL Exercises SQL.
Finally, run
psql -U <username> -f clubdata.sql -d postgres -x -q
to create the exercises database, the Postgres pgexercises user, the tables, and to load the data in. Note that you may find that the sort order of your results differs from those shown on the web site: that's probably because your Postgres is set up using a different locale to that used by PGExercises (which uses the C locale)
When you're running queries, you may find psql a little clunky. If so, I recommend trying out pgAdmin or the Eclipse database development tools.
Basic
Intro
This category deals with the basics of SQL. It covers SELECT and WHERE clauses, CASE expressions, UNIONs, and a few other odds and ends. If you're already educated in SQL you will probably find these exercises fairly easy. If not, you should find them a good point to start learning for the more difficult categories ahead!
If you struggle with these questions, I strongly recommend Learning SQL, by Alan Beaulieu, as a concise and well-written book on the subject. If you're interested in the fundamentals of database systems (as opposed to just how to use them), you should also investigate An Introduction to Database Systems by C.J. Date.
Retrieve everything from a table
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you retrieve all information from the cd.facilities table (the order of the result set does not matter)?
┌───────┬─────────────────┬────────────┬───────────┬───────────────┬────────────────────┐
│ facid │ name │ membercost │ guestcost │ initialoutlay │ monthlymaintenance │
├───────┼─────────────────┼────────────┼───────────┼───────────────┼────────────────────┤
│ 0 │ Tennis Court 1 │ 5 │ 25 │ 10000 │ 200 │
│ 1 │ Tennis Court 2 │ 5 │ 25 │ 8000 │ 200 │
│ 2 │ Badminton Court │ 0 │ 15.5 │ 4000 │ 50 │
│ 3 │ Table Tennis │ 0 │ 5 │ 320 │ 10 │
│ 4 │ Massage Room 1 │ 35 │ 80 │ 4000 │ 3000 │
│ 5 │ Massage Room 2 │ 35 │ 80 │ 4000 │ 3000 │
│ 6 │ Squash Court │ 3.5 │ 17.5 │ 5000 │ 80 │
│ 7 │ Snooker Table │ 0 │ 5 │ 450 │ 15 │
│ 8 │ Pool Table │ 0 │ 5 │ 400 │ 15 │
└───────┴─────────────────┴────────────┴───────────┴───────────────┴────────────────────┘
(9 rows)
SELECT * can be used to retrieve all columns from a table.
SELECT
F.*
FROM
cd.facilities F;
In general, it is best to explicitly name columns in the SELECT query instead of the * catch-all. This answer discusses this issue a bit more. Essentially, * is useful when testing things and debugging, but naming the columns is good for portability (if your table is updated in the future, * will result in grabbing everything from the updated table, intentional or not).
SELECT
*
FROM
cd.facilities;
The SELECT statement is the basic starting block for queries that read information out of the database. A minimal SELECT statement is generally comprised of SELECT [some set of columns] FROM [some table or group of tables].
In this case, we want all of the information from the cd.facilities table. The FROM part is easy--we just need to specify the cd.facilities table. cd is the table's schema (i.e., a term used for a logical grouping of related information in the database).
Next, we need to specify that we want all of the columns. Conveniently, there's a shorthand for "all columns": *. We can use this instead of laboriously specifying all the column names.
Retrieve specific columns from a table
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
You want to print out a list of all of the facilities and their cost to members. How would you retrieve a list of only facility names and costs? Order does not matter.
┌─────────────────┬────────────┐
│ name │ membercost │
├─────────────────┼────────────┤
│ Tennis Court 1 │ 5 │
│ Tennis Court 2 │ 5 │
│ Badminton Court │ 0 │
│ Table Tennis │ 0 │
│ Massage Room 1 │ 35 │
│ Massage Room 2 │ 35 │
│ Squash Court │ 3.5 │
│ Snooker Table │ 0 │
│ Pool Table │ 0 │
└─────────────────┴────────────┘
(9 rows)
The SELECT statement allows you to specify which column names to retrieve.
SELECT
F.name,
F.membercost
FROM
cd.facilities F;
This is generally the way you want to go (i.e., specifying the column names as opposed to just supplying * to grab everything). It is safer and more performant.
SELECT
name,
membercost
FROM
cd.facilities;
For this question, we need to specify the columns that we want. We can do that with a simple comma-delimited list of column names specified to the SELECT statement. All the database does is look at the columns available in the FROM clause, and return the ones we asked for, as illustrated below.
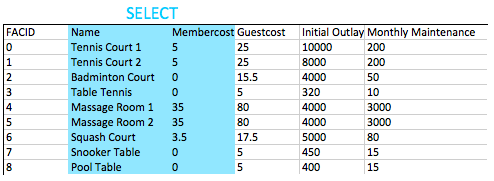
Generally speaking, for non-throwaway queries it's considered desirable to specify the names of the columns you want in your queries rather than using *. This is because your application might not be able to cope if more columns get added into the table.
Control which rows are retrieved
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you produce a list of facilities that charge a fee to members?
┌───────┬────────────────┬────────────┬───────────┬───────────────┬────────────────────┐
│ facid │ name │ membercost │ guestcost │ initialoutlay │ monthlymaintenance │
├───────┼────────────────┼────────────┼───────────┼───────────────┼────────────────────┤
│ 0 │ Tennis Court 1 │ 5 │ 25 │ 10000 │ 200 │
│ 1 │ Tennis Court 2 │ 5 │ 25 │ 8000 │ 200 │
│ 4 │ Massage Room 1 │ 35 │ 80 │ 4000 │ 3000 │
│ 5 │ Massage Room 2 │ 35 │ 80 │ 4000 │ 3000 │
│ 6 │ Squash Court │ 3.5 │ 17.5 │ 5000 │ 80 │
└───────┴────────────────┴────────────┴───────────┴───────────────┴────────────────────┘
(5 rows)
The WHERE clause allows you to filter the rows that you want to retrieve.
SELECT
F.*
FROM
cd.facilities F
WHERE
F.membercost > 0;
SELECT
*
FROM
cd.facilities
WHERE
membercost > 0;
The FROM clause is used to build up a set of candidate rows to read results from. In our examples so far, this set of rows has simply been the contents of a table. In the future we will explore joining tables, which allows us to create much more interesting candidates.
Once we've built up our set of candidate rows, the WHERE clause allows us to filter for the rows we're interested in, namely those with a membercost of more than zero in this case. As you will see in later exercises, WHERE clauses can have multiple components combined with boolean logic; it's possible, for instance, to search for facilities with a cost greater than 0 and less than 10. The filtering action of the WHERE clause on the facilities table is illustrated below:
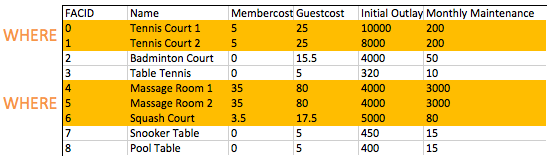
Control which rows are retrieved - part 2
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you produce a list of facilities that charge a fee to members, and that fee is less than 1/50th of the monthly maintenance cost? Return the facility id, facility name, member cost, and monthly maintenance of the facilities in question.
┌───────┬────────────────┬────────────┬────────────────────┐
│ facid │ name │ membercost │ monthlymaintenance │
├───────┼────────────────┼────────────┼────────────────────┤
│ 4 │ Massage Room 1 │ 35 │ 3000 │
│ 5 │ Massage Room 2 │ 35 │ 3000 │
└───────┴────────────────┴────────────┴────────────────────┘
(2 rows)
The WHERE clause allows you to filter the rows that you want to retrieve.
SELECT
F.facid,
F.name,
F.membercost,
F.monthlymaintenance
FROM
cd.facilities F
WHERE
F.membercost > 0
AND F.membercost < (F.monthlymaintenance * 1/50);
You have to be somewhat careful here due to how integer division works in PostgreSQL. Specifically, replacing D.monthlymaintenance * 1/50 above with 1/50 * F.monthlymaintenance will result in an empty result set. This is because 1/50 resolves to 0 since both are of type integer. But monthlymaintenance is of type numeric. Hence, we should aim to be clear with our implementation of "1/50"th--we can do something like monthlymaintenance/50.0 where 50.0 implicitly instructs Postgres to treat 50 as a numeric type.
The Postgres docs note that division for integral types truncates the result towards zero.
SELECT
facid,
name,
membercost,
monthlymaintenance
FROM
cd.facilities
WHERE
membercost > 0
AND (membercost < monthlymaintenance / 50.0);
The WHERE clause allows us to filter for the rows we're interested in, namely those with a membercost of more than zero AND a membercost of less than 1/50th of the monthly maintenance cost in this case. As you can see, the massage rooms are very expensive to run thanks to staffing costs!
When we want to test for two or more conditions, we use AND to combine them. We can, as you might expect, use OR to test whether either of a pair of conditions is true.
You might have noticed that this is our first query that combines a WHERE clause with selecting specific columns. You can see in the image below the effect of this: the intersection of the selected columns and the selected rows gives us the data to return. This may not seem too interesting now, but as we add in more complex operations like joins later, you'll see the simple elegance of this behaviour.
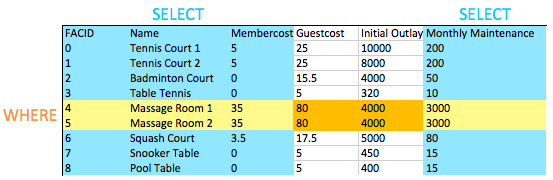
Basic string searches
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you produce a list of all facilities with the word 'Tennis' in their name?
┌───────┬────────────────┬────────────┬───────────┬───────────────┬────────────────────┐
│ facid │ name │ membercost │ guestcost │ initialoutlay │ monthlymaintenance │
├───────┼────────────────┼────────────┼───────────┼───────────────┼────────────────────┤
│ 0 │ Tennis Court 1 │ 5 │ 25 │ 10000 │ 200 │
│ 1 │ Tennis Court 2 │ 5 │ 25 │ 8000 │ 200 │
│ 3 │ Table Tennis │ 0 │ 5 │ 320 │ 10 │
└───────┴────────────────┴────────────┴───────────┴───────────────┴────────────────────┘
(3 rows)
Try looking up the SQL LIKE operator.
SELECT
F.*
FROM
cd.facilities F
WHERE
F.name LIKE '%Tennis%';
SELECT
*
FROM
cd.facilities
WHERE
name LIKE '%Tennis%';
SQL's LIKE operator provides simple pattern matching on strings. It's pretty much universally implemented, and is nice and simple to use - it just takes a string with the % character matching any string, and _ matching any single character. In this case, we're looking for names containing the word 'Tennis', so putting a % on either side fits the bill.
There's other ways to accomplish this task: Postgres supports regular expressions with the ~ operator, for example. Use whatever makes you feel comfortable, but do be aware that the LIKE operator is much more portable between systems.
Also be aware that Postgres, unlike MySQL or SQL Server for instance, is case-sensitive. Postgres has an ILIKE operator which can be used to make the pattern matching case-insensitive.
Matching against multiple possible values
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you retrieve the details of facilities with ID 1 and 5? Try to do it without using the OR operator.
┌───────┬────────────────┬────────────┬───────────┬───────────────┬────────────────────┐
│ facid │ name │ membercost │ guestcost │ initialoutlay │ monthlymaintenance │
├───────┼────────────────┼────────────┼───────────┼───────────────┼────────────────────┤
│ 1 │ Tennis Court 2 │ 5 │ 25 │ 8000 │ 200 │
│ 5 │ Massage Room 2 │ 35 │ 80 │ 4000 │ 3000 │
└───────┴────────────────┴────────────┴───────────┴───────────────┴────────────────────┘
(2 rows)
Try looking up the SQL IN operator.
SELECT
F.*
FROM
cd.facilities F
WHERE
F.facid IN (1,5);
SELECT
*
FROM
cd.facilities
WHERE
facid IN (1,5);
The obvious answer to this question is to use a WHERE clause that looks like WHERE facid = 1 OR facid = 5. An alternative that is easier with large numbers of possible matches is the IN operator. The IN operator takes a list of possible values, and matches them against (in this case) the facid. If one of the values matches, the WHERE clause is true for that row, and the row is returned.
The IN operator is a good early demonstrator of the elegance of the relational model. The argument it takes is not just a list of values - it's actually a table with a single column. Since queries also return tables, if you create a query that returns a single column, then you can feed those results into an IN operator. To give a toy example:
SELECT
*
FROM
cd.facilities
WHERE
facid IN (SELECT facid FROM cd.facilities);
This example is functionally equivalent to just selecting all the facilities, but shows you how to feed the results of one query into another. The inner query is called a subquery and we will learn more about those later.
Classify results into buckets
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you produce a list of facilities, with each labelled as 'cheap' or 'expensive' depending on if their monthly maintenance cost is more than $100? Return the name of the facilities in question as well as a cost column that specifies whether the booking is 'cheap' or 'expensive' based on the parameters outlined above.
┌─────────────────┬───────────┐
│ name │ cost │
├─────────────────┼───────────┤
│ Tennis Court 1 │ expensive │
│ Tennis Court 2 │ expensive │
│ Badminton Court │ cheap │
│ Table Tennis │ cheap │
│ Massage Room 1 │ expensive │
│ Massage Room 2 │ expensive │
│ Squash Court │ cheap │
│ Snooker Table │ cheap │
│ Pool Table │ cheap │
└─────────────────┴───────────┘
(9 rows)
SELECT
F.name,
(CASE
WHEN F.monthlymaintenance > 100 THEN 'expensive'
ELSE 'cheap'
END) AS cost
FROM
cd.facilities F;
SELECT
name,
CASE
WHEN (monthlymaintenance > 100) THEN 'expensive'
ELSE 'cheap'
END AS cost
FROM
cd.facilities;
This exercise contains a few new concepts. The first is the fact that we're doing computation in the area of the query between SELECT and FROM. Previously we've only used this to select columns that we want to return, but you can put anything in here that will produce a single result per returned row - including subqueries.
The second new concept is the CASE statement itself. CASE is effectively like if/switch statements in other languages, with a form as shown in the query. To add a 'middling' option, we would simply insert another WHEN ...THEN section.
Finally, there's the AS operator. This is simply used to label columns or expressions (i.e., it is a so-called column alias), to make them display more nicely or to make them easier to reference when used as part of a subquery.
Working with dates
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you produce a list of members who joined after the start of September 2012? Return the memid, surname, firstname, and joindate of the members in question.
┌───────┬───────────────────┬───────────┬─────────────────────┐
│ memid │ surname │ firstname │ joindate │
├───────┼───────────────────┼───────────┼─────────────────────┤
│ 24 │ Sarwin │ Ramnaresh │ 2012-09-01 08:44:42 │
│ 26 │ Jones │ Douglas │ 2012-09-02 18:43:05 │
│ 27 │ Rumney │ Henrietta │ 2012-09-05 08:42:35 │
│ 28 │ Farrell │ David │ 2012-09-15 08:22:05 │
│ 29 │ Worthington-Smyth │ Henry │ 2012-09-17 12:27:15 │
│ 30 │ Purview │ Millicent │ 2012-09-18 19:04:01 │
│ 33 │ Tupperware │ Hyacinth │ 2012-09-18 19:32:05 │
│ 35 │ Hunt │ John │ 2012-09-19 11:32:45 │
│ 36 │ Crumpet │ Erica │ 2012-09-22 08:36:38 │
│ 37 │ Smith │ Darren │ 2012-09-26 18:08:45 │
└───────┴───────────────────┴───────────┴─────────────────────┘
(10 rows)
Look up the SQL TIMESTAMP format, and remember that you can compare dates much like you would integer values.
SELECT
M.memid,
M.surname,
M.firstname,
M.joindate
FROM
cd.members M
WHERE
M.joindate >= '2012-09-01';
SELECT
memid,
surname,
firstname,
joindate
FROM
cd.members
WHERE
joindate >= '2012-09-01';
This is our first look at SQL timestamps. They're formatted in descending order of magnitude: YYYY-MM-DD HH:MM:SS.nnnnnn. We can compare them just like we might a unix timestamp, although getting the differences between dates is a little more involved (and powerful!). In this case, we've just specified the date portion of the timestamp. This gets automatically cast by Postgres into the full timestamp 2012-09-01 00:00:00.
Removing duplicates, and ordering results
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you produce an ordered list of the first 10 surnames in the members table? The list must not contain duplicates.
┌─────────┐
│ surname │
├─────────┤
│ Bader │
│ Baker │
│ Boothe │
│ Butters │
│ Coplin │
│ Crumpet │
│ Dare │
│ Farrell │
│ GUEST │
│ Genting │
└─────────┘
(10 rows)
Look up SELECT DISTINCT, ORDER BY, and LIMIT.
SELECT DISTINCT
M.surname
FROM
cd.members M
ORDER BY
M.surname
LIMIT 10;
SELECT
DISTINCT surname
FROM
cd.members
ORDER BY
surname
LIMIT
10;
There's three new concepts here, but they're all pretty simple.
- Specifying
DISTINCTafterSELECTremoves duplicate rows from the result set. Note that this applies to rows: if rowAhas multiple columns, rowBis only equal to it if the values in all columns are the same. As a general rule, don't useDISTINCTin a willy-nilly fashion--it's not free to remove duplicates from large query result sets, so do it as-needed. - Specifying
ORDER BY(after theFROMandWHEREclauses, near the end of the query) allows results to be ordered by a column or set of columns (comma separated). - The
LIMITkeyword allows you to limit the number of results retrieved. This is useful for getting results a page at a time, and can be combined with theOFFSETkeyword to get following pages. This is the same approach used by MySQL and is very convenient - you may, unfortunately, find that this process is a little more complicated in other DBs.
Combining results from multiple queries
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
You, for some reason, want a combined list of all surnames and all facility names. Yes, this is a contrived example. Produce that list! The listing of surnames and names should have a column title of surname.
┌───────────────────┐
│ surname │
├───────────────────┤
│ Hunt │
│ Farrell │
│ Tennis Court 2 │
│ Table Tennis │
│ Dare │
│ Rownam │
│ GUEST │
│ Badminton Court │
│ Smith │
│ Tupperware │
│ Owen │
│ Worthington-Smyth │
│ Butters │
│ Rumney │
│ Tracy │
│ Crumpet │
│ Purview │
│ Massage Room 2 │
│ Sarwin │
│ Baker │
│ Pool Table │
│ Snooker Table │
│ Jones │
│ Coplin │
│ Mackenzie │
│ Boothe │
│ Joplette │
│ Stibbons │
│ Squash Court │
│ Tennis Court 1 │
│ Pinker │
│ Genting │
│ Bader │
│ Massage Room 1 │
└───────────────────┘
(34 rows)
Look up the SQL keyword UNION.
SELECT M.surname FROM cd.members M
UNION
SELECT F.name FROM cd.facilities F;
SELECT
surname
FROM
cd.members
UNION
SELECT
name
FROM
cd.facilities;
The UNION operator does what you might expect: combines the results of two SQL queries into a single table. The caveat is that both results from the two queries must have the same number of columns and compatible data types.
Additionally, the result set is not predictable in terms of what order records are returned in. To impose order, you can use ORDER BY after the second SELECT clause once everything has been unioned.
UNION removes duplicate rows, while UNION ALL does not. Use UNION ALL by default, unless you care about duplicate results.
Simple aggregation
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
You'd like to get the signup date of your last member. How can you retrieve this information? Return the single result under a column labelled latest.
┌─────────────────────┐
│ latest │
├─────────────────────┤
│ 2012-09-26 18:08:45 │
└─────────────────────┘
(1 row)
Look up the SQL aggregate function MAX.
The normal approach might be something like
SELECT
M.joindate AS latest
FROM
cd.members M
ORDER BY
M.joindate DESC
LIMIT 1;
but aggregate functions can work on not just numbers but dates as well:
SELECT
MAX(M.joindate) AS latest
FROM
cd.members M;
SELECT
MAX(joindate) AS latest
FROM
cd.members;
This is our first foray into SQL's aggregate functions. They're used to extract information about whole groups of rows, and allow us to easily ask questions like:
- What's the most expensive facility to maintain on a monthly basis?
- Who has recommended the most new members?
- How much time has each member spent at our facilities?
The MAX aggregate function here is very simple: it receives all the possible values for joindate, and outputs the one that's biggest. There's a lot more power to aggregate functions, which you will come across in future exercises.
More aggregation
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
You'd like to get the first and last name of the last member(s) who signed up - not just the date. How can you do that?
┌───────────┬─────────┬─────────────────────┐
│ firstname │ surname │ joindate │
├───────────┼─────────┼─────────────────────┤
│ Darren │ Smith │ 2012-09-26 18:08:45 │
└───────────┴─────────┴─────────────────────┘
(1 row)
The LIMIT keyword may be helpful. You may also find a subquery to be quite useful in getting this done.
Probably the most straightforward way to accomplish this is as follows:
SELECT
M.firstname,
M.surname,
M.joindate
FROM
cd.members M
ORDER BY
M.joindate DESC
LIMIT 1;
But using a subquery adds some flair:
SELECT
M1.firstname,
M1.surname,
M1.joindate
FROM
cd.members M1
WHERE
M1.joindate = (SELECT MAX(M2.joindate) FROM cd.members M2);
Note that the first solution, which uses LIMIT 1, is functionally different from the second solution. They do not do the same things. For example, suppose there are multiple people who signed up at the same time and that time happens to be the last time anyone signed up. Then it is technically true that several members were last in signing up.
The first solution would only return a single member whereas the subqeury solution would return all members.
SELECT
firstname,
surname,
joindate
FROM
cd.members
WHERE
joindate = (
SELECT
MAX(joindate)
FROM
cd.members
);
In the suggested approach above, you use a subquery to find out what the most recent joindate is. This subquery returns a scalar table - that is, a table with a single column and a single row. Since we have just a single value, we can substitute the subquery anywhere we might put a single constant value. In this case, we use it to complete the WHERE clause of a query to find a given member.
You might hope that you'd be able to do something like below:
SELECT
firstname,
surname,
MAX(joindate)
FROM
cd.members;
Unfortunately, this doesn't work. The MAX function doesn't restrict rows like the WHERE clause does - it simply takes in a bunch of values and returns the biggest one. The database is then left wondering how to pair up a long list of names with the single joindate that's come out of the MAX function, and fails. Instead, you're left having to say 'find me the row(s) which have a joindate that's the same as the maximum joindate'.
As mentioned by the hint, there's other ways to get this job done - one example is below. In this approach, rather than explicitly finding out what the last joined date is, we simply order our members table in descending order of join date, and pick off the first one. Note that this approach does not cover the extremely unlikely eventuality of two people joining at the exact same time.
SELECT
firstname,
surname,
joindate
FROM
cd.members
ORDER BY
joindate DESC
LIMIT
1;
Joins and Subqueries
Intro
This category deals primarily with a foundational concept in relational database systems: joining. Joining allows you to combine related information from multiple tables to answer a question. This isn't just beneficial for ease of querying: a lack of join capability encourages denormalisation of data, which increases the complexity of keeping your data internally consistent.
This topic covers INNER, OUTER, and SELF joins, as well as spending a little time on subqueries (queries within queries). If you struggle with these questions, I strongly recommend Learning SQL, by Alan Beaulieu, as a concise and well-written book on the subject.
Retrieve the start times of members' bookings
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you produce a list of the start times for bookings by members named 'David Farrell'?
┌─────────────────────┐
│ starttime │
├─────────────────────┤
│ 2012-09-18 09:00:00 │
│ 2012-09-18 13:30:00 │
│ 2012-09-18 17:30:00 │
│ 2012-09-18 20:00:00 │
│ 2012-09-19 09:30:00 │
│ 2012-09-19 12:00:00 │
│ 2012-09-19 15:00:00 │
│ 2012-09-20 11:30:00 │
│ 2012-09-20 14:00:00 │
│ 2012-09-20 15:30:00 │
│ 2012-09-21 10:30:00 │
│ 2012-09-21 14:00:00 │
│ 2012-09-22 08:30:00 │
│ 2012-09-22 17:00:00 │
│ 2012-09-23 08:30:00 │
│ 2012-09-23 17:30:00 │
│ 2012-09-23 19:00:00 │
│ 2012-09-24 08:00:00 │
│ 2012-09-24 12:30:00 │
│ 2012-09-24 16:30:00 │
│ 2012-09-25 15:30:00 │
│ 2012-09-25 17:00:00 │
│ 2012-09-26 13:00:00 │
│ 2012-09-26 17:00:00 │
│ 2012-09-27 08:00:00 │
│ 2012-09-28 09:30:00 │
│ 2012-09-28 11:30:00 │
│ 2012-09-28 13:00:00 │
│ 2012-09-29 10:30:00 │
│ 2012-09-29 13:30:00 │
│ 2012-09-29 14:30:00 │
│ 2012-09-29 16:00:00 │
│ 2012-09-29 17:30:00 │
│ 2012-09-30 14:30:00 │
└─────────────────────┘
(34 rows)
Take a look at the documentation for INNER JOIN.
SELECT
B.starttime
FROM
cd.members M
INNER JOIN cd.bookings B ON M.memid = B.memid
WHERE
M.firstname = 'David'
AND M.surname = 'Farrell';
SELECT
bks.starttime
FROM
cd.bookings bks
INNER JOIN cd.members mems ON mems.memid = bks.memid
WHERE
mems.firstname = 'David'
AND mems.surname = 'Farrell';
The most commonly used kind of join is the INNER JOIN. What this does is combine two tables based on a join expression - in this case, for each member id in the members table, we're looking for matching values in the bookings table. Where we find a match, a row combining the values for each table is returned. Note that we've given each table an alias (bks and mems). This is used for two reasons: firstly, it's convenient, and secondly we might join to the same table several times, requiring us to distinguish between columns from each different time the table was joined in.
Let's ignore our SELECT and WHERE clauses for now, and focus on what the FROM statement produces. In all our previous examples, FROM has just been a simple table. What is it now? Another table! This time, it's produced as a composite of bookings and members. You can see a subset of the output of the join below:

For each member in the members table, the join has found all the matching member ids in the bookings table. For each match, it's then produced a row combining the row from the members table, and the row from the bookings table.
Obviously, this is too much information on its own, and any useful question will want to filter it down. In our query, we use the start of the SELECT clause to pick columns, and the WHERE clause to pick rows, as illustrated below:

That's all we need to find David's bookings! In general, I encourage you to remember that the output of the FROM clause is essentially one big table that you then filter information out of. This may sound inefficient - but don't worry, under the covers the DB will be behaving much more intelligently.
One final note: there's two different syntaxes for inner joins. I've shown you the one I prefer, that I find more consistent with other join types. You'll commonly see a different syntax, shown below:
SELECT
bks.starttime
FROM
cd.bookings bks,
cd.members mems
WHERE
mems.firstname = 'David'
AND mems.surname = 'Farrell'
AND mems.memid = bks.memid;
This is functionally exactly the same as the approved answer. If you feel more comfortable with this syntax, feel free to use it!
Work out the start times of bookings for tennis courts
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you produce a list of the start times for bookings for tennis courts, for the date '2012-09-21'? Return a list of start time and facility name pairings, ordered by the time (ascending).
┌─────────────────────┬────────────────┐
│ start │ name │
├─────────────────────┼────────────────┤
│ 2012-09-21 08:00:00 │ Tennis Court 1 │
│ 2012-09-21 08:00:00 │ Tennis Court 2 │
│ 2012-09-21 09:30:00 │ Tennis Court 1 │
│ 2012-09-21 10:00:00 │ Tennis Court 2 │
│ 2012-09-21 11:30:00 │ Tennis Court 2 │
│ 2012-09-21 12:00:00 │ Tennis Court 1 │
│ 2012-09-21 13:30:00 │ Tennis Court 1 │
│ 2012-09-21 14:00:00 │ Tennis Court 2 │
│ 2012-09-21 15:30:00 │ Tennis Court 1 │
│ 2012-09-21 16:00:00 │ Tennis Court 2 │
│ 2012-09-21 17:00:00 │ Tennis Court 1 │
│ 2012-09-21 18:00:00 │ Tennis Court 2 │
└─────────────────────┴────────────────┘
(12 rows)
This is another INNER JOIN. You may also want to think about using the IN or LIKE operators to limit the results you get back.
SELECT
B.starttime AS start,
F.name
FROM
cd.facilities F
INNER JOIN cd.bookings B ON F.facid = B.facid
WHERE
F.name ILIKE '%tennis court%'
AND starttime >= '2012-09-21'
AND starttime < '2012-09-22'
ORDER BY
starttime ASC;
SELECT
bks.starttime AS start,
facs.name AS name
FROM
cd.facilities facs
INNER JOIN cd.bookings bks ON facs.facid = bks.facid
WHERE
facs.name IN ('Tennis Court 2', 'Tennis Court 1')
AND bks.starttime >= '2012-09-21'
AND bks.starttime < '2012-09-22'
ORDER BY
bks.starttime;
This is another INNER JOIN query, although it has a fair bit more complexity in it! The FROM part of the query is easy - we're simply joining facilities and bookings tables together on the facid. This produces a table where, for each row in bookings, we've attached detailed information about the facility being booked.
On to the WHERE component of the query. The checks on starttime are fairly self explanatory - we're making sure that all the bookings start between the specified dates. Since we're only interested in tennis courts, we're also using the IN operator to tell the database system to only give us back facility IDs 0 or 1 - the IDs of the courts. There's other ways to express this: We could have used where facs.facid = 0 or facs.facid = 1, or even where facs.name like 'Tennis%'.
The rest is pretty simple: we SELECT the columns we're interested in, and ORDER BY the start time.
Produce a list of all members who have recommended another member
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you output a list of all members who have recommended another member? Ensure that there are no duplicates in the list, and that results are ordered by surname and then firstname.
┌───────────┬──────────┐
│ firstname │ surname │
├───────────┼──────────┤
│ Florence │ Bader │
│ Timothy │ Baker │
│ Gerald │ Butters │
│ Jemima │ Farrell │
│ Matthew │ Genting │
│ David │ Jones │
│ Janice │ Joplette │
│ Millicent │ Purview │
│ Tim │ Rownam │
│ Darren │ Smith │
│ Tracy │ Smith │
│ Ponder │ Stibbons │
│ Burton │ Tracy │
└───────────┴──────────┘
(13 rows)
You can use an INNER JOIN just like the previous exercise(s) or you can use a subquery.
There are multiple ways of going about this. Perhaps the clearest way is the subquery way:
SELECT DISTINCT
M1.firstname,
M1.surname
FROM
cd.members M1
WHERE
M1.memid IN (SELECT DISTINCT M2.recommendedby FROM cd.members M2 WHERE M2.recommendedby IS NOT NULL)
ORDER BY
M1.surname, M1.firstname;
The subquery
SELECT DISTINCT M2.recommendedby FROM cd.members M2 WHERE M2.recommendedby IS NOT NULL
retrieves all the distinct member IDs of those who have recommended people. This gives us the complete list of member IDs for the recommenders. Hence, to find the member info for the recommenders, we simply have to find the members whose IDs are in the list obtained by the subquery.
Another way of going about all of this is with a so-called "self-join" which is really just a joining technique that uses INNER JOIN to join a table with itself so as to compare rows within the same table.
In this case, a self-join is appropriate since the recommendedby field, if not empty, holds the member ID (memid) of another member whose information is in the same table (i.e., cd.members). The query
SELECT
recommendee.firstname,
recommendee.surname,
recommendee.recommendedby,
recommender.memid,
recommender.firstname,
recommender.surname
FROM
cd.members recommendee
INNER JOIN cd.members recommender ON recommendee.recommendedby = recommender.memid
ORDER BY
recommendee.surname, recommendee.firstname;
is quite informative in the result set it yields:
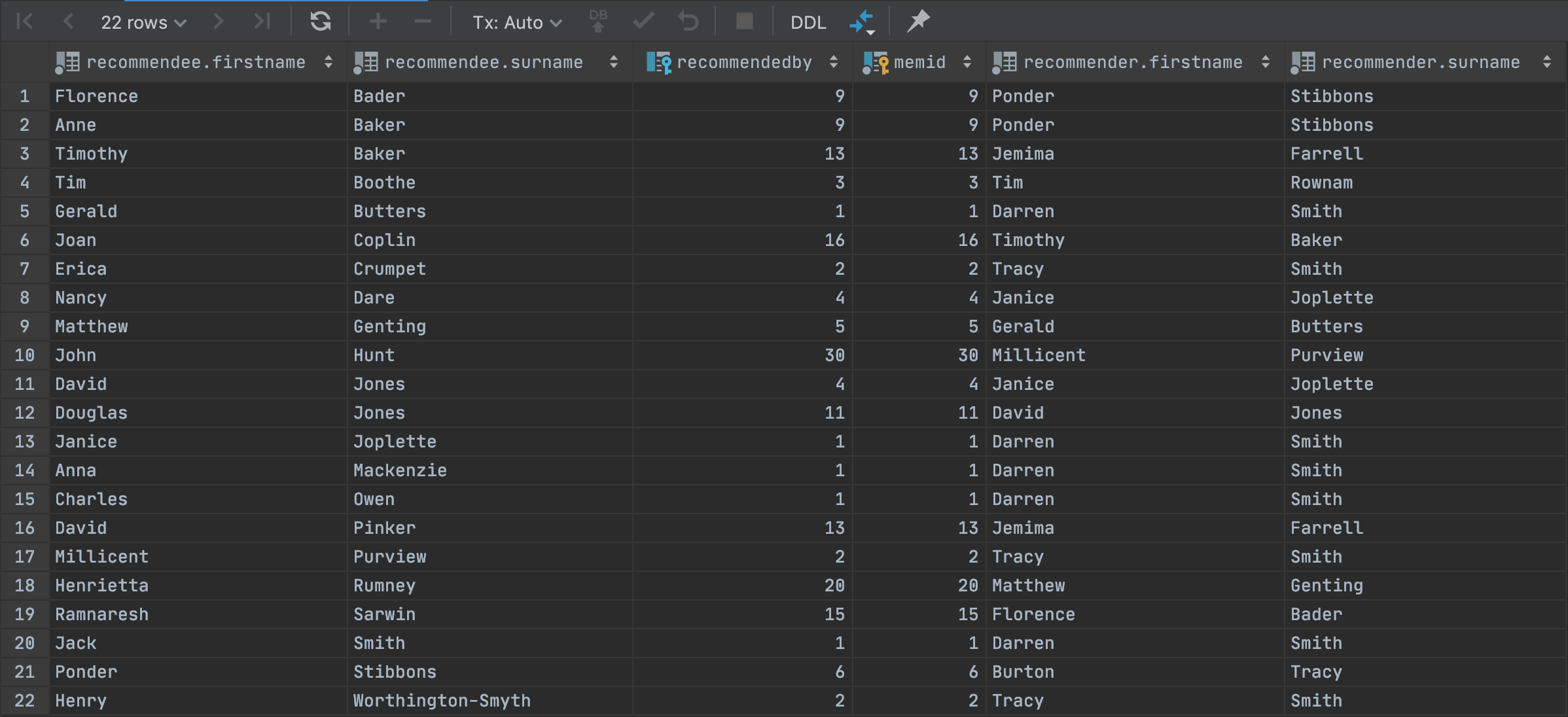
Specifically, for each person recommended (i.e., the recommendee) we see their recommender. Including the recommendedby and memid column values is helpful for illustrative purposes her to see exactly how the INNER JOIN is working.
For the purposes of this problem, we are asked to provide distinct recommender information which is now quite simple in light of the query and picture above:
SELECT DISTINCT
recommender.firstname,
recommender.surname
FROM
cd.members recommendee
INNER JOIN cd.members recommender ON recommendee.recommendedby = recommender.memid
ORDER BY
surname, firstname;
SELECT
DISTINCT recs.firstname AS firstname,
recs.surname AS surname
FROM
cd.members mems
INNER JOIN cd.members recs ON recs.memid = mems.recommendedby
ORDER BY
surname,
firstname;
Here's a concept that some people find confusing: you can join a table to itself! This is really useful if you have columns that reference data in the same table, like we do with recommendedby in cd.members.
If you're having trouble visualising this, remember that this works just the same as any other INNER JOIN. Our join takes each row in members that has a recommendedby value, and looks in members again for the row which has a matching member id. It then generates an output row combining the two members entries. This looks like the diagram below:

Note that while we might have two 'surname' columns in the output set, they can be distinguished by their table aliases. Once we've selected the columns that we want, we simply use DISTINCT to ensure that there are no duplicates.
Produce a list of all members, along with their recommender
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you output a list of all members, including the individual who recommended them (if any)? Ensure that results are ordered by (surname, firstname).
┌───────────┬───────────────────┬───────────┬──────────┐
│ memfname │ memsname │ recfname │ recsname │
├───────────┼───────────────────┼───────────┼──────────┤
│ Florence │ Bader │ Ponder │ Stibbons │
│ Anne │ Baker │ Ponder │ Stibbons │
│ Timothy │ Baker │ Jemima │ Farrell │
│ Tim │ Boothe │ Tim │ Rownam │
│ Gerald │ Butters │ Darren │ Smith │
│ Joan │ Coplin │ Timothy │ Baker │
│ Erica │ Crumpet │ Tracy │ Smith │
│ Nancy │ Dare │ Janice │ Joplette │
│ David │ Farrell │ │ │
│ Jemima │ Farrell │ │ │
│ GUEST │ GUEST │ │ │
│ Matthew │ Genting │ Gerald │ Butters │
│ John │ Hunt │ Millicent │ Purview │
│ David │ Jones │ Janice │ Joplette │
│ Douglas │ Jones │ David │ Jones │
│ Janice │ Joplette │ Darren │ Smith │
│ Anna │ Mackenzie │ Darren │ Smith │
│ Charles │ Owen │ Darren │ Smith │
│ David │ Pinker │ Jemima │ Farrell │
│ Millicent │ Purview │ Tracy │ Smith │
│ Tim │ Rownam │ │ │
│ Henrietta │ Rumney │ Matthew │ Genting │
│ Ramnaresh │ Sarwin │ Florence │ Bader │
│ Darren │ Smith │ │ │
│ Darren │ Smith │ │ │
│ Jack │ Smith │ Darren │ Smith │
│ Tracy │ Smith │ │ │
│ Ponder │ Stibbons │ Burton │ Tracy │
│ Burton │ Tracy │ │ │
│ Hyacinth │ Tupperware │ │ │
│ Henry │ Worthington-Smyth │ Tracy │ Smith │
└───────────┴───────────────────┴───────────┴──────────┘
(31 rows)
Try investigating the LEFT JOIN.
Recall the query used for illustrative purposes in the previous exercise:
SELECT
recommendee.firstname,
recommendee.surname,
recommendee.recommendedby,
recommender.memid,
recommender.firstname,
recommender.surname
FROM
cd.members recommendee
INNER JOIN cd.members recommender ON recommendee.recommendedby = recommender.memid
ORDER BY
recommendee.surname, recommendee.firstname;
This gave us a very informative result set:
We can see each recommendee and their correspondent recommender. But we are now being asked to produce a list of all members regardless of whether or not they have been recommended. The way we can accomplish this is instead of using the recommendee table alias for an INNER JOIN as in the query above, we can now use an allmembers table alias for a LEFT JOIN:
SELECT
allmembers.firstname,
allmembers.surname,
allmembers.recommendedby,
recommender.memid,
recommender.firstname,
recommender.surname
FROM
cd.members allmembers
LEFT JOIN cd.members recommender ON allmembers.recommendedby = recommender.memid
ORDER BY
allmembers.surname, allmembers.firstname;
We still get everything we got in the previous result set where we used recommendee for an INNER JOIN, but this time, using allmembers for a LEFT JOIN, we got all the members who had not actually been recommended as well:
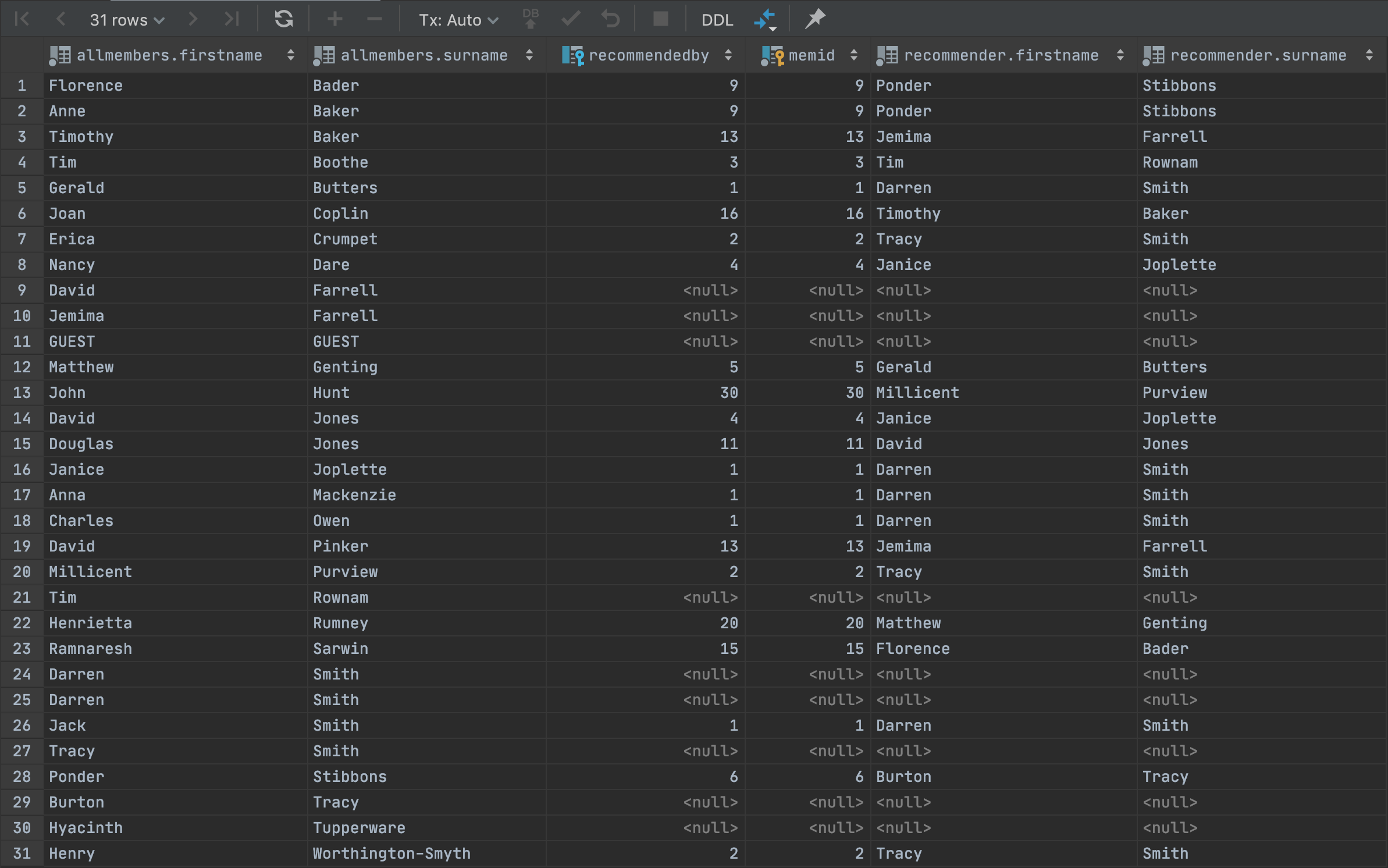
Now all we need to do is reshape our query to be formatted so we get the same expected results as in the exercise query:
SELECT
allmembers.firstname AS memfname,
allmembers.surname AS memsname,
recommender.firstname AS recfname,
recommender.surname AS recsname
FROM
cd.members allmembers
LEFT JOIN cd.members recommender ON allmembers.recommendedby = recommender.memid
ORDER BY
memsname, memfname;
Lastly, note how we can use column aliases as above to ORDER BY however we see fit and keep the syntax a bit briefer than it might be otherwise.
SELECT
mems.firstname AS memfname,
mems.surname AS memsname,
recs.firstname AS recfname,
recs.surname AS recsname
FROM
cd.members mems
LEFT OUTER JOIN cd.members recs ON recs.memid = mems.recommendedby
ORDER BY
memsname,
memfname;
Let's introduce another new concept: the LEFT OUTER JOIN. These are best explained by the way in which they differ from inner joins. Inner joins take a left and a right table, and look for matching rows based on a join condition (ON). When the condition is satisfied, a joined row is produced. A LEFT OUTER JOIN operates similarly, except that if a given row on the left hand table doesn't match anything, it still produces an output row. That output row consists of the left hand table row, and a bunch of NULLS in place of the right hand table row.
This is useful in situations like this question, where we want to produce output with optional data. We want the names of all members, and the name of their recommender if that person exists. You can't express that properly with an inner join.
As you may have guessed, there's other outer joins too. The RIGHT OUTER JOIN is much like the LEFT OUTER JOIN, except that the left hand side of the expression is the one that contains the optional data. The rarely-used FULL OUTER JOIN treats both sides of the expression as optional.
Produce a list of all members who have used a tennis court
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you produce a list of all members who have used a tennis court? Include in your output the name of the court, and the name of the member formatted as a single column. Ensure no duplicate data, and order by the member name followed by the facility name.
┌───────────────────┬────────────────┐
│ member │ facility │
├───────────────────┼────────────────┤
│ Anne Baker │ Tennis Court 1 │
│ Anne Baker │ Tennis Court 2 │
│ Burton Tracy │ Tennis Court 1 │
│ Burton Tracy │ Tennis Court 2 │
│ Charles Owen │ Tennis Court 1 │
│ Charles Owen │ Tennis Court 2 │
│ Darren Smith │ Tennis Court 2 │
│ David Farrell │ Tennis Court 1 │
│ David Farrell │ Tennis Court 2 │
│ David Jones │ Tennis Court 1 │
│ David Jones │ Tennis Court 2 │
│ David Pinker │ Tennis Court 1 │
│ Douglas Jones │ Tennis Court 1 │
│ Erica Crumpet │ Tennis Court 1 │
│ Florence Bader │ Tennis Court 1 │
│ Florence Bader │ Tennis Court 2 │
│ GUEST GUEST │ Tennis Court 1 │
│ GUEST GUEST │ Tennis Court 2 │
│ Gerald Butters │ Tennis Court 1 │
│ Gerald Butters │ Tennis Court 2 │
│ Henrietta Rumney │ Tennis Court 2 │
│ Jack Smith │ Tennis Court 1 │
│ Jack Smith │ Tennis Court 2 │
│ Janice Joplette │ Tennis Court 1 │
│ Janice Joplette │ Tennis Court 2 │
│ Jemima Farrell │ Tennis Court 1 │
│ Jemima Farrell │ Tennis Court 2 │
│ Joan Coplin │ Tennis Court 1 │
│ John Hunt │ Tennis Court 1 │
│ John Hunt │ Tennis Court 2 │
│ Matthew Genting │ Tennis Court 1 │
│ Millicent Purview │ Tennis Court 2 │
│ Nancy Dare │ Tennis Court 1 │
│ Nancy Dare │ Tennis Court 2 │
│ Ponder Stibbons │ Tennis Court 1 │
│ Ponder Stibbons │ Tennis Court 2 │
│ Ramnaresh Sarwin │ Tennis Court 1 │
│ Ramnaresh Sarwin │ Tennis Court 2 │
│ Tim Boothe │ Tennis Court 1 │
│ Tim Boothe │ Tennis Court 2 │
│ Tim Rownam │ Tennis Court 1 │
│ Tim Rownam │ Tennis Court 2 │
│ Timothy Baker │ Tennis Court 1 │
│ Timothy Baker │ Tennis Court 2 │
│ Tracy Smith │ Tennis Court 1 │
│ Tracy Smith │ Tennis Court 2 │
└───────────────────┴────────────────┘
(46 rows)
This answer requires multiple joins. To concatenate strings you can use the || operator.
SELECT DISTINCT
M.firstname || ' ' || M.surname AS member,
F.name AS facility
FROM
cd.members M
INNER JOIN cd.bookings B ON M.memid = B.memid
INNER JOIN cd.facilities F ON B.facid = F.facid
WHERE
F.name ILIKE '%tennis court%'
ORDER BY
member, facility;
SELECT
DISTINCT mems.firstname || ' ' || mems.surname AS member,
facs.name AS facility
FROM
cd.members mems
INNER JOIN cd.bookings bks ON mems.memid = bks.memid
INNER JOIN cd.facilities facs ON bks.facid = facs.facid
WHERE
facs.name IN ('Tennis Court 2', 'Tennis Court 1')
ORDER BY
member,
facility;
This exercise is largely a more complex application of what you've learned in prior questions. It's also the first time we've used more than one join, which may be a little confusing for some. When reading join expressions, remember that a join is effectively a function that takes two tables, one labelled the left table, and the other the right. This is easy to visualise with just one join in the query, but a little more confusing with two.
Our second INNER JOIN in this query has a right hand side of cd.facilities. That's easy enough to grasp. The left hand side, however, is the table returned by joining cd.members to cd.bookings. It's important to emphasise this: the relational model is all about tables. The output of any join is another table. The output of a query is a table. Single columned lists are tables. Once you grasp that, you've grasped the fundamental beauty of the model.
As a final note, we do introduce one new thing here: the || operator is used to concatenate strings.
Produce a list of costly bookings
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you produce a list of bookings on the day of 2012-09-14 which will cost the member (or guest) more than $30? Remember that guests have different costs to members (the listed costs are per half-hour 'slot'), and the guest user is always ID 0. Include in your output the name of the facility, the name of the member formatted as a single column, and the cost. Order by descending cost, and do not use any subqueries.
┌─────────────────┬────────────────┬──────┐
│ member │ facility │ cost │
├─────────────────┼────────────────┼──────┤
│ GUEST GUEST │ Massage Room 2 │ 320 │
│ GUEST GUEST │ Massage Room 1 │ 160 │
│ GUEST GUEST │ Massage Room 1 │ 160 │
│ GUEST GUEST │ Massage Room 1 │ 160 │
│ GUEST GUEST │ Tennis Court 2 │ 150 │
│ Jemima Farrell │ Massage Room 1 │ 140 │
│ GUEST GUEST │ Tennis Court 1 │ 75 │
│ GUEST GUEST │ Tennis Court 2 │ 75 │
│ GUEST GUEST │ Tennis Court 1 │ 75 │
│ Matthew Genting │ Massage Room 1 │ 70 │
│ Florence Bader │ Massage Room 2 │ 70 │
│ GUEST GUEST │ Squash Court │ 70.0 │
│ Jemima Farrell │ Massage Room 1 │ 70 │
│ Ponder Stibbons │ Massage Room 1 │ 70 │
│ Burton Tracy │ Massage Room 1 │ 70 │
│ Jack Smith │ Massage Room 1 │ 70 │
│ GUEST GUEST │ Squash Court │ 35.0 │
│ GUEST GUEST │ Squash Court │ 35.0 │
└─────────────────┴────────────────┴──────┘
(18 rows)
As before, this answer requires multiple joins. It's more complex WHERE logic than you're used to, and will require a CASE statement in the column selections!
SELECT
M.firstname || ' ' || M.surname AS member,
F.name AS facility,
CASE
WHEN M.memid = 0 THEN B.slots * F.guestcost
ELSE
B.slots * F.membercost
END AS cost
FROM
cd.members M
INNER JOIN cd.bookings B ON M.memid = B.memid
INNER JOIN cd.facilities F ON B.facid = F.facid
WHERE
B.starttime >= '2012-09-14'
AND B.starttime < '2012-09-15'
AND (
(M.memid = 0 AND B.slots * F.guestcost > 30)
OR
(M.memid !=0 AND B.slots * F.membercost > 30)
)
ORDER BY
cost DESC;
SELECT
mems.firstname || ' ' || mems.surname AS member,
facs.name AS facility,
CASE
WHEN mems.memid = 0 THEN bks.slots * facs.guestcost
ELSE bks.slots * facs.membercost
END AS cost
FROM
cd.members mems
INNER JOIN cd.bookings bks ON mems.memid = bks.memid
INNER JOIN cd.facilities facs ON bks.facid = facs.facid
WHERE
bks.starttime >= '2012-09-14'
AND bks.starttime < '2012-09-15'
AND (
(
mems.memid = 0
AND bks.slots * facs.guestcost > 30
)
OR (
mems.memid != 0
AND bks.slots * facs.membercost > 30
)
)
ORDER BY
cost DESC;
This is a bit of a complicated one! While it's more complex logic than we've used previously, there's not an awful lot to remark upon. The WHERE clause restricts our output to sufficiently costly rows on 2012-09-14, remembering to distinguish between guests and members. We then use a CASE statement in the column selections to output the correct cost for the member or guest.
Produce a list of all members, along with their recommender, using no joins
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
How can you output a list of all members, including the individual who recommended them (if any), without using any joins? Ensure that there are no duplicates in the list, and that each firstname + surname pairing is formatted as a column and ordered.
┌─────────────────────────┬───────────────────┐
│ member │ recommender │
├─────────────────────────┼───────────────────┤
│ Anna Mackenzie │ Darren Smith │
│ Anne Baker │ Ponder Stibbons │
│ Burton Tracy │ │
│ Charles Owen │ Darren Smith │
│ Darren Smith │ │
│ David Farrell │ │
│ David Jones │ Janice Joplette │
│ David Pinker │ Jemima Farrell │
│ Douglas Jones │ David Jones │
│ Erica Crumpet │ Tracy Smith │
│ Florence Bader │ Ponder Stibbons │
│ GUEST GUEST │ │
│ Gerald Butters │ Darren Smith │
│ Henrietta Rumney │ Matthew Genting │
│ Henry Worthington-Smyth │ Tracy Smith │
│ Hyacinth Tupperware │ │
│ Jack Smith │ Darren Smith │
│ Janice Joplette │ Darren Smith │
│ Jemima Farrell │ │
│ Joan Coplin │ Timothy Baker │
│ John Hunt │ Millicent Purview │
│ Matthew Genting │ Gerald Butters │
│ Millicent Purview │ Tracy Smith │
│ Nancy Dare │ Janice Joplette │
│ Ponder Stibbons │ Burton Tracy │
│ Ramnaresh Sarwin │ Florence Bader │
│ Tim Boothe │ Tim Rownam │
│ Tim Rownam │ │
│ Timothy Baker │ Jemima Farrell │
│ Tracy Smith │ │
└─────────────────────────┴───────────────────┘
(30 rows)
Answering this question correctly requires the use of a subquery.
SELECT DISTINCT
M.firstname || ' ' || M.surname AS member,
(SELECT firstname || ' ' || surname FROM cd.members WHERE memid = M.recommendedby) AS recommender
FROM
cd.members M
ORDER BY
member ASC;
SELECT
DISTINCT mems.firstname || ' ' || mems.surname AS member,
(
SELECT
recs.firstname || ' ' || recs.surname AS recommender
FROM
cd.members recs
WHERE
recs.memid = mems.recommendedby
)
FROM
cd.members mems
ORDER BY
member;
This exercise marks the introduction of subqueries. Subqueries are, as the name implies, queries within a query. They're commonly used with aggregates, to answer questions like 'get me all the details of the member who has spent the most hours on Tennis Court 1'.
In this case, we're simply using the subquery to emulate an outer join. For every value of member, the subquery is run once to find the name of the individual who recommended them (if any). A subquery that uses information from the outer query in this way (and thus has to be run for each row in the result set) is known as a correlated subquery.
Produce a list of costly bookings, using a subquery
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
The Produce a list of costly bookings exercise contained some messy logic: we had to calculate the booking cost in both the WHERE clause and the CASE statement. Try to simplify this calculation using subqueries. For reference, the question was:
How can you produce a list of bookings on the day of 2012-09-14 which will cost the member (or guest) more than
$30? Remember that guests have different costs to members (the listed costs are per half-hour 'slot'), and the guest user is always ID 0. Include in your output the name of the facility, the name of the member formatted as a single column, and the cost. Order by descending cost.
┌─────────────────┬────────────────┬──────┐
│ member │ facility │ cost │
├─────────────────┼────────────────┼──────┤
│ GUEST GUEST │ Massage Room 2 │ 320 │
│ GUEST GUEST │ Massage Room 1 │ 160 │
│ GUEST GUEST │ Massage Room 1 │ 160 │
│ GUEST GUEST │ Massage Room 1 │ 160 │
│ GUEST GUEST │ Tennis Court 2 │ 150 │
│ Jemima Farrell │ Massage Room 1 │ 140 │
│ GUEST GUEST │ Tennis Court 1 │ 75 │
│ GUEST GUEST │ Tennis Court 2 │ 75 │
│ GUEST GUEST │ Tennis Court 1 │ 75 │
│ Matthew Genting │ Massage Room 1 │ 70 │
│ Florence Bader │ Massage Room 2 │ 70 │
│ GUEST GUEST │ Squash Court │ 70.0 │
│ Jemima Farrell │ Massage Room 1 │ 70 │
│ Ponder Stibbons │ Massage Room 1 │ 70 │
│ Burton Tracy │ Massage Room 1 │ 70 │
│ Jack Smith │ Massage Room 1 │ 70 │
│ GUEST GUEST │ Squash Court │ 35.0 │
│ GUEST GUEST │ Squash Court │ 35.0 │
└─────────────────┴────────────────┴──────┘
(18 rows)
Your answer will be similar to the referenced exercise. Use a subquery in the FROM clause to generate a result set that calculates the total cost of each booking. The outer query can then select the bookings it's interested in.
This can be done without any joins whatsoever:
SELECT
member,
facility,
cost
FROM
(
SELECT
(SELECT M.firstname || ' ' || M.surname FROM cd.members M WHERE M.memid = B.memid) AS member,
(SELECT F.name FROM cd.facilities F WHERE B.facid = F.facid) AS facility,
CASE
WHEN memid = 0 THEN slots * (SELECT guestcost FROM cd.facilities F WHERE F.facid = B.facid)
ELSE
slots * (SELECT membercost FROM cd.facilities F WHERE F.facid = B.facid)
END AS cost
FROM cd.bookings B
WHERE starttime >= '2012-09-14' AND starttime < '2012-09-15'
) AS aggregate_table
WHERE
cost > 30
ORDER BY
cost DESC;
But from the above query we can tell that nearly always the condition of the subquery we are using is something similar to WHERE <table-alias-1>.id = <table-alias-2>.id, the exact kind of condition we would want to specify in what to join ON. It's silly not to take advantage of joins in this case; however, a subquery can still be very useful in terms of selecting cost without involving too much funky business in the last WHERE clause. Hence, our solution to this problem can be transformed from the rather unwieldy query
SELECT
M.firstname || ' ' || M.surname AS member,
F.name AS facility,
CASE
WHEN M.memid = 0 THEN B.slots * F.guestcost
ELSE
B.slots * F.membercost
END AS cost
FROM
cd.members M
INNER JOIN cd.bookings B ON M.memid = B.memid
INNER JOIN cd.facilities F ON B.facid = F.facid
WHERE
B.starttime >= '2012-09-14'
AND B.starttime < '2012-09-15'
AND (
(M.memid = 0 AND B.slots * F.guestcost > 30)
OR
(M.memid !=0 AND B.slots * F.membercost > 30)
)
ORDER BY
cost DESC;
where the SELECT clause is polluted with a CASE statement and the overly complicated WHERE clause contains semi-duplicated logic from the CASE statement, to the more easily understood query
SELECT
member,
facility,
cost
FROM
(
SELECT
M.firstname || ' ' || M.surname AS member,
F.name AS facility,
CASE
WHEN M.memid = 0 THEN B.slots * F.guestcost
ELSE
B.slots * F.membercost
END AS cost
FROM
cd.members M
INNER JOIN cd.bookings B ON M.memid = B.memid
INNER JOIN cd.facilities F ON B.facid = F.facid
WHERE
B.starttime >= '2012-09-14' AND B.starttime < '2012-09-15'
) AS desired_info
WHERE
cost > 30
ORDER BY
cost DESC;
One of the nice things about this cleaned up query is that the initial SELECT statement is cleaner as well as the WHERE clause. There's no issue with accessing the cost column to ORDER BY since we are essentially selecting from a temporary table created by a SELECT subquery in the FROM clause. Such a temporary table (i.e., a temporary table used as in SELECT ... FROM ( <temp-table-created-by-subquery> )) is often referred to as an inline view.
SELECT
member,
facility,
cost
FROM
(
SELECT
mems.firstname || ' ' || mems.surname AS member,
facs.name AS facility,
CASE
WHEN mems.memid = 0 THEN bks.slots * facs.guestcost
ELSE bks.slots * facs.membercost
END AS cost
FROM
cd.members mems
INNER JOIN cd.bookings bks ON mems.memid = bks.memid
INNER JOIN cd.facilities facs ON bks.facid = facs.facid
WHERE
bks.starttime >= '2012-09-14'
AND bks.starttime < '2012-09-15'
) AS bookings
WHERE
cost > 30
ORDER BY
cost DESC;
This answer provides a mild simplification to the previous iteration: in the no-subquery version, we had to calculate the member or guest's cost in both the WHERE clause and the CASE statement. In our new version, we produce an inline query that calculates the total booking cost for us, allowing the outer query to simply select the bookings it's looking for. For reference, you may also see subqueries in the FROM clause referred to as inline views.
Modifying Data
Intro
Querying data is all well and good, but at some point you're probably going to want to put data into your database! This section deals with inserting, updating, and deleting information. Operations that alter your data like this are collectively known as Data Manipulation Language, or DML.
In previous sections, we returned to you the results of the query you've performed. Since modifications like the ones we're making in this section don't return any query results, we instead show you the updated content of the table you're supposed to be working on. You can compare this with the table shown in 'Expected Results' to see how you've done.
If you struggle with these questions, I strongly recommend Learning SQL, by Alan Beaulieu.
Insert some data into a table
- Question
- Hint
- My Answer
- Discussion
- Schema Reminder
The club is adding a new facility - a spa. We need to add it into the facilities table. Use the following values:
facid: 9, Name: 'Spa', membercost: 20, guestcost: 30, initialoutlay: 100000, monthlymaintenance: 800.
INSERT can be used to insert data into a table.
INSERT INTO
cd.facilities (facid, name, membercost, guestcost, initialoutlay, monthlymaintenance)
VALUES
(9, 'Spa', 20, 30, 100000, 800);
INSERT INTO
cd.facilities (
facid,
name,
membercost,
guestcost,
initialoutlay,
monthlymaintenance
)
VALUES
(9, 'Spa', 20, 30, 100000, 800);
INSERT INTO ... VALUES is the simplest way to insert data into a table. There's not a whole lot to discuss here: VALUES is used to construct a row of data, which the INSERT statement inserts into the table. It's a simple as that.
You can see that there's two sections in parentheses. The first is part of the INSERT statement, and specifies the columns that we're providing data for. The second is part of VALUES, and specifies the actual data we want to insert into each column.
If we're inserting data into every column of the table, as in this example, explicitly specifying the column names is optional. As long as you fill in data for all columns of the table, in the order they were defined when you created the table, you can do something like the following:
INSERT INTO
cd.facilities
VALUES
(9, 'Spa', 20, 30, 100000, 800);
Generally speaking, for SQL that's going to be reused I tend to prefer being explicit and specifying the column names.
Insert multiple rows of data into a table
- Question
- Hint
- My Answer
- Discussion
- Schema Reminder
In the previous exercise, you learned how to add a facility. Now you're going to add multiple facilities in one command. Use the following values:
facid: 9, Name: 'Spa', membercost: 20, guestcost: 30, initialoutlay: 100000, monthlymaintenance: 800.facid: 10, Name: 'Squash Court 2', membercost: 3.5, guestcost: 17.5, initialoutlay: 5000, monthlymaintenance: 80.
VALUES can be used to generate more than one row.
INSERT INTO
cd.facilities (facid, name, membercost, guestcost, initialoutlay, monthlymaintenance)
VALUES
(9, 'Spa', 20, 30, 100000, 800),
(10, 'Squash Court 2', 3.5, 17.5, 5000, 80);
INSERT INTO
cd.facilities (
facid,
name,
membercost,
guestcost,
initialoutlay,
monthlymaintenance
)
VALUES
(9, 'Spa', 20, 30, 100000, 800),
(10, 'Squash Court 2', 3.5, 17.5, 5000, 80);
VALUES can be used to generate more than one row to insert into a table, as seen in this example. Hopefully it's clear what's going on here: the output of VALUES is a table, and that table is copied into cd.facilities, the table specified in the INSERT command.
While you'll most commonly see VALUES when inserting data, Postgres allows you to use VALUES wherever you might use a SELECT. This makes sense: the output of both commands is a table, it's just that VALUES is a bit more ergonomic when working with constant data.
Similarly, it's possible to use SELECT wherever you see a VALUES. This means that you can INSERT the results of a SELECT. For example:
INSERT INTO cd.facilities
(facid, name, membercost, guestcost, initialoutlay, monthlymaintenance)
SELECT 9, 'Spa', 20, 30, 100000, 800
UNION ALL
SELECT 10, 'Squash Court 2', 3.5, 17.5, 5000, 80;
In later exercises you'll see us using INSERT ... SELECT to generate data to insert based on the information already in the database.
Insert calculated data into a table
- Question
- Hint
- My Answer
- Discussion
- Schema Reminder
Let's try adding the spa to the facilities table again. This time, though, we want to automatically generate the value for the next facid, rather than specifying it as a constant. Use the following values for everything else:
Name: 'Spa', membercost: 20, guestcost: 30, initialoutlay: 100000, monthlymaintenance: 800.
You can calculate data to insert using subqueries.
INSERT INTO
cd.facilities (facid, name, membercost, guestcost, initialoutlay, monthlymaintenance)
VALUES
((SELECT MAX(facid) + 1 FROM cd.facilities), 'Spa', 20, 30, 100000, 800);
INSERT INTO cd.facilities
(facid, name, membercost, guestcost, initialoutlay, monthlymaintenance)
SELECT (SELECT MAX(facid) FROM cd.facilities)+1, 'Spa', 20, 30, 100000, 800;
In the previous exercises we used VALUES to insert constant data into the facilities table. Here, though, we have a new requirement: a dynamically generated ID. This gives us a real quality of life improvement, as we don't have to manually work out what the current largest ID is: the SQL command does it for us.
Since the VALUES clause is only used to supply constant data, we need to replace it with a query instead. The SELECT statement is fairly simple: there's an inner subquery that works out the next facid based on the largest current id, and the rest is just constant data. The output of the statement is a row that we insert into the facilities table.
While this works fine in our simple example, it's not how you would generally implement an incrementing ID in the real world. Postgres provides SERIAL types that are auto-filled with the next ID when you insert a row. As well as saving us effort, these types are also safer: unlike the answer given in this exercise, there's no need to worry about concurrent operations generating the same ID.
Update some existing data
- Question
- Hint
- My Answer
- Discussion
- Schema Reminder
We made a mistake when entering the data for the second tennis court. The initial outlay was 10000 rather than 8000: you need to alter the data to fix the error.
You can alter existing data using the UPDATE statement.
UPDATE
cd.facilities
SET
initialoutlay = 10000
WHERE
name = 'Tennis Court 2';
UPDATE cd.facilities
SET initialoutlay = 10000
WHERE facid = 1;
The UPDATE statement is used to alter existing data. If you're familiar with SELECT queries, it's pretty easy to read: the WHERE clause works in exactly the same fashion, allowing us to filter the set of rows we want to work with. These rows are then modified according to the specifications of the SET clause: in this case, setting the initial outlay.
The WHERE clause is extremely important. It's easy to get it wrong or even omit it, with disastrous results. Consider the following command:
UPDATE cd.facilities
SET initialoutlay = 10000;
There's no WHERE clause to filter for the rows we're interested in. The result of this is that the update runs on every row in the table! This is rarely what we want to happen.
Update multiple rows and columns at the same time
- Question
- Hint
- My Answer
- Discussion
- Schema Reminder
We want to increase the price of the tennis courts for both members and guests. Update the costs to be 6 for members, and 30 for guests.
The SET clause can update multiple columns.
UPDATE
cd.facilities
SET
membercost = 6,
guestcost = 30
WHERE
name ILIKE '%tennis court%';
UPDATE cd.facilities
SET
membercost = 6,
guestcost = 30
WHERE facid IN (0,1);
The SET clause accepts a comma separated list of values that you want to update.
Update a row based on the contents of another row
- Question
- Hint
- My Answer
- Discussion
- Schema Reminder
We want to alter the price of the second tennis court so that it costs 10% more than the first one. Try to do this without using constant values for the prices, so that we can reuse the statement if we want to.
Take a look at UPDATE FROM in the PostgreSQL documentation.
Here is the largely straightforward way:
UPDATE
cd.facilities
SET
membercost = (SELECT membercost * 1.1 FROM cd.facilities WHERE name = 'Tennis Court 1'),
guestcost = (SELECT guestcost * 1.1 FROM cd.facilities WHERE name = 'Tennis Court 1')
WHERE
name = 'Tennis Court 2';
But this is a clearly cumbersome approach, especially if, say, we wanted to update much more than just membercost and guestcost for Tennis Court 2 where the things being updated depend on Tennis Court 1 as they do above. Postgres provides a nonstandard extension to SQL called UPDATE...FROM that addresses this issue and can be used like so:
UPDATE cd.facilities F
SET
membercost = facCosts.membercost * 1.1,
guestcost = facCosts.guestcost * 1.1
FROM
(SELECT membercost, guestcost FROM cd.facilities WHERE name = 'Tennis Court 1') facCosts
WHERE
F.name = 'Tennis Court 2';
UPDATE cd.facilities facs
SET
membercost = (SELECT membercost * 1.1 FROM cd.facilities WHERE facid = 0),
guestcost = (SELECT guestcost * 1.1 FROM cd.facilities WHERE facid = 0)
WHERE facs.facid = 1;
Updating columns based on calculated data is not too intrinsically difficult: we can do so pretty easily using subqueries. You can see this approach in our selected answer.
As the number of columns we want to update increases, standard SQL can start to get pretty awkward: you don't want to be specifying a separate subquery for each of 15 different column updates. Postgres provides a nonstandard extension to SQL called UPDATE...FROM that addresses this: it allows you to supply a FROM clause to generate values for use in the SET clause. Example below:
UPDATE cd.facilities facs
SET
membercost = facs2.membercost * 1.1,
guestcost = facs2.guestcost * 1.1
FROM (SELECT * FROM cd.facilities WHERE facid = 0) facs2
WHERE facs.facid = 1;
Delete all bookings
- Question
- Hint
- My Answer
- Discussion
- Schema Reminder
As part of a clearout of our database, we want to delete all bookings from the cd.bookings table. How can we accomplish this?
TRUNCATE TABLE cd.bookings;
DELETE FROM cd.bookings;
The DELETE statement does what it says on the tin: deletes rows from the table. Here, we show the command in its simplest form, with no qualifiers. In this case, it deletes everything from the table. Obviously, you should be careful with your deletes and make sure they're always limited - we'll see how to do that in the next exercise.
An alternative to unqualified DELETEs is the following:
TRUNCATE cd.bookings;
TRUNCATE also deletes everything in the table, but does so using a quicker underlying mechanism. It's not perfectly safe in all circumstances, though, so use judiciously. When in doubt, use DELETE.
Delete a member from the cd.members table
- Question
- Hint
- My Answer
- Discussion
- Schema Reminder
We want to remove member 37, who has never made a booking, from our database. How can we achieve that?
Take a look at the DELETE statement in the PostgreSQL docs.
DELETE FROM
cd.members
WHERE
memid = 37;
DELETE FROM
cd.members
WHERE
memid = 37;
This exercise is a small increment on our previous one. Instead of deleting all bookings, this time we want to be a bit more targeted, and delete a single member that has never made a booking. To do this, we simply have to add a WHERE clause to our command, specifying the member we want to delete. You can see the parallels with SELECT and UPDATE statements here.
There's one interesting wrinkle here. Try this command out, but substituting in member id 0 instead. This member has made many bookings, and you'll find that the delete fails with an error about a foreign key constraint violation. This is an important concept in relational databases, so let's explore a little further.
Foreign keys are a mechanism for defining relationships between columns of different tables. In our case we use them to specify that the memid column of the bookings table is related to the memid column of the members table. The relationship (or 'constraint') specifies that for a given booking, the member specified in the booking must exist in the members table. It's useful to have this guarantee enforced by the database: it means that code using the database can rely on the presence of the member. It's hard (even impossible) to enforce this at higher levels: concurrent operations can interfere and leave your database in a broken state.
PostgreSQL supports various different kinds of constraints that allow you to enforce structure upon your data. For more information on constraints, check out the PostgreSQL documentation on foreign keys.
Delete based on a subquery
- Question
- Hint
- My Answer
- Discussion
- Schema Reminder
In our previous exercises, we deleted a specific member who had never made a booking. How can we make that more general, to delete all members who have never made a booking?
You can delete based on the output of a subquery.
DELETE FROM
cd.members
WHERE
memid NOT IN (SELECT DISTINCT memid FROM cd.bookings);
DELETE FROM
cd.members
WHERE
memid NOT IN (
SELECT
memid
FROM
cd.bookings
);
We can use subqueries to determine whether a row should be deleted or not. There's a couple of standard ways to do this. In our featured answer, the subquery produces a list of all the different member ids in the cd.bookings table. If a row in the table isn't in the list generated by the subquery, it gets deleted.
An alternative is to use a correlated subquery. Where our previous example runs a large subquery once, the correlated approach instead specifies a smaller subquery to run against every row.
DELETE FROM
cd.members mems
WHERE
NOT EXISTS (
SELECT
1
FROM
cd.bookings
WHERE
memid = mems.memid
);
The two different forms can have different performance characteristics. Under the hood, your database engine is free to transform your query to execute it in a correlated or uncorrelated fashion, though, so things can be a little hard to predict.
Aggregates
Intro
Aggregation is one of those capabilities that really makes you appreciate the power of relational database systems. It allows you to move beyond merely persisting your data, into the realm of asking truly interesting questions that can be used to inform decision making. This category covers aggregation at length, making use of standard grouping as well as more recent window functions.
If you struggle with these questions, I strongly recommend Learning SQL, by Alan Beaulieu and SQL Cookbook by Anthony Molinaro. In fact, get the latter anyway - it'll take you beyond anything you find on this site, and on multiple different database systems to boot.
Count the number of facilities
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
For our first foray into aggregates, we're going to stick to something simple. We want to know how many facilities exist - simply produce a total count.
┌───────┐
│ count │
├───────┤
│ 9 │
└───────┘
(1 row)
Try investigating the SQL COUNT function.
SELECT
COUNT(*) AS count
FROM
cd.facilities;
SELECT
COUNT(*)
FROM
cd.facilities;
Aggregation starts out pretty simply! The SQL above selects everything from our cd.facilities table, and then counts the number of rows in the result set. The COUNT function has a variety of uses:
COUNT(*)simply returns the number of rowsCOUNT(address)counts the number of non-null addresses in the result set.- Finally,
COUNT(DISTINCT address)counts the number of different addresses in the result set.
The basic idea of an aggregate function is that it takes in a column of data, performs some function upon it, and outputs a scalar (single) value. There are a bunch more aggregation functions, including MAX, MIN, SUM, and AVG. These all do pretty much what you'd expect from their names.
One aspect of aggregate functions that people often find confusing is in queries like the below:
SELECT
facid,
count(*)
FROM
cd.facilities;
Try it out, and you'll find that it doesn't work. This is because COUNT(*) wants to collapse the cd.facilities table into a single value - unfortunately, it can't do that, because there's a lot of different facid's in cd.facilities - Postgres doesn't know which facid to pair the count with.
Instead, if you wanted a query that returns all the facid's along with a count on each row, you can break the aggregation out into a subquery as below:
SELECT
facid,
(
SELECT
COUNT(*)
FROM
cd.facilities
)
FROM
cd.facilities;
When we have a subquery that returns a scalar value like this, Postgres knows to simply repeat the value for every row in cd.facilities.
Count the number of expensive facilities
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a count of the number of facilities that have a cost to guests of 10 or more.
┌───────┐
│ count │
├───────┤
│ 6 │
└───────┘
(1 row)
You'll need to add a WHERE clause to the answer of the previous question.
SELECT
COUNT(*)
FROM
cd.facilities
WHERE
guestcost >= 10;
SELECT
COUNT(*)
FROM
cd.facilities
WHERE
guestcost >= 10;
This one is only a simple modification to the previous question: we need to weed out the inexpensive facilities. This is easy to do using a WHERE clause. Our aggregation can now only see the expensive facilities.
Count the number of recommendations each member makes
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a count of the number of recommendations each member has made. Order by member ID.
┌───────────────┬───────┐
│ recommendedby │ count │
├───────────────┼───────┤
│ 1 │ 5 │
│ 2 │ 3 │
│ 3 │ 1 │
│ 4 │ 2 │
│ 5 │ 1 │
│ 6 │ 1 │
│ 9 │ 2 │
│ 11 │ 1 │
│ 13 │ 2 │
│ 15 │ 1 │
│ 16 │ 1 │
│ 20 │ 1 │
│ 30 │ 1 │
└───────────────┴───────┘
(13 rows)
Try investigating GROUP BY with your count this time. Don't forget to filter out null recommenders! See IS NOT NULL documentation as well.
You could do this the hard way with an unnecessary INNER JOIN:
SELECT
recommendees.recommendedby AS recommendedby,
COUNT(recommendees.recommendedby) AS count
FROM
cd.members recommenders
INNER JOIN cd.members recommendees ON recommenders.memid = recommendees.recommendedby
GROUP BY
recommendees.recommendedby
ORDER BY
recommendedby;
Or you could do it in a much simpler way:
SELECT
recommendedby,
COUNT(*)
FROM
cd.members
WHERE
recommendedby IS NOT NULL
GROUP BY
recommendedby
ORDER BY
recommendedby;
Notice that the inner join is what makes the first solution work (since joining on recommenders.memid = recommendees.recommendedby effectively filters out all the rows where recommendedby is NULL).
SELECT
recommendedby,
COUNT(*)
FROM
cd.members
WHERE
recommendedby IS NOT NULL
GROUP BY
recommendedby
ORDER BY
recommendedby;
Previously, we've seen that aggregation functions are applied to a column of values, and convert them into an aggregated scalar value. This is useful, but we often find that we don't want just a single aggregated result: for example, instead of knowing the total amount of money the club has made this month, I might want to know how much money each different facility has made, or which times of day were most lucrative.
In order to support this kind of behaviour, SQL has the GROUP BY construct. What this does is batch the data together into groups, and run the aggregation function separately for each group. When you specify a GROUP BY, the database produces an aggregated value for each distinct value in the supplied columns. In this case, we're saying 'for each distinct value of recommendedby, get me the number of times that value appears'.
List the total slots booked per facility
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a list of the total number of slots booked per facility. For now, just produce an output table consisting of facility id and slots, sorted by facility id.
┌───────┬──────┐
│ facid │ sum │
├───────┼──────┤
│ 0 │ 1320 │
│ 1 │ 1278 │
│ 2 │ 1209 │
│ 3 │ 830 │
│ 4 │ 1404 │
│ 5 │ 228 │
│ 6 │ 1104 │
│ 7 │ 908 │
│ 8 │ 911 │
└───────┴──────┘
(9 rows)
For this one you'll need to check out the SUM aggregate function.
SELECT
facid,
SUM(slots)
FROM
cd.bookings
GROUP BY
facid
ORDER BY
facid;
SELECT
facid,
SUM(slots) AS "Total Slots"
FROM
cd.bookings
GROUP BY
facid
ORDER BY
facid;
Other than the fact that we've introduced the SUM aggregate function, there's not a great deal to say about this exercise. For each distinct facility id, the SUM function adds together everything in the slots column.
List the total slots booked per facility in a given month
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a list of the total number of slots booked per facility in the month of September 2012. Produce an output table consisting of facility id and slots, sorted by the number of slots.
┌───────┬─────────────┐
│ facid │ Total Slots │
├───────┼─────────────┤
│ 5 │ 122 │
│ 3 │ 422 │
│ 7 │ 426 │
│ 8 │ 471 │
│ 6 │ 540 │
│ 2 │ 570 │
│ 1 │ 588 │
│ 0 │ 591 │
│ 4 │ 648 │
└───────┴─────────────┘
(9 rows)
You can restrict the data that goes into your aggregate functions using the WHERE clause. Remember that the WHERE clause applies to individual rows directly before GROUP BY in the order of execution for a query. As stated below in the answers and discussion, a good way of thinking about WHERE in the context of aggregates is that the WHERE clause is used to restrict the data we aggregate over.
SELECT
facid,
SUM(slots) AS "Total Slots"
FROM
cd.bookings
WHERE
starttime >= '2012-09-01' AND starttime < '2012-10-01'
GROUP BY
facid
ORDER BY
"Total Slots" ASC;
SELECT
facid,
SUM(slots) AS "Total Slots"
FROM
cd.bookings
WHERE
starttime >= '2012-09-01'
AND starttime < '2012-10-01'
GROUP BY
facid
ORDER BY
SUM(slots);
This is only a minor alteration of our previous example. Remember that aggregation happens after the WHERE clause is evaluated: we thus use the WHERE to restrict the data we aggregate over, and our aggregation only sees data from a single month.
List the total slots booked per facility per month
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a list of the total number of slots booked per facility per month in the year of 2012. Produce an output table consisting of facility id and slots, sorted by the id and month.
┌───────┬───────┬─────────────┐
│ facid │ month │ Total Slots │
├───────┼───────┼─────────────┤
│ 0 │ 7 │ 270 │
│ 0 │ 8 │ 459 │
│ 0 │ 9 │ 591 │
│ 1 │ 7 │ 207 │
│ 1 │ 8 │ 483 │
│ 1 │ 9 │ 588 │
│ 2 │ 7 │ 180 │
│ 2 │ 8 │ 459 │
│ 2 │ 9 │ 570 │
│ 3 │ 7 │ 104 │
│ 3 │ 8 │ 304 │
│ 3 │ 9 │ 422 │
│ 4 │ 7 │ 264 │
│ 4 │ 8 │ 492 │
│ 4 │ 9 │ 648 │
│ 5 │ 7 │ 24 │
│ 5 │ 8 │ 82 │
│ 5 │ 9 │ 122 │
│ 6 │ 7 │ 164 │
│ 6 │ 8 │ 400 │
│ 6 │ 9 │ 540 │
│ 7 │ 7 │ 156 │
│ 7 │ 8 │ 326 │
│ 7 │ 9 │ 426 │
│ 8 │ 7 │ 117 │
│ 8 │ 8 │ 322 │
│ 8 │ 9 │ 471 │
└───────┴───────┴─────────────┘
(27 rows)
Take a look at the EXTRACT function.
SELECT
facid,
EXTRACT(MONTH FROM starttime) AS month,
SUM(slots) AS "Total Slots"
FROM
cd.bookings
WHERE
EXTRACT(YEAR FROM starttime) = 2012
GROUP BY
EXTRACT(MONTH FROM starttime), facid
ORDER BY
facid, month;
SELECT facid, EXTRACT(MONTH FROM starttime) AS month, SUM(slots) AS "Total Slots"
FROM cd.bookings
WHERE EXTRACT(YEAR FROM starttime) = 2012
GROUP BY facid, month
ORDER BY facid, month;
The main piece of new functionality in this question is the EXTRACT function. EXTRACT allows you to get individual components of a timestamp, like day, month, year, etc. We group by the output of this function to provide per-month values. An alternative, if we needed to distinguish between the same month in different years, is to make use of the DATE_TRUNC function, which truncates a date to a given granularity. It's also worth noting that this is the first time we've truly made use of the ability to group by more than one column.
One thing worth considering with this answer: the use of the EXTRACT function in the WHERE clause has the potential to cause severe issues with performance on larger tables. If the timestamp column has a regular index on it, Postgres will not understand that it can use the index to speed up the query and will instead have to scan through the whole table. You've got a couple of options here:
- Consider creating an expression-based index on the timestamp column. With appropriately specified indexes Postgres can use indexes to speed up
WHEREclauses containing function calls. - Alter the query to be a little more verbose, but use more standard comparisons, for example:
SELECT facid, extract(MONTH FROM starttime) AS month, SUM(slots) AS "Total Slots"
FROM cd.bookings
WHERE
starttime >= '2012-01-01'
AND starttime < '2013-01-01'
GROUP BY facid, month
ORDER BY facid, month;
Postgres is able to use an index using these standard comparisons without any additional assistance.
Find the count of members who have made at least one booking
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Find the total number of members (including guests) who have made at least one booking.
┌───────┐
│ count │
├───────┤
│ 30 │
└───────┘
(1 row)
Take a look at COUNT DISTINCT.
SELECT
COUNT(DISTINCT memid) AS count
FROM
cd.bookings;
SELECT
COUNT(DISTINCT memid)
FROM
cd.bookings;
Your first instinct may be to go for a subquery here. Something like the below:
SELECT COUNT(*) FROM
(SELECT DISTINCT memid FROM cd.bookings) AS mems;
This does work perfectly well, but we can simplify a touch with the help of a little extra knowledge in the form of COUNT DISTINCT. This does what you might expect, counting the distinct values in the passed column.
List facilities with more than 1000 slots booked
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a list of facilities with more than 1000 slots booked. Produce an output table consisting of facility id and slots, sorted by facility id.
┌───────┬─────────────┐
│ facid │ Total Slots │
├───────┼─────────────┤
│ 0 │ 1320 │
│ 1 │ 1278 │
│ 2 │ 1209 │
│ 4 │ 1404 │
│ 6 │ 1104 │
└───────┴─────────────┘
(5 rows)
Try investigating the HAVING clause.
SELECT
facid,
SUM(slots) AS "Total Slots"
FROM
cd.bookings
GROUP BY
facid
HAVING
SUM(slots) > 1000
ORDER BY
facid;
SELECT
facid,
SUM(slots) AS "Total Slots"
FROM
cd.bookings
GROUP BY
facid
HAVING
SUM(slots) > 1000
ORDER BY
facid;
It turns out that there's actually an SQL keyword designed to help with the filtering of output from aggregate functions. This keyword is HAVING.
The behaviour of HAVING is easily confused with that of WHERE. The best way to think about it is that in the context of a query with an aggregate function, WHERE is used to filter what data gets input into the aggregate function, while HAVING is used to filter the data once it is output from the function. Try experimenting to explore this difference!
Find the total revenue of each facility
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a list of facilities along with their total revenue. The output table should consist of facility name and revenue, sorted by revenue. Remember that there's a different cost for guests and members!
┌─────────────────┬─────────┐
│ name │ revenue │
├─────────────────┼─────────┤
│ Table Tennis │ 180 │
│ Snooker Table │ 240 │
│ Pool Table │ 270 │
│ Badminton Court │ 1906.5 │
│ Squash Court │ 13468.0 │
│ Tennis Court 1 │ 13860 │
│ Tennis Court 2 │ 14310 │
│ Massage Room 2 │ 15810 │
│ Massage Room 1 │ 72540 │
└─────────────────┴─────────┘
(9 rows)
Remember the CASE statement!
This seems like a somewhat difficult problem on the surface, but starting with a small, simple query should clarify things:
SELECT
F.name,
SUM(slots)
FROM
cd.bookings B
INNER JOIN cd.facilities F ON B.facid = F.facid
GROUP BY
F.name;
This query gives us the following result set:
We are very close to getting exactly what we need--we have everything grouped by facility name and we have the total number of slots for each facility. The obvious critical piece of information that we are missing is what we are being asked to report, namely the total revenue of each facility.
How do we find this? It seems like we should be able to just multiply slots by some number to give us the revenue and that's basically what the correct approach is--the only problem is that not every slot costs the same amount. If the person who booked the slot is a guest (indicated internally by the guest having memid = 0), then each slot will cost guestcost amount; otherwise, when memid != 0, each slot will cost membercost amount.
Hence, an appropriate solution is to multiply the slots number by guestcost or membercost depending on whether or not memid = 0 or memid != 0, respectively, and then sum up all those values where the values are grouped by facility name:
SELECT
F.name,
SUM(B.slots *
CASE
WHEN B.memid = 0 THEN F.guestcost
ELSE
F.membercost
END) AS revenue
FROM
cd.bookings B
INNER JOIN cd.facilities F ON B.facid = F.facid
GROUP BY
F.name
ORDER BY
revenue ASC;
This gives us the desired result set:
This result set may make even more sense when we look at a breakdown of everything by whether or not the person making the booking for a facility was a guest or a member:
SELECT
F.name, SUM(B.slots) AS slots_booked, 'Member' AS role, F.membercost AS cost_per_slot
FROM
cd.bookings B INNER JOIN cd.facilities F ON B.facid = F.facid
WHERE
B.memid != 0
GROUP BY
F.name, F.membercost
UNION ALL
SELECT
F.name, SUM(B.slots) AS slots_booked, 'GUEST' AS role, F.guestcost AS cost_per_slot
FROM
cd.bookings B INNER JOIN cd.facilities F ON B.facid = F.facid
WHERE
B.memid = 0
GROUP BY
F.name, F.guestcost
ORDER BY
role, name;
This query gives us the following result set:
Finally, as usual, there's more than one way to do something in SQL--we could use an inline view to give us what we want (this general approach may be more favorable, albeit less aparent, than the prior approach given the ease with which you can then use WHERE among other things since what you are selecting is not a column alias):
SELECT
name,
revenue
FROM
(
SELECT
F.name,
SUM(B.slots *
CASE
WHEN B.memid = 0 THEN F.guestcost
ELSE
F.membercost
END) AS revenue
FROM
cd.bookings B
INNER JOIN cd.facilities F ON B.facid= F.facid
GROUP BY
F.name
) AS agg
ORDER BY
revenue ASC;
SELECT
facs.name,
SUM(
slots * CASE
WHEN memid = 0 THEN facs.guestcost
ELSE facs.membercost
END
) AS revenue
FROM
cd.bookings bks
INNER JOIN cd.facilities facs ON bks.facid = facs.facid
GROUP BY
facs.name
ORDER BY
revenue;
The only real complexity in this query is that guests (member ID 0) have a different cost to everyone else. We use a case statement to produce the cost for each session, and then sum each of those sessions, grouped by facility.
Find facilities with a total revenue less than 1000
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a list of facilities with a total revenue less than 1000. Produce an output table consisting of facility name and revenue, sorted by revenue. Remember that there's a different cost for guests and members!
┌───────────────┬─────────┐
│ name │ revenue │
├───────────────┼─────────┤
│ Table Tennis │ 180 │
│ Snooker Table │ 240 │
│ Pool Table │ 270 │
└───────────────┴─────────┘
(3 rows)
You may find HAVING difficult to use here. Try a subquery instead. You'll probably also need a CASE statement.
The work we did in the previous exercise where we used an inline view will help a great deal here (not using an inline view makes things much more difficult):
SELECT
name,
revenue
FROM
(
SELECT
F.name,
SUM(B.slots *
CASE
WHEN B.memid = 0 THEN F.guestcost
ELSE
F.membercost
END) AS revenue
FROM
cd.bookings B
INNER JOIN cd.facilities F ON B.facid= F.facid
GROUP BY
F.name
) AS agg
WHERE
revenue < 1000
ORDER BY
revenue ASC;
SELECT
name,
revenue
FROM
(
SELECT
facs.name,
SUM(
CASE
WHEN memid = 0 THEN slots * facs.guestcost
ELSE slots * membercost
END
) AS revenue
FROM
cd.bookings bks
INNER JOIN cd.facilities facs ON bks.facid = facs.facid
GROUP BY
facs.name
) AS agg
WHERE
revenue < 1000
ORDER BY
revenue;
You may well have tried to use the HAVING keyword we introduced in an earlier exercise, producing something like below:
SELECT
facs.name,
SUM(
CASE
WHEN memid = 0 THEN slots * facs.guestcost
ELSE slots * membercost
END
) AS revenue
FROM
cd.bookings bks
INNER JOIN cd.facilities facs ON bks.facid = facs.facid
GROUP BY
facs.name
HAVING
revenue < 1000
ORDER BY
revenue;
Unfortunately, this doesn't work! You'll get an error along the lines of ERROR: column "revenue" does not exist. Postgres, unlike some other RDBMSs like SQL Server and MySQL, doesn't support putting column names in the HAVING clause. This means that for this query to work, you'd have to produce something like below:
SELECT
facs.name,
SUM(
CASE
WHEN memid = 0 THEN slots * facs.guestcost
ELSE slots * membercost
END
) AS revenue
FROM
cd.bookings bks
INNER JOIN cd.facilities facs ON bks.facid = facs.facid
GROUP BY
facs.name
HAVING
SUM(
CASE
WHEN memid = 0 THEN slots * facs.guestcost
ELSE slots * membercost
END
) < 1000
ORDER BY
revenue;
Having to repeat significant calculation code like this is messy, so our anointed solution instead just wraps the main query body as a subquery, and selects from it using a WHERE clause. In general, I recommend using HAVING for simple queries, as it increases clarity. Otherwise, this subquery approach is often easier to use.
Output the facility id that has the highest number of slots booked
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Output the facility id that has the highest number of slots booked. For bonus points, try a version without a LIMIT clause. This version will probably look messy!
┌───────┬─────────────┐
│ facid │ Total Slots │
├───────┼─────────────┤
│ 4 │ 1404 │
└───────┴─────────────┘
(1 row)
Consider the use of the LIMIT keyword combined with ORDER BY. For the LIMIT-less version, you'll probably want to investigate the HAVING keyword. Be aware that the latter version is difficult!
There are many ways to approach this problem. Let's take a look at a few of them.
Simple INNER JOIN:
Arguably the simplest solution is as follows:
SELECT
F.facid,
SUM(B.slots) AS "Total Slots"
FROM
cd.bookings B
INNER JOIN cd.facilities F ON B.facid = F.facid
GROUP BY
F.facid
ORDER BY
SUM(B.slots) DESC
LIMIT 1;
Simple INNER JOIN with an inline view:
We could also use an inline view to clean up the SELECT clause, but this seems like more trouble than it's worth:
SELECT
facid,
"Total Slots"
FROM
(
SELECT
F.facid,
SUM(B.slots) AS "Total Slots"
FROM
cd.bookings B
INNER JOIN cd.facilities F ON B.facid = F.facid
GROUP BY
F.facid
ORDER BY
SUM(B.slots) DESC
LIMIT 1
) X;
The biggest problem with both solutions above can be seen by asking a simple question: What happens in the case of a tie? We just lose the data which is never ideal and sometimes unacceptable. We can write up another solution using HAVING that results in a query that is rather unsightly:
No INNER JOIN but messy use of HAVING:
SELECT
facid,
SUM(slots) AS "Total Slots"
FROM
cd.bookings
GROUP BY
facid
HAVING
SUM(slots) = (
SELECT
MAX("Total Slots")
FROM
(
SELECT
SUM(slots) AS "Total Slots"
FROM
cd.bookings
GROUP BY
facid
) AS agg
);
A non-recursive Common Table Expression (CTE):
We can also approach this problem using a PostgreSQL Common Table Expression (CTE) (see the official docs as well) which is meant to simplify complex queries (it is essentially an inline view).
A CTE is a temporary result set (i.e., temporary in the sense that a CTE only exists during the execution of a query) which you can reference within another SQL statement including SELECT, INSERT, UPDATE, or DELETE. You can create a CTE by using the following syntax:
WITH cte_name [(column_list)] AS (
CTE_query_definition
)
statement;
Some points worth noting about this syntax:
- First, specify the name of the CTE,
cte_name, followed by an optionalcolumn_list. - Second, inside the body of the
WITHclause, specify a query that returns a result set. If you do not explicitly specify thecolumn_listafter the CTE name, the select list of theCTE_query_definitionwill become the column list of the CTE. - Third, use the CTE like a table or view in the
statementwhich can be aSELECT,INSERT,UPDATE, orDELETE.
CTEs are typically used to simplify complex joins and subqueries in PostgreSQL. There are also recursive CTEs which can be even more powerful and have the following syntax:
WITH RECURSIVE cte_name AS (
CTE_query_definition -- non-recursive term
UNION [ALL]
CTE_query definion -- recursive term
) SELECT * FROM cte_name;
Returning to the problem at hand, we see that using a CTE where the statement is a SELECT might be helpful here (a recursive CTE is not needed here; recursive CTEs will be looked at later):
WITH slotSums AS (
SELECT
facid,
SUM(slots) AS "Total Slots"
FROM
cd.bookings
GROUP BY
facid
)
SELECT
facid,
"Total Slots"
FROM
slotSums
WHERE
"Total Slots" = (
SELECT
MAX("Total Slots")
FROM
slotSums
);
This is a very clean solution in terms of thought process (and the query really is not all that bad in terms of how messy it is).
Using the DENSE_RANK() window function:
Lastly, this is a great opportunity to use the DENSE_RANK() window function, where DENSE_RANK() is used to assign a rank to each row within a partition of a result set, with no gaps in ranking values (thus overcoming the issue we encountered earlier of possibly not returing every facility with the maximum number of bookings in the case of a tie):
SELECT
facid,
"Total Slots"
FROM
(
SELECT
B.facid,
SUM(B.slots) AS "Total Slots",
DENSE_RANK() OVER (
ORDER BY SUM(B.slots) DESC
) slotsRank
FROM
cd.bookings B
GROUP BY
B.facid
) X
WHERE
slotsRank = 1;
This is probably the clearest and cleanest solution for this problem.
SELECT
facid,
SUM(slots) AS "Total Slots"
FROM
cd.bookings
GROUP BY
facid
ORDER BY
SUM(slots) DESC
LIMIT
1;
Let's start off with what's arguably the simplest way to do this: produce a list of facility IDs and the total number of slots used, order by the total number of slots used, and pick only the top result.
It's worth realising, though, that this method has a significant weakness. In the event of a tie, we will still only get one result! To get all the relevant results, we might try using the MAX aggregate function, something like below:
SELECT
facid,
MAX(totalslots)
FROM
(
SELECT
facid,
SUM(slots) AS totalslots
FROM
cd.bookings
GROUP BY
facid
) AS sub
GROUP BY
facid;
The intent of this query is to get the highest totalslots value and its associated facid(s). Unfortunately, this just won't work! In the event of multiple facids having the same number of slots booked, it would be ambiguous which facid should be paired up with the single (or scalar) value coming out of the MAX function. This means that Postgres will tell you that facid ought to be in a GROUP BY section, which won't produce the results we're looking for.
Let's take a first stab at a working query:
SELECT
facid,
SUM(slots) AS totalslots
FROM
cd.bookings
GROUP BY
facid
HAVING
SUM(slots) = (
SELECT
MAX(sum2.totalslots)
FROM
(
SELECT
SUM(slots) AS totalslots
FROM
cd.bookings
GROUP BY
facid
) AS sum2
);
The query produces a list of facility IDs and number of slots used, and then uses a HAVING clause that works out the maximum Total Slots value. We're essentially saying: 'produce a list of facids and their number of slots booked, and filter out all the ones that doen't have a number of slots booked equal to the maximum.'
Useful as HAVING is, however, our query is pretty ugly. To improve on that, let's introduce another new concept: Common Table Expressions (CTEs). CTEs can be thought of as allowing you to define a database view inline in your query. It's really helpful in situations like this, where you're having to repeat yourself a lot.
CTEs are declared in the form WITH CTE Name as (SQL-Expression). You can see our query redefined to use a CTE below:
WITH sum AS (
SELECT
facid,
SUM(slots) AS totalslots
FROM
cd.bookings
GROUP BY
facid
)
SELECT
facid,
totalslots
FROM
sum
WHERE
totalslots = (
SELECT
MAX(totalslots)
FROM
sum
);
You can see that we've factored out our repeated selections from cd.bookings into a single CTE, and made the query a lot simpler to read in the process!
BUT WAIT. There's more. It's also possible to complete this problem using Window Functions. We'll leave these until later, but even better solutions to problems like these are available.
That's a lot of information for a single exercise. Don't worry too much if you don't get it all right now - we'll reuse these concepts in later exercises.
List the total slots booked per facility per month, part 2
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a list of the total number of slots booked per facility per month in the year of 2012. In this version, include output rows containing totals for all months per facility, and a total for all months for all facilities. The output table should consist of facid, month, and slots, sorted by the id and month. When calculating the aggregated values for all months and all facids, return null values in the month and facid columns.
┌───────┬───────┬───────┐
│ facid │ month │ slots │
├───────┼───────┼───────┤
│ 0 │ 7 │ 270 │
│ 0 │ 8 │ 459 │
│ 0 │ 9 │ 591 │
│ 0 │ │ 1320 │
│ 1 │ 7 │ 207 │
│ 1 │ 8 │ 483 │
│ 1 │ 9 │ 588 │
│ 1 │ │ 1278 │
│ 2 │ 7 │ 180 │
│ 2 │ 8 │ 459 │
│ 2 │ 9 │ 570 │
│ 2 │ │ 1209 │
│ 3 │ 7 │ 104 │
│ 3 │ 8 │ 304 │
│ 3 │ 9 │ 422 │
│ 3 │ │ 830 │
│ 4 │ 7 │ 264 │
│ 4 │ 8 │ 492 │
│ 4 │ 9 │ 648 │
│ 4 │ │ 1404 │
│ 5 │ 7 │ 24 │
│ 5 │ 8 │ 82 │
│ 5 │ 9 │ 122 │
│ 5 │ │ 228 │
│ 6 │ 7 │ 164 │
│ 6 │ 8 │ 400 │
│ 6 │ 9 │ 540 │
│ 6 │ │ 1104 │
│ 7 │ 7 │ 156 │
│ 7 │ 8 │ 326 │
│ 7 │ 9 │ 426 │
│ 7 │ │ 908 │
│ 8 │ 7 │ 117 │
│ 8 │ 8 │ 322 │
│ 8 │ 9 │ 471 │
│ 8 │ │ 910 │
│ │ │ 9191 │
└───────┴───────┴───────┘
(37 rows)
Look up Postgres' ROLLUP operator.
SELECT
B.facid,
EXTRACT(MONTH FROM B.starttime) AS month,
SUM(B.slots) AS slots
FROM
cd.bookings B
WHERE
B.starttime >= '2012-01-01' AND B.starttime < '2013-01-01'
GROUP BY
ROLLUP(B.facid, EXTRACT(MONTH FROM B.starttime))
ORDER BY
B.facid ASC, month ASC;
SELECT
facid,
EXTRACT(
MONTH
FROM
starttime
) AS month,
SUM(slots) AS slots
FROM
cd.bookings
WHERE
starttime >= '2012-01-01'
AND starttime < '2013-01-01'
GROUP BY
ROLLUP(facid, month)
ORDER BY
facid,
month;
When we are doing data analysis, we sometimes want to perform multiple levels of aggregation to allow ourselves to 'zoom' in and out to different depths. In this case, we might be looking at each facility's overall usage, but then want to dive in to see how they've performed on a per-month basis. Using the SQL we know so far, it's quite cumbersome to produce a single query that does what we want - we effectively have to resort to concatenating multiple queries using UNION ALL:
SELECT facid, EXTRACT(MONTH FROM starttime) AS month, SUM(slots) AS slots
FROM cd.bookings
WHERE
starttime >= '2012-01-01'
AND starttime < '2013-01-01'
GROUP BY facid, month
UNION ALL
SELECT facid, null, SUM(slots) AS slots
FROM cd.bookings
WHERE
starttime >= '2012-01-01'
AND starttime < '2013-01-01'
GROUP BY facid
UNION ALL
SELECT null, null, SUM(slots) AS slots
FROM cd.bookings
WHERE
starttime >= '2012-01-01'
AND starttime < '2013-01-01'
ORDER BY facid, month;
As you can see, each subquery performs a different level of aggregation, and we just combine the results. We can clean this up a lot by factoring out commonalities using a CTE:
WITH bookings AS (
SELECT facid, EXTRACT(MONTH FROM starttime) AS month, slots
FROM cd.bookings
WHERE
starttime >= '2012-01-01'
AND starttime < '2013-01-01'
)
SELECT facid, month, SUM(slots) FROM bookings GROUP BY facid, month
UNION ALL
SELECT facid, null, SUM(slots) FROM bookings GROUP BY facid
UNION ALL
SELECT null, null, SUM(slots) FROM bookings
ORDER BY facid, month;
This version is not excessively hard on the eyes, but it becomes cumbersome as the number of aggregation columns increases. Fortunately, PostgreSQL 9.5 introduced support for the ROLLUP operator, which we've used to simplify our accepted answer.
ROLLUP produces a hierarchy of aggregations in the order passed into it: for example, ROLLUP(facid, month) outputs aggregations on (facid, month), (facid), and (). If we wanted an aggregation of all facilities for a month (instead of all months for a facility) we'd have to reverse the order, using ROLLUP(month, facid). Alternatively, if we instead want all possible permutations of the columns we pass in, we can use CUBE rather than ROLLUP. This will produce (facid, month), (month), (facid), and ().
ROLLUP and CUBE are special cases of GROUPING SETS. GROUPING SETS allow you to specify the exact aggregation permutations you want: you could, for example, ask for just (facid, month) and (facid), skipping the top-level aggregation.
List the total hours booked per named facilit
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a list of the total number of hours booked per facility, remembering that a slot lasts half an hour. The output table should consist of the facility id, name, and hours booked, sorted by facility id. Try formatting the hours to two decimal places.
┌───────┬─────────────────┬────────────┐
│ facid │ name │ totalslots │
├───────┼─────────────────┼────────────┤
│ 0 │ Tennis Court 1 │ 660.00 │
│ 1 │ Tennis Court 2 │ 639.00 │
│ 2 │ Badminton Court │ 604.50 │
│ 3 │ Table Tennis │ 415.00 │
│ 4 │ Massage Room 1 │ 702.00 │
│ 5 │ Massage Room 2 │ 114.00 │
│ 6 │ Squash Court │ 552.00 │
│ 7 │ Snooker Table │ 454.00 │
│ 8 │ Pool Table │ 455.50 │
└───────┴─────────────────┴────────────┘
(9 rows)
Remember that in Postgres, dividing two integers together causes an integer division. Here you want a floating point division. For formatting the hours, take a look at the to_char function, remembering to trim any leftover whitespace.
- Divide by a float to ensure you retain decimal places (Postgres uses integer division otherwise)
- In general, group by all columns you do not have an aggregate on
- With
TO_CHAR, it seems there is no better way than to simply have a ton of9s prepending the format and then simplyTRIMthe whitespace off.
SELECT
F.facid,
F.name,
TRIM(TO_CHAR((SUM(B.slots) * 30) / 60.0, '999999999999999D99')) AS totalslots
FROM cd.bookings B
INNER JOIN cd.facilities F ON B.facid = F.facid
GROUP BY
F.facid, F.name
ORDER BY
F.facid;
SELECT facs.facid, facs.name,
TRIM(TO_CHAR(SUM(bks.slots)/2.0, '9999999999999999D99')) AS "Total Hours"
FROM cd.bookings bks
INNER JOIN cd.facilities facs
ON facs.facid = bks.facid
GROUP BY facs.facid, facs.name
ORDER BY facs.facid;
There's a few little pieces of interest in this question. Firstly, you can see that our aggregation works just fine when we join to another table on a 1:1 basis. Also note that we group by both facs.facid and facs.name. This might seem odd: after all, since facid is the primary key of the facilities table, each facid has exactly one name, and grouping by both fields is the same as grouping by facid alone. In fact, you'll find that if you remove facs.name from the GROUP BY clause, the query works just fine: Postgres works out that this 1:1 mapping exists, and doesn't insist that we group by both columns.
Unfortunately, depending on which database system we use, validation might not be so smart, and may not realise that the mapping is strictly 1:1. That being the case, if there were multiple names for each facid and we hadn't grouped by name, the DBMS would have to choose between multiple (equally valid) choices for the name. Since this is invalid, the database system will insist that we group by both fields. In general, I recommend grouping by all columns you don't have an aggregate function on: this will ensure better cross-platform compatibility.
Next up is the division. Those of you familiar with MySQL may be aware that integer divisions are automatically cast to floats. Postgres is a little more traditional in this respect, and expects you to tell it if you want a floating point division. You can do that easily in this case by dividing by 2.0 rather than 2.
Finally, let's take a look at formatting. The TO_CHAR function converts values to character strings. It takes a formatting string, which we specify as (up to) lots of numbers before the decimal place, decimal place, and two numbers after the decimal place. The output of this function can be prepended with a space, which is why we include the outer TRIM function.
List each member's first booking after September 1st 2012
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a list of each member name, id, and their first booking after September 1st 2012. Order by member ID.
┌───────────────────┬───────────┬───────┬─────────────────────┐
│ surname │ firstname │ memid │ starttime │
├───────────────────┼───────────┼───────┼─────────────────────┤
│ GUEST │ GUEST │ 0 │ 2012-09-01 08:00:00 │
│ Smith │ Darren │ 1 │ 2012-09-01 09:00:00 │
│ Smith │ Tracy │ 2 │ 2012-09-01 11:30:00 │
│ Rownam │ Tim │ 3 │ 2012-09-01 16:00:00 │
│ Joplette │ Janice │ 4 │ 2012-09-01 15:00:00 │
│ Butters │ Gerald │ 5 │ 2012-09-02 12:30:00 │
│ Tracy │ Burton │ 6 │ 2012-09-01 15:00:00 │
│ Dare │ Nancy │ 7 │ 2012-09-01 12:30:00 │
│ Boothe │ Tim │ 8 │ 2012-09-01 08:30:00 │
│ Stibbons │ Ponder │ 9 │ 2012-09-01 11:00:00 │
│ Owen │ Charles │ 10 │ 2012-09-01 11:00:00 │
│ Jones │ David │ 11 │ 2012-09-01 09:30:00 │
│ Baker │ Anne │ 12 │ 2012-09-01 14:30:00 │
│ Farrell │ Jemima │ 13 │ 2012-09-01 09:30:00 │
│ Smith │ Jack │ 14 │ 2012-09-01 11:00:00 │
│ Bader │ Florence │ 15 │ 2012-09-01 10:30:00 │
│ Baker │ Timothy │ 16 │ 2012-09-01 15:00:00 │
│ Pinker │ David │ 17 │ 2012-09-01 08:30:00 │
│ Genting │ Matthew │ 20 │ 2012-09-01 18:00:00 │
│ Mackenzie │ Anna │ 21 │ 2012-09-01 08:30:00 │
│ Coplin │ Joan │ 22 │ 2012-09-02 11:30:00 │
│ Sarwin │ Ramnaresh │ 24 │ 2012-09-04 11:00:00 │
│ Jones │ Douglas │ 26 │ 2012-09-08 13:00:00 │
│ Rumney │ Henrietta │ 27 │ 2012-09-16 13:30:00 │
│ Farrell │ David │ 28 │ 2012-09-18 09:00:00 │
│ Worthington-Smyth │ Henry │ 29 │ 2012-09-19 09:30:00 │
│ Purview │ Millicent │ 30 │ 2012-09-19 11:30:00 │
│ Tupperware │ Hyacinth │ 33 │ 2012-09-20 08:00:00 │
│ Hunt │ John │ 35 │ 2012-09-23 14:00:00 │
│ Crumpet │ Erica │ 36 │ 2012-09-27 11:30:00 │
└───────────────────┴───────────┴───────┴─────────────────────┘
(30 rows)
Take a look at the MIN aggregate function.
SELECT
M.surname,
M.firstname,
M.memid,
MIN(B.starttime) AS starttime
FROM
cd.bookings B
INNER JOIN cd.members M ON B.memid = M.memid
WHERE
B.starttime >= '2012-09-01'
GROUP BY
M.surname, M.firstname, M.memid
ORDER BY
M.memid;
SELECT mems.surname, mems.firstname, mems.memid, MIN(bks.starttime) AS starttime
FROM cd.bookings bks
INNER JOIN cd.members mems ON
mems.memid = bks.memid
WHERE starttime >= '2012-09-01'
GROUP BY mems.surname, mems.firstname, mems.memid
ORDER BY mems.memid;
This answer demonstrates the use of aggregate functions on dates. MIN works exactly as you'd expect, pulling out the lowest possible date in the result set. To make this work, we need to ensure that the result set only contains dates from September onwards. We do this using the WHERE clause.
You might typically use a query like this to find a customer's next booking. You can use this by replacing the date '2012-09-01' with the function now().
Produce a list of member names, with each row containing the total member count
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a list of member names, with each row containing the total member count. Order by join date, and include guest members.
┌───────┬───────────┬───────────────────┐
│ count │ firstname │ surname │
├───────┼───────────┼───────────────────┤
│ 31 │ GUEST │ GUEST │
│ 31 │ Darren │ Smith │
│ 31 │ Tracy │ Smith │
│ 31 │ Tim │ Rownam │
│ 31 │ Janice │ Joplette │
│ 31 │ Gerald │ Butters │
│ 31 │ Burton │ Tracy │
│ 31 │ Nancy │ Dare │
│ 31 │ Tim │ Boothe │
│ 31 │ Ponder │ Stibbons │
│ 31 │ Charles │ Owen │
│ 31 │ David │ Jones │
│ 31 │ Anne │ Baker │
│ 31 │ Jemima │ Farrell │
│ 31 │ Jack │ Smith │
│ 31 │ Florence │ Bader │
│ 31 │ Timothy │ Baker │
│ 31 │ David │ Pinker │
│ 31 │ Matthew │ Genting │
│ 31 │ Anna │ Mackenzie │
│ 31 │ Joan │ Coplin │
│ 31 │ Ramnaresh │ Sarwin │
│ 31 │ Douglas │ Jones │
│ 31 │ Henrietta │ Rumney │
│ 31 │ David │ Farrell │
│ 31 │ Henry │ Worthington-Smyth │
│ 31 │ Millicent │ Purview │
│ 31 │ Hyacinth │ Tupperware │
│ 31 │ John │ Hunt │
│ 31 │ Erica │ Crumpet │
│ 31 │ Darren │ Smith │
└───────┴───────────┴───────────────────┘
(31 rows)
Read up on the COUNT window function.
Here is the standard approach given what we have looked at so far concerning subqueries and the like:
SELECT
(SELECT COUNT(*) FROM cd.members) AS count,
firstname,
surname
FROM
cd.members
ORDER BY
joindate;
But we can do something similar with window functions, where there are a number of different dedicated window functions (e.g., DENSE_RANK) but AVG(), MIN(), MAX(), SUM(), and COUNT() can also be used as window functions:
SELECT
COUNT(*) OVER(), firstname, surname
FROM
cd.members
ORDER BY
joindate;
SELECT COUNT(*) OVER(), firstname, surname
FROM cd.members
ORDER BY joindate;
Using the knowledge we've built up so far, the most obvious answer to this is below. We use a subquery because otherwise SQL will require us to group by firstname and surname, producing a different result to what we're looking for.
SELECT (SELECT COUNT(*) FROM cd.members) AS count, firstname, surname
FROM cd.members
ORDER BY joindate;
There's nothing at all wrong with this answer, but we've chosen a different approach to introduce a new concept called window functions. Window functions provide enormously powerful capabilities, in a form often more convenient than the standard aggregation functions. While this exercise is only a toy, we'll be working on more complicated examples in the near future.
Window functions operate on the result set of your (sub-)query, after the WHERE clause and all standard aggregation. They operate on a window of data. By default this is unrestricted: the entire result set, but it can be restricted to provide more useful results. For example, suppose instead of wanting the count of all members, we want the count of all members who joined in the same month as that member:
SELECT COUNT(*) OVER(PARTITION BY DATE_TRUNC('month',joindate)),
firstname, surname
FROM cd.members
ORDER BY joindate;
In this example, we partition the data by month. For each row the window function operates over, the window is any rows that have a joindate in the same month. The window function thus produces a count of the number of members who joined in that month.
You can go further. Imagine if, instead of the total number of members who joined that month, you want to know what number joinee they were that month. You can do this by adding in an ORDER BY to the window function:
SELECT COUNT(*) OVER(PARTITION BY DATE_TRUNC('month',joindate) ORDER BY joindate),
firstname, surname
FROM cd.members
ORDER BY joindate;
The ORDER BY changes the window again. Instead of the window for each row being the entire partition, the window goes from the start of the partition to the current row, and not beyond. Thus, for the first member who joins in a given month, the count is 1. For the second, the count is 2, and so on.
One final thing that's worth mentioning about window functions: you can have multiple unrelated ones in the same query. Try out the query below for an example - you'll see the numbers for the members going in opposite directions! This flexibility can lead to more concise, readable, and maintainable queries.
SELECT COUNT(*) OVER(PARTITION BY DATE_TRUNC('month',joindate) ORDER BY joindate ASC),
COUNT(*) OVER(PARTITION BY DATE_TRUNC('month',joindate) ORDER BY joindate DESC),
firstname, surname
FROM cd.members
ORDER BY joindate;
Window functions are extraordinarily powerful, and they will change the way you write and think about SQL. Make good use of them!
Produce a numbered list of members
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a monotonically increasing numbered list of members (including guests), ordered by their date of joining. Remember that member IDs are not guaranteed to be sequential.
┌────────────┬───────────┬───────────────────┐
│ row_number │ firstname │ surname │
├────────────┼───────────┼───────────────────┤
│ 1 │ GUEST │ GUEST │
│ 2 │ Darren │ Smith │
│ 3 │ Tracy │ Smith │
│ 4 │ Tim │ Rownam │
│ 5 │ Janice │ Joplette │
│ 6 │ Gerald │ Butters │
│ 7 │ Burton │ Tracy │
│ 8 │ Nancy │ Dare │
│ 9 │ Tim │ Boothe │
│ 10 │ Ponder │ Stibbons │
│ 11 │ Charles │ Owen │
│ 12 │ David │ Jones │
│ 13 │ Anne │ Baker │
│ 14 │ Jemima │ Farrell │
│ 15 │ Jack │ Smith │
│ 16 │ Florence │ Bader │
│ 17 │ Timothy │ Baker │
│ 18 │ David │ Pinker │
│ 19 │ Matthew │ Genting │
│ 20 │ Anna │ Mackenzie │
│ 21 │ Joan │ Coplin │
│ 22 │ Ramnaresh │ Sarwin │
│ 23 │ Douglas │ Jones │
│ 24 │ Henrietta │ Rumney │
│ 25 │ David │ Farrell │
│ 26 │ Henry │ Worthington-Smyth │
│ 27 │ Millicent │ Purview │
│ 28 │ Hyacinth │ Tupperware │
│ 29 │ John │ Hunt │
│ 30 │ Erica │ Crumpet │
│ 31 │ Darren │ Smith │
└────────────┴───────────┴───────────────────┘
(31 rows)
Read up on the ROW_NUMBER window function.
SELECT
ROW_NUMBER() OVER(ORDER BY joindate) AS row_number,
firstname,
surname
FROM
cd.members;
SELECT ROW_NUMBER() OVER(ORDER BY joindate), firstname, surname
FROM cd.members
ORDER BY joindate;
This exercise is a simple bit of window function practise! You could just as easily use count(*) over(order by joindate) here, so don't worry if you used that instead.
In this query, we don't define a partition, meaning that the partition is the entire dataset. Since we define an order for the window function, for any given row the window is: start of the dataset -> current row.
Output the facility id that has the highest number of slots booked, again
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Output the facility id that has the highest number of slots booked. Ensure that in the event of a tie, all tieing results get output.
┌───────┬─────────────┐
│ facid │ Total Slots │
├───────┼─────────────┤
│ 4 │ 1404 │
└───────┴─────────────┘
(1 row)
This one's a little bit tough. You'll need the RANK window function, and it's worth noting that it's possible to use an aggregate function inside the ORDER BY clause of a window function.
SELECT
facid,
"Total Slots"
FROM
(
SELECT
B.facid,
SUM(B.slots) AS "Total Slots",
DENSE_RANK() OVER (
ORDER BY SUM(B.slots) DESC
) slotsRank
FROM
cd.bookings B
GROUP BY
B.facid
) X
WHERE
slotsRank = 1;
SELECT facid, total FROM (
SELECT facid, SUM(slots) total, RANK() OVER (ORDER BY SUM(slots) DESC) rank
FROM cd.bookings
GROUP BY facid
) AS ranked
WHERE rank = 1;
You may recall that this is a problem we've already solved in an earlier exercise. We came up with an answer something like below, which we then cut down using CTEs:
SELECT facid, SUM(slots) AS totalslots
FROM cd.bookings
GROUP BY facid
HAVING SUM(slots) = (SELECT max(sum2.totalslots) FROM
(SELECT SUM(slots) AS totalslots
FROM cd.bookings
GROUP BY facid
) AS sum2);
Once we've cleaned it up, this solution is perfectly adequate. Explaining how the query works makes it seem a little odd, though - 'find the number of slots booked by the best facility. Calculate the total slots booked for each facility, and return only the rows where the slots booked are the same as for the best'. Wouldn't it be nicer to be able to say 'calculate the number of slots booked for each facility, rank them, and pick out any at rank 1'?
Fortunately, window functions allow us to do this - although it's fair to say that doing so is not trivial to the untrained eye. The first key piece of information is the existence of the RANK function. This ranks values based on the ORDER BY that is passed to it. If there's a tie for (say) second place), the next gets ranked at position 4. So, what we need to do is get the number of slots for each facility, rank them, and pick off the ones at the top rank. A first pass at this might look something like the below:
SELECT facid, total FROM (
SELECT facid, total, RANK() OVER (ORDER BY total DESC) rank FROM (
SELECT facid, SUM(slots) total
FROM cd.bookings
GROUP BY facid
) AS sumslots
) AS ranked
WHERE rank = 1;
The inner query calculates the total slots booked, the middle one ranks them, and the outer one creams off the top ranked. We can actually tidy this up a little: recall that window function get applied pretty late in the select function, after aggregation. That being the case, we can move the aggregation into the ORDER BY part of the function, as shown in the approved answer.
While the window function approach isn't massively simpler in terms of lines of code, it arguably makes more semantic sense.
Rank members by (rounded) hours used
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a list of members (including guests), along with the number of hours they've booked in facilities, rounded to the nearest ten hours. Rank them by this rounded figure, producing output of first name, surname, rounded hours, rank. Sort by rank, surname, and first name.
┌───────────┬───────────────────┬───────┬──────┐
│ firstname │ surname │ hours │ rank │
├───────────┼───────────────────┼───────┼──────┤
│ GUEST │ GUEST │ 1200 │ 1 │
│ Darren │ Smith │ 340 │ 2 │
│ Tim │ Rownam │ 330 │ 3 │
│ Tim │ Boothe │ 220 │ 4 │
│ Tracy │ Smith │ 220 │ 4 │
│ Gerald │ Butters │ 210 │ 6 │
│ Burton │ Tracy │ 180 │ 7 │
│ Charles │ Owen │ 170 │ 8 │
│ Janice │ Joplette │ 160 │ 9 │
│ Anne │ Baker │ 150 │ 10 │
│ Timothy │ Baker │ 150 │ 10 │
│ David │ Jones │ 150 │ 10 │
│ Nancy │ Dare │ 130 │ 13 │
│ Florence │ Bader │ 120 │ 14 │
│ Anna │ Mackenzie │ 120 │ 14 │
│ Ponder │ Stibbons │ 120 │ 14 │
│ Jack │ Smith │ 110 │ 17 │
│ Jemima │ Farrell │ 90 │ 18 │
│ David │ Pinker │ 80 │ 19 │
│ Ramnaresh │ Sarwin │ 80 │ 19 │
│ Matthew │ Genting │ 70 │ 21 │
│ Joan │ Coplin │ 50 │ 22 │
│ David │ Farrell │ 30 │ 23 │
│ Henry │ Worthington-Smyth │ 30 │ 23 │
│ John │ Hunt │ 20 │ 25 │
│ Douglas │ Jones │ 20 │ 25 │
│ Millicent │ Purview │ 20 │ 25 │
│ Henrietta │ Rumney │ 20 │ 25 │
│ Erica │ Crumpet │ 10 │ 29 │
│ Hyacinth │ Tupperware │ 10 │ 29 │
└───────────┴───────────────────┴───────┴──────┘
(30 rows)
You'll need the RANK window function again. You can use integer arithmetic to accomplish rounding.
It is helpful to utilize an inline view here to make the initial SELECT statement clearer (you cannot ORDER BY hours unless you have an inline view).
SELECT
firstname,
surname,
hours,
RANK() OVER(ORDER BY hours DESC) AS rank
FROM
(
SELECT
M.firstname,
M.surname,
ROUND(SUM(B.slots) / 2, -1) AS hours
FROM
cd.members M
INNER JOIN cd.bookings B ON M.memid = B.memid
GROUP BY
M.firstname, M.surname
ORDER BY
Hours DESC
) X
ORDER BY
rank, surname, firstname;
SELECT firstname, surname,
((SUM(bks.slots)+10)/20)*10 AS hours,
RANK() OVER (ORDER BY ((SUM(bks.slots)+10)/20)*10 DESC) AS rank
FROM cd.bookings bks
INNER JOIN cd.members mems
ON bks.memid = mems.memid
GROUP BY mems.memid
ORDER BY rank, surname, firstname;
This answer isn't a great stretch over our previous exercise, although it does illustrate the function of RANK better. You can see that some of the clubgoers have an equal rounded number of hours booked in, and their rank is the same. If position 2 is shared between two members, the next one along gets position 4. There's a different function, DENSE_RANK, that would assign that member position 3 instead.
It's worth noting the technique we use to do rounding here. Adding 5, dividing by 10, and multiplying by 10 has the effect (thanks to integer arithmetic cutting off fractions) of rounding a number to the nearest 10. In our case, because slots are half an hour, we need to add 10, divide by 20, and multiply by 10. One could certainly make the argument that we should do the slots -> hours conversion independently of the rounding, which would increase clarity.
Talking of clarity, this rounding malarky is starting to introduce a noticeable amount of code repetition. At this point it's a judgement call, but you may wish to factor it out using a subquery as below:
SELECT firstname, surname, hours, RANK() OVER (ORDER BY hours DESC) FROM
(SELECT firstname, surname,
((SUM(bks.slots)+10)/20)*10 AS hours
FROM cd.bookings bks
INNER JOIN cd.members mems
ON bks.memid = mems.memid
GROUP BY mems.memid
) AS subq
ORDER BY rank, surname, firstname;
Find the top three revenue generating facilities
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a list of the top three revenue generating facilities (including ties). Output facility name and rank, sorted by rank and facility name.
┌────────────────┬──────┐
│ name │ rank │
├────────────────┼──────┤
│ Massage Room 1 │ 1 │
│ Massage Room 2 │ 2 │
│ Tennis Court 2 │ 3 │
└────────────────┴──────┘
(3 rows)
Yet another question based on the RANK window function! Remember the relative complexity of calculating the revenue of a facility, since you need to count for the different costs for the GUEST user..
SELECT
name,
rank
FROM
(
SELECT
name,
DENSE_RANK() OVER(ORDER BY total_revenue DESC) AS rank
FROM
(
SELECT
F.name,
SUM(B.slots *
CASE
WHEN B.memid = 0 THEN F.guestcost
ELSE
F.membercost
END
) AS total_revenue
FROM
cd.bookings B
INNER JOIN cd.facilities F ON B.facid = F.facid
GROUP BY
F.name
) X
) Y
WHERE
rank <= 3;
SELECT name, rank FROM (
SELECT facs.name AS name, RANK() OVER (ORDER BY SUM(CASE
WHEN memid = 0 THEN slots * facs.guestcost
ELSE slots * membercost
END) DESC) AS rank
FROM cd.bookings bks
INNER JOIN cd.facilities facs
ON bks.facid = facs.facid
GROUP BY facs.name
) AS subq
WHERE rank <= 3
ORDER BY rank;
This question doesn't introduce any new concepts, and is just intended to give you the opportunity to practise what you already know. We use the CASE statement to calculate the revenue for each slot, and aggregate that on a per-facility basis using SUM. We then use the RANK window function to produce a ranking, wrap it all up in a subquery, and extract everything with a rank less than or equal to 3.
Classify facilities by value
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Classify facilities into equally sized groups of high, average, and low based on their revenue. Order by classification and facility name.
┌─────────────────┬─────────┐
│ name │ revenue │
├─────────────────┼─────────┤
│ Massage Room 1 │ high │
│ Massage Room 2 │ high │
│ Tennis Court 2 │ high │
│ Badminton Court │ average │
│ Squash Court │ average │
│ Tennis Court 1 │ average │
│ Pool Table │ low │
│ Snooker Table │ low │
│ Table Tennis │ low │
└─────────────────┴─────────┘
(9 rows)
Investigate the NTILE window function.
SELECT
name,
CASE
WHEN bucketNum = 1 THEN 'high'
WHEN bucketNum = 2 THEN 'average'
ELSE
'low'
END AS revenue
FROM
(
SELECT
F.name,
NTILE(3) OVER(ORDER BY SUM(B.slots *
CASE
WHEN B.memid = 0 THEN F.guestcost
ELSE
F.membercost
END) DESC) bucketNum
FROM
cd.bookings B
INNER JOIN cd.facilities F ON B.facid = F.facid
GROUP BY
F.name
ORDER BY
bucketNum, F.name
) X;
SELECT name, CASE WHEN class=1 THEN 'high'
WHEN class=2 THEN 'average'
ELSE 'low'
END revenue
FROM (
SELECT facs.name AS name, NTILE(3) OVER (ORDER BY SUM(CASE
WHEN memid = 0 THEN slots * facs.guestcost
ELSE slots * membercost
END) DESC) AS class
FROM cd.bookings bks
INNER JOIN cd.facilities facs
ON bks.facid = facs.facid
GROUP BY facs.name
) AS subq
ORDER BY class, name;
This exercise should mostly use familiar concepts, although we do introduce the NTILE window function. NTILE groups values into a passed-in number of groups, as evenly as possible. It outputs a number from 1->number of groups. We then use a CASE statement to turn that number into a label!
Calculate the payback time for each facility
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Based on the 3 complete months of data so far, calculate the amount of time each facility will take to repay its cost of ownership. Remember to take into account ongoing monthly maintenance. Output facility name and payback time in months, order by facility name. Don't worry about differences in month lengths, we're only looking for a rough value here!
┌─────────────────┬────────────────────────┐
│ name │ months │
├─────────────────┼────────────────────────┤
│ Badminton Court │ 6.8317677198975235 │
│ Massage Room 1 │ 0.18885741265344664778 │
│ Massage Room 2 │ 1.7621145374449339 │
│ Pool Table │ 5.3333333333333333 │
│ Snooker Table │ 6.9230769230769231 │
│ Squash Court │ 1.1339582703356516 │
│ Table Tennis │ 6.4000000000000000 │
│ Tennis Court 1 │ 2.2624434389140271 │
│ Tennis Court 2 │ 1.7505470459518600 │
└─────────────────┴────────────────────────┘
(9 rows)
There's no need to use window functions to solve this problem. Hard-code the number of months for an easy time, calculate them for a tougher one.
SELECT
F.name,
F.initialoutlay / (SUM(B.slots *
CASE
WHEN B.memid = 0 THEN F.guestcost
ELSE
F.membercost
END
) / 3.0 - F.monthlymaintenance) AS months
FROM
cd.bookings B
INNER JOIN cd.facilities F ON B.facid = F.facid
GROUP BY
F.name, F.monthlymaintenance, F.initialoutlay
ORDER BY
F.name;
SELECT facs.name AS name,
facs.initialoutlay/((SUM(CASE
WHEN memid = 0 THEN slots * facs.guestcost
ELSE slots * membercost
END)/3) - facs.monthlymaintenance) AS months
FROM cd.bookings bks
INNER JOIN cd.facilities facs
ON bks.facid = facs.facid
GROUP BY facs.facid
ORDER BY name;
In contrast to all our recent exercises, there's no need to use window functions to solve this problem: it's just a bit of maths involving monthly revenue, initial outlay, and monthly maintenance. Again, for production code you might want to clarify what's going on a little here using a subquery (although since we've hard-coded the number of months, putting this into production is unlikely!). A tidied-up version might look like:
SELECT name,
initialoutlay / (monthlyrevenue - monthlymaintenance) AS repaytime
FROM
(SELECT facs.name AS name,
facs.initialoutlay AS initialoutlay,
facs.monthlymaintenance AS monthlymaintenance,
SUM(CASE
WHEN memid = 0 THEN slots * facs.guestcost
ELSE slots * membercost
END)/3 AS monthlyrevenue
FROM cd.bookings bks
INNER JOIN cd.facilities facs
ON bks.facid = facs.facid
GROUP BY facs.facid
) AS subq
ORDER BY name;
But, I hear you ask, what would an automatic version of this look like? One that didn't need to have a hard-coded number of months in it? That's a little more complicated, and involves some date arithmetic. I've factored that out into a CTE to make it a little more clear.
WITH monthdata AS (
SELECT mincompletemonth,
maxcompletemonth,
(EXTRACT(YEAR FROM maxcompletemonth)*12) +
EXTRACT(MONTH FROM maxcompletemonth) -
(EXTRACT(YEAR FROM mincompletemonth)*12) -
EXTRACT(MONTH FROM mincompletemonth) AS nummonths
FROM (
SELECT DATE_TRUNC('month',
(SELECT MAX(starttime) FROM cd.bookings)) AS maxcompletemonth,
DATE_TRUNC('month',
(SELECT MIN(starttime) FROM cd.bookings)) AS mincompletemonth
) AS subq
)
SELECT name,
initialoutlay / (monthlyrevenue - monthlymaintenance) AS repaytime
FROM
(SELECT facs.name AS name,
facs.initialoutlay AS initialoutlay,
facs.monthlymaintenance AS monthlymaintenance,
SUM(CASE
WHEN memid = 0 then slots * facs.guestcost
ELSE slots * membercost
END)/(SELECT nummonths FROM monthdata) AS monthlyrevenue
FROM cd.bookings bks
INNER JOIN cd.facilities facs
ON bks.facid = facs.facid
WHERE bks.starttime < (SELECT maxcompletemonth FROM monthdata)
GROUP BY facs.facid
) AS subq
ORDER BY name;
This code restricts the data that goes in to complete months. It does this by selecting the maximum date, rounding down to the month, and stripping out all dates larger than that. Even this code is not completely-complete. It doesn't handle the case of a facility making a loss. Fixing that is not too hard, and is left as (another) exercise for the reader!
Calculate a rolling average of total revenue
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
For each day in August 2012, calculate a rolling average of total revenue over the previous 15 days. Output should contain date and revenue columns, sorted by the date. Remember to account for the possibility of a day having zero revenue. This one's a bit tough, so don't be afraid to check out the hint!
┌────────────┬───────────────────────┐
│ date │ revenue │
├────────────┼───────────────────────┤
│ 2012-08-01 │ 1126.8333333333333333 │
│ 2012-08-02 │ 1153.0000000000000000 │
│ 2012-08-03 │ 1162.9000000000000000 │
│ 2012-08-04 │ 1177.3666666666666667 │
│ 2012-08-05 │ 1160.9333333333333333 │
│ 2012-08-06 │ 1185.4000000000000000 │
│ 2012-08-07 │ 1182.8666666666666667 │
│ 2012-08-08 │ 1172.6000000000000000 │
│ 2012-08-09 │ 1152.4666666666666667 │
│ 2012-08-10 │ 1175.0333333333333333 │
│ 2012-08-11 │ 1176.6333333333333333 │
│ 2012-08-12 │ 1195.6666666666666667 │
│ 2012-08-13 │ 1218.0000000000000000 │
│ 2012-08-14 │ 1247.4666666666666667 │
│ 2012-08-15 │ 1274.1000000000000000 │
│ 2012-08-16 │ 1281.2333333333333333 │
│ 2012-08-17 │ 1324.4666666666666667 │
│ 2012-08-18 │ 1373.7333333333333333 │
│ 2012-08-19 │ 1406.0666666666666667 │
│ 2012-08-20 │ 1427.0666666666666667 │
│ 2012-08-21 │ 1450.3333333333333333 │
│ 2012-08-22 │ 1539.7000000000000000 │
│ 2012-08-23 │ 1567.3000000000000000 │
│ 2012-08-24 │ 1592.3333333333333333 │
│ 2012-08-25 │ 1615.0333333333333333 │
│ 2012-08-26 │ 1631.2000000000000000 │
│ 2012-08-27 │ 1659.4333333333333333 │
│ 2012-08-28 │ 1687.0000000000000000 │
│ 2012-08-29 │ 1684.6333333333333333 │
│ 2012-08-30 │ 1657.9333333333333333 │
│ 2012-08-31 │ 1703.4000000000000000 │
└────────────┴───────────────────────┘
(31 rows)
You'll need to generate a list of days: check out GENERATE_SERIES for that. You can then solve this problem using aggregate functions or window functions.
SELECT
-- for each date in August find the average revenue
-- for the last 15 days inclusive (i.e., the revenue
-- generated on August <dayNum> is *included* in the "previous
-- 15 days average revenue" calculation for August <dayNum>)
augustDays.date,
(
-- select the sum of the revenue for a sliding 15-day date range
SELECT
SUM(B.slots *
CASE
WHEN B.memid = 0 THEN F.guestcost
ELSE
F.membercost
END
) / 15 AS revenue
FROM
cd.bookings B
INNER JOIN cd.facilities F ON B.facid = F.facid
-- the "inclusive" part of the problem is why
-- we are subtracting 14 instead of 15
-- B.starttime < augustDays.date + integer '1' instead of
-- B.starttime < augustDays.date
-- the effect is that all of the augustDate.date is included
WHERE
B.starttime > augustDays.date - integer '14' AND B.starttime < augustDays.date + integer '1'
)
FROM
-- generate all dates in August
-- note that this would not work if there were a day
-- in August for which there were no booking;
-- using generate_series is definitely the way to go here
-- or use a recursive CTE to generate the dates
(
SELECT
DATE_TRUNC('day', starttime)::date AS date
FROM
cd.bookings B
WHERE
B.starttime >= '2012-08-01' AND B.starttime < '2012-09-01'
GROUP BY
DATE_TRUNC('day', starttime)::date
) augustDays
ORDER BY
augustDays.date;
SELECT dategen.date,
(
-- correlated subquery that, for each day fed into it,
-- finds the average revenue for the last 15 days
SELECT SUM(CASE
WHEN memid = 0 THEN slots * facs.guestcost
ELSE slots * membercost
END) AS rev
FROM cd.bookings bks
INNER JOIN cd.facilities facs
ON bks.facid = facs.facid
WHERE bks.starttime > dategen.date - interval '14 days'
AND bks.starttime < dategen.date + interval '1 day'
)/15 AS revenue
FROM
(
-- generates a list of days in august
SELECT CAST(GENERATE_SERIES(timestamp '2012-08-01',
'2012-08-31','1 day') AS date) AS date
) AS dategen
ORDER BY dategen.date;
There's at least two equally good solutions to this question. I've put the simplest to write as the answer, but there's also a more flexible solution that uses window functions.
Let's look at the selected answer first. When I read SQL queries, I tend to read the SELECT part of the statement last - the FROM and WHERE parts tend to be more interesting. So, what do we have in our FROM? A call to the GENERATE_SERIES function. This does pretty much what it says on the tin - generates a series of values. You can specify a start value, a stop value, and an increment. It works for integer types and dates - although, as you can see, we need to be explicit about what types are going into and out of the function. Try removing the casts, and seeing the result!
So, we've generated a timestamp for each day in August. Now, for each day, we need to generate our average. We can do this using a correlated subquery. If you remember, a correlated subquery is a subquery that uses values from the outer query. This means that it gets executed once for each result row in the outer query. This is in contrast to an uncorrelated subquery, which only has to be executed once.
If we look at our correlated subquery, we can see that it's correlated on the dategen.date field. It produces a sum of revenue for this day and the 14 days prior to it, and then divides that sum by 15. This produces the output we're looking for!
I mentioned that there's a window function-based solution for this problem as well - you can see it below. The approach we use for this is generating a list of revenue for each day, and then using window function aggregation over that list. The nice thing about this method is that once you have the per-day revenue, you can produce a wide range of results quite easily - you might, for example, want rolling averages for the previous month, 15 days, and 5 days. This is easy to do using this method, and rather harder using conventional aggregation.
SELECT date, avgrev FROM (
-- AVG over this row and the 14 rows before it.
SELECT dategen.date AS date,
AVG(revdata.rev) OVER(ORDER BY dategen.date ROWS 14 PRECEDING) AS avgrev
FROM
-- generate a list of days. This ensures that a row gets generated
-- even if the day has 0 revenue. Note that we generate days before
-- the start of october - this is because our window function needs
-- to know the revenue for those days for its calculations.
(SELECT
CAST(GENERATE_SERIES(timestamp '2012-07-10', '2012-08-31','1 day') AS date) AS date
) AS dategen
LEFT OUTER JOIN
-- left join to a table of per-day revenue
(SELECT CAST(bks.starttime AS date) AS date,
SUM(CASE
WHEN memid = 0 THEN slots * facs.guestcost
ELSE slots * membercost
END) AS rev
FROM cd.bookings bks
INNER JOIN cd.facilities facs
ON bks.facid = facs.facid
GROUP BY CAST(bks.starttime AS date)
) AS revdata
ON dategen.date = revdata.date
) AS subq
WHERE date >= '2012-08-01'
ORDER BY date;
You'll note that we've been wanting to work out daily revenue quite frequently. Rather than inserting that calculation into all our queries, which is rather messy (and will cause us a big headache if we ever change our schema), we probably want to store that information somewhere. Your first thought might be to calculate information and store it somewhere for later use. This is a common tactic for large data warehouses, but it can cause us some problems - if we ever go back and edit our data, we need to remember to recalculate. For non-enormous-scale data like we're looking at here, we can just create a view instead. A view is essentially a stored query that looks exactly like a table. Under the covers, the DBMS just subsititutes in the relevant portion of the view definition when you select data from it. They're very easy to create, as you can see below:
CREATE OR REPLACE VIEW cd.dailyrevenue AS
SELECT CAST(bks.starttime AS date) AS date,
SUM(CASE
WHEN memid = 0 THEN slots * facs.guestcost
ELSE slots * membercost
END) AS rev
FROM cd.bookings bks
INNER JOIN cd.facilities facs
ON bks.facid = facs.facid
GROUP BY CAST(bks.starttime AS date);
You can see that this makes our query an awful lot simpler!
SELECT date, avgrev FROM (
SELECT dategen.date AS date,
AVG(revdata.rev) OVER(ORDER BY dategen.date ROWS 14 PRECEDING) AS avgrev
FROM
(SELECT
CAST(GENERATE_SERIES(timestamp '2012-07-10', '2012-08-31','1 day') AS date) AS date
) AS dategen
LEFT OUTER JOIN
cd.dailyrevenue AS revdata ON dategen.date = revdata.date
) AS subq
WHERE date >= '2012-08-01'
ORDER BY date;
As well as storing frequently-used query fragments, views can be used for a variety of purposes, including restricting access to certain columns of a table.
Date
Intro
Dates/Times in SQL are a complex topic, deserving of a category of their own. They're also fantastically powerful, making it easier to work with variable-length concepts like 'months' than many programming languages.
Before getting started on this category, it's probably worth taking a look over the PostgreSQL docs page on date/time functions. You might also want to complete the aggregate functions category, since we'll use some of those capabilities in this section.
Produce a timestamp for 1 a.m. on the 31st of August 2012
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a timestamp for 1 a.m. on the 31st of August 2012.
┌─────────────────────┐
│ timestamp │
├─────────────────────┤
│ 2012-08-31 01:00:00 │
└─────────────────────┘
(1 row)
There's a bunch of ways to do this, but the easiest is probably to look at the TIMESTAMP keyword.
SELECT
CAST('2012-08-31 01:00:00' AS TIMESTAMP) AS timestamp;
SELECT
TIMESTAMP '2012-08-31 01:00:00';
Here's a pretty easy question to start off with! SQL has a bunch of different date and time types, which you can peruse at your leisure over at the excellent Postgres documentation. These basically allow you to store dates, times, or timestamps (date+time).
The approved answer is the best way to create a timestamp under normal circumstances. You can also use casts to change a correctly formatted string into a timestamp, for example:
SELECT
'2012-08-31 01:00:00' :: TIMESTAMP;
SELECT
CAST('2012-08-31 01:00:00' AS TIMESTAMP);
The former approach is a Postgres extension, while the latter is SQL-standard. You'll note that in many of our earlier questions, we've used bare strings without specifying a data type. This works because when Postgres is working with a value coming out of a timestamp column of a table (say), it knows to cast our strings to timestamps.
Timestamps can be stored with or without time zone information. We've chosen not to here, but if you like you could format the timestamp like "2012-08-31 01:00:00 +00:00", assuming UTC. Note that timestamp with time zone is a different type to timestamp - when you're declaring it, you should use TIMESTAMP WITH TIME ZONE 2012-08-31 01:00:00 +00:00.
Finally, have a bit of a play around with some of the different date/time serialisations described in the Postgres docs. You'll find that Postgres is extremely flexible with the formats it accepts, although my recommendation to you would be to use the standard serialisation we've used here - you'll find it unambiguous and easy to port to other DBs.
Subtract timestamps from each other
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Find the result of subtracting the timestamp '2012-07-30 01:00:00' from the timestamp '2012-08-31 01:00:00'.
┌──────────┐
│ interval │
├──────────┤
│ 32 days │
└──────────┘
(1 row)
You can use the '-' symbol on timestamps.
SELECT
(date '2012-08-31 01:00:00' - date '2012-07-30 01:00:00') || ' ' || 'days' AS interval;
SELECT
TIMESTAMP '2012-08-31 01:00:00' - TIMESTAMP '2012-07-30 01:00:00' AS interval;
Subtracting timestamps produces an INTERVAL data type. INTERVALs are a special data type for representing the difference between two TIMESTAMP types. When subtracting timestamps, Postgres will typically give an interval in terms of days, hours, minutes, seconds, without venturing into months. This generally makes life easier, since months are of variable lengths.
One of the useful things about intervals, though, is the fact that they can encode months. Let's imagine that I want to schedule something to occur in exactly one month's time, regardless of the length of my month. To do this, I could use [timestamp] + interval '1 month'.
Intervals stand in contrast to SQL's treatment of DATE types. Dates don't use intervals - instead, subtracting two dates will return an integer representing the number of days between the two dates. You can also add integer values to dates. This is sometimes more convenient, depending on how much intelligence you require in the handling of your dates!
Generate a list of all the dates in October 2012
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a list of all the dates in October 2012. They can be output as a timestamp (with time set to midnight) or a date.
┌─────────────────────┐
│ ts │
├─────────────────────┤
│ 2012-10-01 00:00:00 │
│ 2012-10-02 00:00:00 │
│ 2012-10-03 00:00:00 │
│ 2012-10-04 00:00:00 │
│ 2012-10-05 00:00:00 │
│ 2012-10-06 00:00:00 │
│ 2012-10-07 00:00:00 │
│ 2012-10-08 00:00:00 │
│ 2012-10-09 00:00:00 │
│ 2012-10-10 00:00:00 │
│ 2012-10-11 00:00:00 │
│ 2012-10-12 00:00:00 │
│ 2012-10-13 00:00:00 │
│ 2012-10-14 00:00:00 │
│ 2012-10-15 00:00:00 │
│ 2012-10-16 00:00:00 │
│ 2012-10-17 00:00:00 │
│ 2012-10-18 00:00:00 │
│ 2012-10-19 00:00:00 │
│ 2012-10-20 00:00:00 │
│ 2012-10-21 00:00:00 │
│ 2012-10-22 00:00:00 │
│ 2012-10-23 00:00:00 │
│ 2012-10-24 00:00:00 │
│ 2012-10-25 00:00:00 │
│ 2012-10-26 00:00:00 │
│ 2012-10-27 00:00:00 │
│ 2012-10-28 00:00:00 │
│ 2012-10-29 00:00:00 │
│ 2012-10-30 00:00:00 │
│ 2012-10-31 00:00:00 │
└─────────────────────┘
(31 rows)
Take a look at Postgres' GENERATE_SERIES function.
The instructions appear to be slightly off on this one--you need a timestamp and not just a date for the solution to pass. Otherwise, the following solution, which works in both Postgres and MySQL, should pass with just dates but no timestamps:
WITH RECURSIVE october_dates AS (
SELECT CAST('2012-10-01' AS DATE) AS october_date, 1 AS day_of_month
UNION ALL
SELECT october_date + 1, day_of_month + 1 FROM october_dates WHERE day_of_month < 31
) SELECT october_date AS ts from october_dates;
This yields the following output:
┌────────────┐
│ ts │
├────────────┤
│ 2012-10-01 │
│ 2012-10-02 │
│ 2012-10-03 │
│ 2012-10-04 │
│ 2012-10-05 │
│ 2012-10-06 │
│ 2012-10-07 │
│ 2012-10-08 │
│ 2012-10-09 │
│ 2012-10-10 │
│ 2012-10-11 │
│ 2012-10-12 │
│ 2012-10-13 │
│ 2012-10-14 │
│ 2012-10-15 │
│ 2012-10-16 │
│ 2012-10-17 │
│ 2012-10-18 │
│ 2012-10-19 │
│ 2012-10-20 │
│ 2012-10-21 │
│ 2012-10-22 │
│ 2012-10-23 │
│ 2012-10-24 │
│ 2012-10-25 │
│ 2012-10-26 │
│ 2012-10-27 │
│ 2012-10-28 │
│ 2012-10-29 │
│ 2012-10-30 │
│ 2012-10-31 │
└────────────┘
(31 rows)
But this is not acceptable for some reason on the PGExercises site. We could try another approach that is Postgres-specific that still uses WITH RECURSIVE:
This yields
┌─────────────────────┐
│ ts │
├─────────────────────┤
│ 2012-10-01 00:00:00 │
│ 2012-10-02 00:00:00 │
│ 2012-10-03 00:00:00 │
│ 2012-10-04 00:00:00 │
│ 2012-10-05 00:00:00 │
│ 2012-10-06 00:00:00 │
│ 2012-10-07 00:00:00 │
│ 2012-10-08 00:00:00 │
│ 2012-10-09 00:00:00 │
│ 2012-10-10 00:00:00 │
│ 2012-10-11 00:00:00 │
│ 2012-10-12 00:00:00 │
│ 2012-10-13 00:00:00 │
│ 2012-10-14 00:00:00 │
│ 2012-10-15 00:00:00 │
│ 2012-10-16 00:00:00 │
│ 2012-10-17 00:00:00 │
│ 2012-10-18 00:00:00 │
│ 2012-10-19 00:00:00 │
│ 2012-10-20 00:00:00 │
│ 2012-10-21 00:00:00 │
│ 2012-10-22 00:00:00 │
│ 2012-10-23 00:00:00 │
│ 2012-10-24 00:00:00 │
│ 2012-10-25 00:00:00 │
│ 2012-10-26 00:00:00 │
│ 2012-10-27 00:00:00 │
│ 2012-10-28 00:00:00 │
│ 2012-10-29 00:00:00 │
│ 2012-10-30 00:00:00 │
│ 2012-10-31 00:00:00 │
└─────────────────────┘
(31 rows)
And this is really what we are interested in. But WITH RECURSIVE is overly complicated when Postgres already provides us with an enormously useful GENERATE_SERIES function to easily accomplish this same task for us:
SELECT * FROM GENERATE_SERIES('2012-10-01'::TIMESTAMP, '2012-10-31', '1 day') ts;
This yields
┌─────────────────────┐
│ ts │
├─────────────────────┤
│ 2012-10-01 00:00:00 │
│ 2012-10-02 00:00:00 │
│ 2012-10-03 00:00:00 │
│ 2012-10-04 00:00:00 │
│ 2012-10-05 00:00:00 │
│ 2012-10-06 00:00:00 │
│ 2012-10-07 00:00:00 │
│ 2012-10-08 00:00:00 │
│ 2012-10-09 00:00:00 │
│ 2012-10-10 00:00:00 │
│ 2012-10-11 00:00:00 │
│ 2012-10-12 00:00:00 │
│ 2012-10-13 00:00:00 │
│ 2012-10-14 00:00:00 │
│ 2012-10-15 00:00:00 │
│ 2012-10-16 00:00:00 │
│ 2012-10-17 00:00:00 │
│ 2012-10-18 00:00:00 │
│ 2012-10-19 00:00:00 │
│ 2012-10-20 00:00:00 │
│ 2012-10-21 00:00:00 │
│ 2012-10-22 00:00:00 │
│ 2012-10-23 00:00:00 │
│ 2012-10-24 00:00:00 │
│ 2012-10-25 00:00:00 │
│ 2012-10-26 00:00:00 │
│ 2012-10-27 00:00:00 │
│ 2012-10-28 00:00:00 │
│ 2012-10-29 00:00:00 │
│ 2012-10-30 00:00:00 │
│ 2012-10-31 00:00:00 │
└─────────────────────┘
(31 rows)
SELECT
GENERATE_SERIES(
TIMESTAMP '2012-10-01',
TIMESTAMP '2012-10-31',
INTERVAL '1 day'
) AS ts;
One of the best features of Postgres over other DBs is a simple function called GENERATE_SERIES. This function allows you to generate a list of dates or numbers, specifying a start, an end, and an increment value. It's extremely useful for situations where you want to output, say, sales per day over the course of a month. A typical way to do that on a table containing a list of sales might be to use a SUM aggregation, grouping by the date and product type. Unfortunately, this approach has a flaw: if there are no sales for a given day, it won't show up! To make it work properly, you need to left join from a sequential list of timestamps to the aggregated data to fill in the blank spaces.
On other database systems, it's not uncommon to keep a 'calendar table' full of dates, with which you can perform these joins. Alternatively, on some systems you can write an analogue to generate_series using recursive CTEs. Fortunately for us, Postgres makes our lives a lot easier!
Get the day of the month from a timestamp
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Get the day of the month from the timestamp '2012-08-31' as an integer.
┌───────────┐
│ date_part │
├───────────┤
│ 31 │
└───────────┘
(1 row)
The easiest way to do this is with the EXTRACT function.
SELECT EXTRACT(DAY FROM '2012-08-31'::DATE);
SELECT
EXTRACT(
DAY
FROM
TIMESTAMP '2012-08-31'
);
The EXTRACT function is used for getting sections of a timestamp or interval. You can get the value of any field in the timestamp as an integer.
Work out the number of seconds between timestamps
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Work out the number of seconds between the timestamps '2012-08-31 01:00:00' and '2012-09-02 00:00:00'.
┌───────────┐
│ date_part │
├───────────┤
│ 169200 │
└───────────┘
(1 row)
You can do this by extracting the epoch from the interval between two timestamps.
SELECT
EXTRACT(EPOCH FROM '2012-09-02 00:00:00'::TIMESTAMP)
- EXTRACT(EPOCH FROM '2012-08-31 01:00:00' ::TIMESTAMP) date_part;
SELECT
EXTRACT(
EPOCH
FROM
(
TIMESTAMP '2012-09-02 00:00:00' - '2012-08-31 01:00:00'
)
);
The above answer is a Postgres-specific trick. Extracting the epoch converts an interval or timestamp into a number of seconds, or the number of seconds since epoch (January 1st, 1970) respectively. If you want the number of minutes, hours, etc you can just divide the number of seconds appropriately.
If you want to write more portable code, you will unfortunately find that you cannot use extract epoch. Instead you will need to use something like:
SELECT EXTRACT(DAY FROM ts.int)*60*60*24 +
EXTRACT(HOUR FROM ts.int)*60*60 +
EXTRACT(MINUTE FROM ts.int)*60 +
EXTRACT(SECOND FROM ts.int)
FROM
(SELECT TIMESTAMP '2012-09-02 00:00:00' - '2012-08-31 01:00:00' AS int) ts;
This is, as you can observe, rather awful. If you're planning to write cross platform SQL, I would consider having a library of common user defined functions for each DBMS, allowing you to normalise any common requirements like this. This keeps your main codebase a lot cleaner.
Work out the number of days in each month of 2012
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
For each month of the year in 2012, output the number of days in that month. Format the output as an integer column containing the month of the year, and a second column containing an interval data type.
┌───────┬─────────┐
│ month │ length │
├───────┼─────────┤
│ 1 │ 31 days │
│ 2 │ 29 days │
│ 3 │ 31 days │
│ 4 │ 30 days │
│ 5 │ 31 days │
│ 6 │ 30 days │
│ 7 │ 31 days │
│ 8 │ 31 days │
│ 9 │ 30 days │
│ 10 │ 31 days │
│ 11 │ 30 days │
│ 12 │ 31 days │
└───────┴─────────┘
(12 rows)
Subtracting two timestamps will give you the interval you're looking for. You can use the EXTRACT function to get the month from a timestamp.
SELECT
EXTRACT(MONTH FROM days) AS month, COUNT(days)::TEXT || ' days' AS length
FROM
GENERATE_SERIES('2012-01-01'::TIMESTAMP, '2012-12-31', '1 day') days
GROUP BY
month
ORDER BY
month;
SELECT
EXTRACT(
MONTH
FROM
cal.month
) AS month,
(cal.month + interval '1 month') - cal.month AS length
FROM
(
SELECT
GENERATE_SERIES(
TIMESTAMP '2012-01-01',
TIMESTAMP '2012-12-01',
interval '1 month'
) AS month
) cal
ORDER BY
month;
This answer shows several of the concepts we've learned. We use the GENERATE_SERIES function to produce a year's worth of timestamps, incrementing a month at a time. We then use the EXTRACT function to get the month number. Finally, we subtract each timestamp + 1 month from itself.
It's worth noting that subtracting two timestamps will always produce an interval in terms of days (or portions of a day). You won't just get an answer in terms of months or years, because the length of those time periods is variable.
Work out the number of days remaining in the month
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
For any given timestamp, work out the number of days remaining in the month. The current day should count as a whole day, regardless of the time. Use '2012-02-11 01:00:00' as an example timestamp for the purposes of making the answer. Format the output as a single interval value.
┌───────────┐
│ remaining │
├───────────┤
│ 19 days │
└───────────┘
(1 row)
Take a look at the DATE_TRUNC function.
You can do something like the following without much thrill:
SELECT
EXTRACT(DAY FROM
DATE_TRUNC('month', '2012-02-11 01:00:00'::TIMESTAMP + '1 month')
- DATE_TRUNC('day', '2012-02-11 01:00:00'::TIMESTAMP)
) || ' days' AS remaining;
Most solutions will involve, in one form or another, adding a month to the provided timestamp and then finding the number of days between the truncated addition just mentioned (to a month's specificity, thus always resulting in midnight at the beginning of the month following the provided timestamp) and the truncated timestamp provided (to a day's specificity, thus always resulting in being midnight of the day of whatever timestamp was provided). Ultimately, we would like to make the solution above more extensible; that is, it would be nice to apply the thought process or mental model to any provided timestamp. This immediately suggests the creation of a function of some sort.
The way you create a function in PostgreSQL is what you might expect: CREATE FUNCTION. The syntax may not be the most obvious thing in the world and you need to specify the procedural language of the function, most often plpgsql. We can create a function get_remaining_days to solve the presemt problem:
CREATE FUNCTION get_remaining_days(date_and_time TIMESTAMP)
RETURNS TEXT
LANGUAGE plpgsql
AS
$$
DECLARE num_remaining_days INTEGER;
DECLARE formatted_remaining_days TEXT;
BEGIN
SELECT
EXTRACT(DAY FROM
DATE_TRUNC('month', date_and_time + '1 month')
- DATE_TRUNC('day', date_and_time)
) INTO num_remaining_days;
formatted_remaining_days:= CAST(num_remaining_days AS TEXT) || ' days';
RETURN formatted_remaining_days;
END $$;
Subsequently executing SELECT get_remaining_days('2021-03-4 01:00:00') remaining; yields the desired result set:
┌───────────┐
│ remaining │
├───────────┤
│ 28 days │
└───────────┘
(1 row)
SELECT (DATE_TRUNC('month',ts.testts) + interval '1 month')
- DATE_TRUNC('day', ts.testts) AS remaining
FROM (SELECT TIMESTAMP '2012-02-11 01:00:00' AS testts) ts;
The star of this particular show is the DATE_TRUNC function. It does pretty much what you'd expect - truncates a date to a given minute, hour, day, month, and so on. The way we've solved this problem is to truncate our timestamp to find the month we're in, add a month to that, and subtract our timestamp. To ensure partial days get treated as whole days, the timestamp we subtract is truncated to the nearest day.
Note the way we've put the timestamp into a subquery. This isn't required, but it does mean you can give the timestamp a name, rather than having to list the literal repeatedly.
Work out the end time of bookings
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Return a list of the start and end time of the last 10 bookings (ordered by the time at which they end, followed by the time at which they start) in the system.
┌─────────────────────┬─────────────────────┐
│ starttime │ endtime │
├─────────────────────┼─────────────────────┤
│ 2013-01-01 15:30:00 │ 2013-01-01 16:00:00 │
│ 2012-09-30 19:30:00 │ 2012-09-30 20:30:00 │
│ 2012-09-30 19:00:00 │ 2012-09-30 20:30:00 │
│ 2012-09-30 19:30:00 │ 2012-09-30 20:00:00 │
│ 2012-09-30 19:00:00 │ 2012-09-30 20:00:00 │
│ 2012-09-30 19:00:00 │ 2012-09-30 20:00:00 │
│ 2012-09-30 18:30:00 │ 2012-09-30 20:00:00 │
│ 2012-09-30 18:30:00 │ 2012-09-30 20:00:00 │
│ 2012-09-30 19:00:00 │ 2012-09-30 19:30:00 │
│ 2012-09-30 18:30:00 │ 2012-09-30 19:30:00 │
└─────────────────────┴─────────────────────┘
(10 rows)
You can multiply an interval by the number of slots in a booking.
SELECT
B.starttime, B.starttime + B.slots * '30 minutes'::interval AS endtime
FROM
cd.bookings B
ORDER BY
endtime DESC, starttime DESC
LIMIT 10;
SELECT
starttime,
starttime + slots *(interval '30 minutes') endtime
FROM
cd.bookings
ORDER BY
endtime DESC,
starttime DESC
LIMIT
10;
This question simply returns the start time for a booking, and a calculated end time which is equal to start time + (30 minutes * slots). Note that it's perfectly okay to multiply intervals.
The other thing you'll notice is the use of order by and limit to get the last ten bookings. All this does is order the bookings by the (descending) time at which they end, and pick off the top ten.
Return a count of bookings for each month
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Return a count of bookings for each month, sorted by month.
┌─────────────────────┬───────┐
│ month │ count │
├─────────────────────┼───────┤
│ 2012-07-01 00:00:00 │ 658 │
│ 2012-08-01 00:00:00 │ 1472 │
│ 2012-09-01 00:00:00 │ 1913 │
│ 2013-01-01 00:00:00 │ 1 │
└─────────────────────┴───────┘
(4 rows)
You're probably going to want the DATE_TRUNC function again.
SELECT
DATE_TRUNC('month', B.starttime) AS month,
COUNT(B.starttime) AS count
FROM
cd.bookings B
GROUP BY
month
ORDER BY
month ASC;
SELECT
DATE_TRUNC('month', starttime) AS month,
COUNT(*)
FROM
cd.bookings
GROUP BY
month
ORDER BY
month;
This one is a fairly simple reuse of concepts we've seen before. We simply count the number of bookings, and aggregate by the booking's start time, truncated to the month.
Work out the utilisation percentage for each facility by month
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Work out the utilisation percentage for each facility by month, sorted by name and month, rounded to 1 decimal place. Opening time is 8am, closing time is 8.30pm. You can treat every month as a full month, regardless of if there were some dates the club was not open.
┌─────────────────┬─────────────────────┬─────────────┐
│ name │ month │ utilisation │
├─────────────────┼─────────────────────┼─────────────┤
│ Badminton Court │ 2012-07-01 00:00:00 │ 23.2 │
│ Badminton Court │ 2012-08-01 00:00:00 │ 59.2 │
│ Badminton Court │ 2012-09-01 00:00:00 │ 76.0 │
│ Massage Room 1 │ 2012-07-01 00:00:00 │ 34.1 │
│ Massage Room 1 │ 2012-08-01 00:00:00 │ 63.5 │
│ Massage Room 1 │ 2012-09-01 00:00:00 │ 86.4 │
│ Massage Room 2 │ 2012-07-01 00:00:00 │ 3.1 │
│ Massage Room 2 │ 2012-08-01 00:00:00 │ 10.6 │
│ Massage Room 2 │ 2012-09-01 00:00:00 │ 16.3 │
│ Pool Table │ 2012-07-01 00:00:00 │ 15.1 │
│ Pool Table │ 2012-08-01 00:00:00 │ 41.5 │
│ Pool Table │ 2012-09-01 00:00:00 │ 62.8 │
│ Pool Table │ 2013-01-01 00:00:00 │ 0.1 │
│ Snooker Table │ 2012-07-01 00:00:00 │ 20.1 │
│ Snooker Table │ 2012-08-01 00:00:00 │ 42.1 │
│ Snooker Table │ 2012-09-01 00:00:00 │ 56.8 │
│ Squash Court │ 2012-07-01 00:00:00 │ 21.2 │
│ Squash Court │ 2012-08-01 00:00:00 │ 51.6 │
│ Squash Court │ 2012-09-01 00:00:00 │ 72.0 │
│ Table Tennis │ 2012-07-01 00:00:00 │ 13.4 │
│ Table Tennis │ 2012-08-01 00:00:00 │ 39.2 │
│ Table Tennis │ 2012-09-01 00:00:00 │ 56.3 │
│ Tennis Court 1 │ 2012-07-01 00:00:00 │ 34.8 │
│ Tennis Court 1 │ 2012-08-01 00:00:00 │ 59.2 │
│ Tennis Court 1 │ 2012-09-01 00:00:00 │ 78.8 │
│ Tennis Court 2 │ 2012-07-01 00:00:00 │ 26.7 │
│ Tennis Court 2 │ 2012-08-01 00:00:00 │ 62.3 │
│ Tennis Court 2 │ 2012-09-01 00:00:00 │ 78.4 │
└─────────────────┴─────────────────────┴─────────────┘
(28 rows)
Remember different months have different lengths - you'll need to calculate the number of available slots in each month. You need to find a way to retrieve an integer (rather than interval) number of days for the length of the month.
Here is one possible approach:
SELECT
name, slotsUsed.month AS month, ROUND((100 * slots_used / (25.0 * days))::numeric, 1) AS utilisation
FROM
(
SELECT
F.name,
DATE_TRUNC('month', B.starttime) AS month,
SUM(B.slots) AS slots_used
FROM
cd.bookings B
INNER JOIN cd.facilities F ON B.facid = F.facid
GROUP BY
F.name, month
ORDER BY
F.name
) slotsUsed
INNER JOIN
(
SELECT
month, EXTRACT(DAY FROM month + '1 month' - month) AS days
FROM
GENERATE_SERIES(
DATE_TRUNC('month', (SELECT MIN(starttime) FROM cd.bookings)),
DATE_TRUNC('month', (SELECT MAX(starttime) FROM cd.bookings)),
'1 month'
) month
) daysPerMonth ON slotsUsed.month = daysPerMonth.month
ORDER BY
name, month;
SELECT name, month,
ROUND((100*slots)/
CAST(
25*(CAST((month + interval '1 month') AS date)
- CAST(month AS date)) AS numeric),1) AS utilisation
FROM (
SELECT facs.name AS name, DATE_TRUNC('month', starttime) AS month, SUM(slots) AS slots
FROM cd.bookings bks
INNER JOIN cd.facilities facs
ON bks.facid = facs.facid
GROUP BY facs.facid, month
) AS inn
ORDER BY name, month;
The meat of this query (the inner subquery) is really quite simple: an aggregation to work out the total number of slots used per facility per month. If you've covered the rest of this section and the category on aggregates, you likely didn't find this bit too challenging.
This query does, unfortunately, have some other complexity in it: working out the number of days in each month. We can calculate the number of days between two months by subtracting two timestamps with a month between them. This, unfortunately, gives us back on interval datatype, which we can't use to do mathematics. In this case we've worked around that limitation by converting our timestamps into dates before subtracting. Subtracting date types gives us an integer number of days.
A alternative to this workaround is to convert the interval into an epoch value: that is, a number of seconds. To do this use EXTRACT(EPOCH FROM month)/(24*60*60). This is arguably a much nicer way to do things, but is much less portable to other database systems.
String
Intro
String operations in most RDBMSs are, arguably, needlessly painful. Fortunately, Postgres is better than most in this regard, providing strong regular expression support. This section covers basic string manipulation, use of the LIKE operator, and use of regular expressions. I also make an effort to show you some alternative approaches that work reliably in most RDBMSs. Be sure to check out Postgres' string function docs page if you're not confident about these exercises.
Anthony Molinaro's SQL Cookbook provides some excellent documentation of (difficult) cross-DBMS compliant SQL string manipulation. I'd strongly recommend his book.
Format the names of members
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Output the names of all members, formatted as 'Surname, Firstname'
┌──────────────────────────┐
│ name │
├──────────────────────────┤
│ GUEST, GUEST │
│ Smith, Darren │
│ Smith, Tracy │
│ Rownam, Tim │
│ Joplette, Janice │
│ Butters, Gerald │
│ Tracy, Burton │
│ Dare, Nancy │
│ Boothe, Tim │
│ Stibbons, Ponder │
│ Owen, Charles │
│ Jones, David │
│ Baker, Anne │
│ Farrell, Jemima │
│ Smith, Jack │
│ Bader, Florence │
│ Baker, Timothy │
│ Pinker, David │
│ Genting, Matthew │
│ Mackenzie, Anna │
│ Coplin, Joan │
│ Sarwin, Ramnaresh │
│ Jones, Douglas │
│ Rumney, Henrietta │
│ Farrell, David │
│ Worthington-Smyth, Henry │
│ Purview, Millicent │
│ Tupperware, Hyacinth │
│ Hunt, John │
│ Crumpet, Erica │
│ Smith, Darren │
└──────────────────────────┘
(31 rows)
Use the || operator to concatenate strings.
The cleanest PostgreSQL way is probably
SELECT
CONCAT_WS(', ', surname, firstname) AS name
FROM
cd.members;
SELECT
surname || ', ' || firstname AS name
FROM
cd.members;
Building strings in SQL is similar to other languages, with the exception of the concatenation operator: ||. Some systems (like SQL Server) use +, but || is the SQL standard.
Find facilities by a name prefix
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Find all facilities whose name begins with 'Tennis'. Retrieve all columns.
┌───────┬────────────────┬────────────┬───────────┬───────────────┬────────────────────┐
│ facid │ name │ membercost │ guestcost │ initialoutlay │ monthlymaintenance │
├───────┼────────────────┼────────────┼───────────┼───────────────┼────────────────────┤
│ 0 │ Tennis Court 1 │ 5 │ 25 │ 10000 │ 200 │
│ 1 │ Tennis Court 2 │ 5 │ 25 │ 8000 │ 200 │
└───────┴────────────────┴────────────┴───────────┴───────────────┴────────────────────┘
(2 rows)
Use the LIKE operator.
SELECT
*
FROM
cd.facilities F
WHERE
F.name LIKE 'Tennis%';
SELECT
*
FROM
cd.facilities
WHERE
name LIKE 'Tennis%';
The SQL LIKE operator is a highly standard way of searching for a string using basic matching. The % character matches any string, while _ matches any single character.
One point that's worth considering when you use LIKE is how it uses indexes. If you're using the 'C' locale, any LIKE string with a fixed beginning (as in our example here) can use an index. If you're using any other locale, LIKE will not use any index by default. See here for details on how to change that.
Perform a case-insensitive search
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Perform a case-insensitive search to find all facilities whose name begins with 'tennis'. Retrieve all columns.
┌───────┬────────────────┬────────────┬───────────┬───────────────┬────────────────────┐
│ facid │ name │ membercost │ guestcost │ initialoutlay │ monthlymaintenance │
├───────┼────────────────┼────────────┼───────────┼───────────────┼────────────────────┤
│ 0 │ Tennis Court 1 │ 5 │ 25 │ 10000 │ 200 │
│ 1 │ Tennis Court 2 │ 5 │ 25 │ 8000 │ 200 │
└───────┴────────────────┴────────────┴───────────┴───────────────┴────────────────────┘
(2 rows)
Use the UPPER function or the ILIKE operator.
The most straightforward answer seems to be to take advantage of PostgreSQL's ILIKE operator:
SELECT
*
FROM
cd.facilities F
WHERE
F.name ILIKE 'Tennis%';
Alternatively, you can use a common approach in SQL and instead apply a function over a column:
SELECT
*
FROM
cd.facilities F
WHERE
LOWER(F.name) LIKE 'tennis%';
SELECT
*
FROM
cd.facilities
WHERE
UPPER(name) LIKE 'TENNIS%';
There's no direct operator for case-insensitive comparison in standard SQL. Fortunately, we can take a page from many other language's books, and simply force all values into upper case when we do our comparison. This renders case irrelevant, and gives us our result.
Alternatively, Postgres does provide the ILIKE operator, which performs case insensitive searches. This isn't standard SQL, but it's arguably more clear.
You should realise that running a function like UPPER over a column value prevents Postgres from making use of any indexes on the column (the same is true for ILIKE). Fortunately, Postgres has got your back: rather than simply creating indexes over columns, you can also create indexes over expressions. If you created an index over UPPER(name), this query could use it quite happily.
Find telephone numbers with parentheses
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
You've noticed that the club's member table has telephone numbers with very inconsistent formatting. You'd like to find all the telephone numbers that contain parentheses, returning the member ID and telephone number sorted by member ID.
┌───────┬────────────────┐
│ memid │ telephone │
├───────┼────────────────┤
│ 0 │ (000) 000-0000 │
│ 3 │ (844) 693-0723 │
│ 4 │ (833) 942-4710 │
│ 5 │ (844) 078-4130 │
│ 6 │ (822) 354-9973 │
│ 7 │ (833) 776-4001 │
│ 8 │ (811) 433-2547 │
│ 9 │ (833) 160-3900 │
│ 10 │ (855) 542-5251 │
│ 11 │ (844) 536-8036 │
│ 13 │ (855) 016-0163 │
│ 14 │ (822) 163-3254 │
│ 15 │ (833) 499-3527 │
│ 20 │ (811) 972-1377 │
│ 21 │ (822) 661-2898 │
│ 22 │ (822) 499-2232 │
│ 24 │ (822) 413-1470 │
│ 27 │ (822) 989-8876 │
│ 28 │ (855) 755-9876 │
│ 29 │ (855) 894-3758 │
│ 30 │ (855) 941-9786 │
│ 33 │ (822) 665-5327 │
│ 35 │ (899) 720-6978 │
│ 36 │ (811) 732-4816 │
│ 37 │ (822) 577-3541 │
└───────┴────────────────┘
(25 rows)
Look up the ~ or SIMILAR TO operators in the Postgres docs.
As noted in the docs on pattern matching, PostgreSQL supports the LIKE (and ILIKE) operator, SIMILAR TO regular expressions, and POSIX regular expressions. The POSIX regular expressions are what most people are familiar dealing with, and Postgres implements POSIX regulat expression matching via the ~ operator.
SELECT
M.memid, M.telephone
FROM
cd.members M
WHERE
M.telephone ~ '[()]'
ORDER BY
M.memid;
SELECT
memid,
telephone
FROM
cd.members
WHERE
telephone ~ '[()]';
We've chosen to answer this using regular expressions, although Postgres does provide other string functions like POSITION that would do the job at least as well. Postgres implements POSIX regular expression matching via the ~ operator. If you've used regular expressions before, the functionality of the operator will be very familiar to you.
As an alternative, you can use the SQL standard SIMILAR TO operator. The regular expressions for this have similarities to the POSIX standard, but a lot of differences as well. Some of the most notable differences are:
- As in the
LIKEoperator,SIMILAR TOuses the'_'character to mean 'any character', and the'%'character to mean 'any string'. - A
SIMILAR TOexpression must match the whole string, not just a substring as in posix regular expressions. This means that you'll typically end up bracketing an expression in'%'characters. - The
'.'character does not mean 'any character' inSIMILAR TOregexes: it's just a plain character.
The SIMILAR TO equivalent of the given answer is shown below:
SELECT
memid,
telephone
FROM
cd.members
WHERE
telephone SIMILAR TO '%[()]%';
Finally, it's worth noting that regular expressions usually don't use indexes. Generally you don't want your regex to be responsible for doing heavy lifting in your query, because it will be slow. If you need fuzzy matching that works fast, consider working out if your needs can be met by full text search.
Pad zip codes with leading zeroes
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
The zip codes in our example dataset have had leading zeroes removed from them by virtue of being stored as a numeric type. Retrieve all zip codes from the members table, padding any zip codes less than 5 characters long with leading zeroes. Order by the new zip code.
┌───────┐
│ zip │
├───────┤
│ 00000 │
│ 00234 │
│ 00234 │
│ 04321 │
│ 04321 │
│ 10383 │
│ 11986 │
│ 23423 │
│ 28563 │
│ 33862 │
│ 34232 │
│ 43532 │
│ 43533 │
│ 45678 │
│ 52365 │
│ 54333 │
│ 56754 │
│ 57392 │
│ 58393 │
│ 64577 │
│ 65332 │
│ 65464 │
│ 66796 │
│ 68666 │
│ 69302 │
│ 75655 │
│ 78533 │
│ 80743 │
│ 84923 │
│ 87630 │
│ 97676 │
└───────┘
(31 rows)
Check out the LPAD function. You'll also need to cast the zipcode column to a character string.
SELECT
LPAD(M.zipcode::TEXT, 5, '0') AS zip
FROM
cd.members M
ORDER BY
zip;
SELECT
LPAD(CAST(zipcode AS char(5)), 5, '0') zip
FROM
cd.members
ORDER BY
zip;
Postgres' LPAD function is the star of this particular show. It does basically what you'd expect: allow us to produce a padded string. We need to remember to cast the zipcode to a string for it to be accepted by the LPAD function.
When inheriting an old database, It's not that unusual to find wonky decisions having been made over data types. You may wish to fix mistakes like these, but have a lot of code that would break if you changed datatypes. In that case, one option (depending on performance requirements) is to create a view over your table which presents the data in a fixed-up manner, and gradually migrate.
Count the number of members whose surname starts with each letter of the alphabet
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
You'd like to produce a count of how many members you have whose surname starts with each letter of the alphabet. Sort by the letter, and don't worry about printing out a letter if the count is 0.
┌────────┬───────┐
│ letter │ count │
├────────┼───────┤
│ B │ 5 │
│ C │ 2 │
│ D │ 1 │
│ F │ 2 │
│ G │ 2 │
│ H │ 1 │
│ J │ 3 │
│ M │ 1 │
│ O │ 1 │
│ P │ 2 │
│ R │ 2 │
│ S │ 6 │
│ T │ 2 │
│ W │ 1 │
└────────┴───────┘
(14 rows)
You'll need the SUBSTRING function here, combined with some aggregation.
SELECT
SUBSTRING(M.surname,1,1) AS letter,
COUNT(*) AS count
FROM
cd.members M
GROUP BY
letter
ORDER BY
letter;
SELECT
substr (mems.surname, 1, 1) AS letter,
COUNT(*) AS count
FROM
cd.members mems
GROUP BY
letter
ORDER BY
letter;
This exercise is fairly straightforward. You simply need to retrieve the first letter of the member's surname, and do some basic aggregation to achieve a count. We use the SUBSTR function here, but there's a variety of other ways you can achieve the same thing. The LEFT function, for example, returns you the first n characters from the left of the string. Alternatively, you could use the SUBSTRING function, which allows you to use regular expressions to extract a portion of the string.
One point worth noting: as you can see, string functions in SQL are based on 1-indexing, not the 0-indexing that you're probably used to. This will likely trip you up once or twice before you get used to it.
Clean up telephone numbers
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
The telephone numbers in the database are very inconsistently formatted. You'd like to print a list of member ids and numbers that have had '-', '(',')', and ' ' characters removed. Order by member id.
┌───────┬────────────┐
│ memid │ telephone │
├───────┼────────────┤
│ 0 │ 0000000000 │
│ 1 │ 5555555555 │
│ 2 │ 5555555555 │
│ 3 │ 8446930723 │
│ 4 │ 8339424710 │
│ 5 │ 8440784130 │
│ 6 │ 8223549973 │
│ 7 │ 8337764001 │
│ 8 │ 8114332547 │
│ 9 │ 8331603900 │
│ 10 │ 8555425251 │
│ 11 │ 8445368036 │
│ 12 │ 8440765141 │
│ 13 │ 8550160163 │
│ 14 │ 8221633254 │
│ 15 │ 8334993527 │
│ 16 │ 8339410824 │
│ 17 │ 8114096734 │
│ 20 │ 8119721377 │
│ 21 │ 8226612898 │
│ 22 │ 8224992232 │
│ 24 │ 8224131470 │
│ 26 │ 8445368036 │
│ 27 │ 8229898876 │
│ 28 │ 8557559876 │
│ 29 │ 8558943758 │
│ 30 │ 8559419786 │
│ 33 │ 8226655327 │
│ 35 │ 8997206978 │
│ 36 │ 8117324816 │
│ 37 │ 8225773541 │
└───────┴────────────┘
(31 rows)
Consider the TRANSLATE or REGEXP_REPLACE functions.
SELECT
M.memid,
REGEXP_REPLACE(M.telephone, '\D', '', 'g') telephone
FROM
cd.members M
ORDER BY
M.memid ASC;
Some things to note about the arguments to REGEXP_REPLACE in the answer above:
M.telephone: The field to apply theREGEXP_REPLACEfunction to.'\D': This will match any character that's not a digit (equivalent to[^0-9]).'': This is what we will replace the match(es) with.g: This is the "global" flag, indicating that we want to replace all non-digit matches with an empty string.
SELECT
memid,
TRANSLATE(telephone, '-() ', '') AS telephone
FROM
cd.members
ORDER BY
memid;
The most direct solution is probably the TRANSLATE function, which can be used to replace characters in a string. You pass it three strings: the value you want altered, the characters to replace, and the characters you want them replaced with. In our case, we want all the characters deleted, so our third parameter is an empty string.
As is often the way with strings, we can also use regular expressions to solve our problem. The REGEXP_REPLACE function provides what we're looking for: we simply pass a regex that matches all non-digit characters, and replace them with nothing, as shown below. The 'g' flag tells the function to replace as many instances of the pattern as it can find. This solution is perhaps more robust, as it cleans out more bad formatting.
SELECT
memid,
REGEXP_REPLACE(telephone, '[^0-9]', '', 'g') AS telephone
FROM
cd.members
ORDER BY
memid;
Making automated use of free-formatted text data can be a chore. Ideally you want to avoid having to constantly write code to clean up the data before using it, so you should consider having your database enforce correct formatting for you. You can do this using a CHECK constraint on your column, which allow you to reject any poorly-formatted entry. It's tempting to perform this kind of validation in the application layer, and this is certainly a valid approach. As a general rule, if your database is getting used by multiple applications, favour pushing more of your checks down into the database to ensure consistent behaviour between the apps.
Occasionally, adding a constraint isn't feasible. You may, for example, have two different legacy applications asserting differently formatted information. If you're unable to alter the applications, you have a couple of options to consider. Firstly, you can define a trigger on your table. This allows you to intercept data before (or after) it gets asserted to your table, and normalise it into a single format. Alternatively, you could build a view over your table that cleans up information on the fly, as it's read out. Newer applications can read from the view and benefit from more reliably formatted information.
Recursive
Intro
Common Table Expressions allow us to, effectively, create our own temporary tables for the duration of a query - they're largely a convenience to help us make more readable SQL. Using the WITH RECURSIVE modifier, however, it's possible for us to create recursive queries. This is enormously advantageous for working with tree and graph-structured data - imagine retrieving all of the relations of a graph node to a given depth, for example.
This category shows you some basic recursive queries that are possible using our dataset.
Find the upward recommendation chain for member ID 27
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Find the upward recommendation chain for member ID 27: that is, the member who recommended them, and the member who recommended that member, and so on. Return member ID, first name, and surname. Order by descending member id.
┌─────────────┬───────────┬─────────┐
│ recommender │ firstname │ surname │
├─────────────┼───────────┼─────────┤
│ 20 │ Matthew │ Genting │
│ 5 │ Gerald │ Butters │
│ 1 │ Darren │ Smith │
└─────────────┴───────────┴─────────┘
(3 rows)
Read up on WITH RECURSIVE.
TLDR:
WITH RECURSIVE up_rec_chain AS (
SELECT
recommendedby AS recommender
FROM
cd.members M
WHERE
M.memid = 27
UNION ALL
SELECT
M.recommendedby AS recommender
FROM
up_rec_chain U
INNER JOIN cd.members M ON U.recommender = M.memid
WHERE
M.recommendedby IS NOT NULL
)
SELECT
recommender, M.firstname, M.surname
FROM
up_rec_chain U
INNER JOIN cd.members M ON U.recommender = M.memid
ORDER BY
recommender DESC;
Simple start: Members and those who recommended them (if any):
This is not the simplest WITH RECURSIVE problem with which to start. It may be easiest to start with a query that will give us all the members and who they were recommended by (if anyone):
SELECT
recommendees.memid AS memID,
recommendees.firstname AS memFirst,
recommendees.surname AS memLast,
recommendees.recommendedby AS recBy,
recommenders.memid AS recID,
recommenders.firstname AS recFirst,
recommenders.surname AS recLast
FROM
cd.members recommendees
LEFT JOIN cd.members recommenders ON recommendees.recommendedby = recommenders.memid;
The query above yields the following table:
┌───────┬───────────┬───────────────────┬───────┬───────┬───────────┬──────────┐
│ memid │ memfirst │ memlast │ recby │ recid │ recfirst │ reclast │
├───────┼───────────┼───────────────────┼───────┼───────┼───────────┼──────────┤
│ 0 │ GUEST │ GUEST │ │ │ │ │
│ 1 │ Darren │ Smith │ │ │ │ │
│ 2 │ Tracy │ Smith │ │ │ │ │
│ 3 │ Tim │ Rownam │ │ │ │ │
│ 4 │ Janice │ Joplette │ 1 │ 1 │ Darren │ Smith │
│ 5 │ Gerald │ Butters │ 1 │ 1 │ Darren │ Smith │
│ 6 │ Burton │ Tracy │ │ │ │ │
│ 7 │ Nancy │ Dare │ 4 │ 4 │ Janice │ Joplette │
│ 8 │ Tim │ Boothe │ 3 │ 3 │ Tim │ Rownam │
│ 9 │ Ponder │ Stibbons │ 6 │ 6 │ Burton │ Tracy │
│ 10 │ Charles │ Owen │ 1 │ 1 │ Darren │ Smith │
│ 11 │ David │ Jones │ 4 │ 4 │ Janice │ Joplette │
│ 12 │ Anne │ Baker │ 9 │ 9 │ Ponder │ Stibbons │
│ 13 │ Jemima │ Farrell │ │ │ │ │
│ 14 │ Jack │ Smith │ 1 │ 1 │ Darren │ Smith │
│ 15 │ Florence │ Bader │ 9 │ 9 │ Ponder │ Stibbons │
│ 16 │ Timothy │ Baker │ 13 │ 13 │ Jemima │ Farrell │
│ 17 │ David │ Pinker │ 13 │ 13 │ Jemima │ Farrell │
│ 20 │ Matthew │ Genting │ 5 │ 5 │ Gerald │ Butters │
│ 21 │ Anna │ Mackenzie │ 1 │ 1 │ Darren │ Smith │
│ 22 │ Joan │ Coplin │ 16 │ 16 │ Timothy │ Baker │
│ 24 │ Ramnaresh │ Sarwin │ 15 │ 15 │ Florence │ Bader │
│ 26 │ Douglas │ Jones │ 11 │ 11 │ David │ Jones │
│ 27 │ Henrietta │ Rumney │ 20 │ 20 │ Matthew │ Genting │
│ 28 │ David │ Farrell │ │ │ │ │
│ 29 │ Henry │ Worthington-Smyth │ 2 │ 2 │ Tracy │ Smith │
│ 30 │ Millicent │ Purview │ 2 │ 2 │ Tracy │ Smith │
│ 33 │ Hyacinth │ Tupperware │ │ │ │ │
│ 35 │ John │ Hunt │ 30 │ 30 │ Millicent │ Purview │
│ 36 │ Erica │ Crumpet │ 2 │ 2 │ Tracy │ Smith │
│ 37 │ Darren │ Smith │ │ │ │ │
└───────┴───────────┴───────────────────┴───────┴───────┴───────────┴──────────┘
(31 rows)
As we can see from the query results above, the "upward recommendation chain" for the member with ID 27 (i.e., Henrietta Rumney) looks as follows in terms of member IDs:
27 <-- 20 <-- 5 <-- 1 <-- NULL
And in terms of member names:
Henrietta Rumney <-- Matthew Genting
<-- Gerald Butters
<-- Darren Smith
<-- NULL
We can piece this together perfectly well by looking at the query result table above, but of course the goal is to generate such a recommendation chain not by looking at the table but by architecting a query. We can start this architecting process by examining the manual process we would come up with in a visual search:
Identify the recommendedby value for the member with memid of 27. That value is 20. We then look for the recommendedby value for the member with memid of 20. That value is 5. And we would continue this process until we reach a member who was not recommended by anyone (i.e., a member whose recommendedby field had a NULL value). So how do we do this in terms of writing SQL? It's clear we need some sort of iterative or recursive approach. A simple INNER JOIN will not be sufficient here.
WITH RECURSIVE: A look at the official documentation:
Reading what the official documentation has to say about WITH Queries is a good investment of time, especially the portion about recursive query evaluation (as Postgres points out, the WITH RECURSIVE process is iteration not recursion, but RECURSIVE is the terminology chosen by the SQL standards committee.):
The general form of a recursive
WITHquery is always a non-recursive term, thenUNION(orUNION ALL), then a recursive term, where only the recursive term can contain a reference to the query's own output. Such a query is executed as follows:
- Evaluate the non-recursive term. For
UNION(but notUNION ALL), discard duplicate rows. Include all remaining rows in the result of the recursive query, and also place them in a temporary working table.- So long as the working table is not empty, repeat these steps:
- Evaluate the recursive term, substituting the current contents of the working table for the recursive self-reference. For
UNION(but notUNION ALL), discard duplicate rows and rows that duplicate any previous result row. Include all remaining rows in the result of the recursive query, and also place them in a temporary intermediate table.- Replace the contents of the working table with the contents of the intermediate table, then empty the intermediate table.
In more simple syntactical terms, here's what the process outlined above looks like:
WITH RECURSIVE cte_name AS(
CTE_auxiliary_query_1 -- non-recursive term
UNION [ALL]
CTE_auxiliary_query_2 -- recursive term
) CTE_primary_query;
Let's walk through each part of this syntax:
WITH RECURSIVE cte_name AS (...): TheRECURSIVEkeyword inWITH RECURSIVEtells our database that the CTE we are building is not like the normal CTE(s) that can be built using only theWITHkeyword--our CTE will be built in an iterative fashion instead.cte_nameis the label or name we are assigning to the CTE built in the iterative process (this name is typically used or referred to inCTE_auxiliary_query_2andCTE_primary_query). TheASkeyword simply denotes howcte_nameis to be built throughout the iterative process (i.e., the...part inside the parentheses).CTE_auxiliary_query_1: Evaluate the non-recursive term. WhenUNIONis used, duplicate rows will be discarded; whenUNION ALLis used, duplicate rows will be kept. Include all remaining rows in the result of the recursive query (i.e.,cte_namebeing the result of the recursive query), and also place them in a temporary working table. This working table is what will be used or referred to inCTE_auxiliary_query_2(i.e., the so-called "recursive term") to really kick off the iterative process.CTE_auxiliary_query_2: Evaluate the recursive term, substituting the current contents of the working table for the recursive self-reference; that is, the recursive self-reference will always becte_name, but the working table depends on where we are in the iterative process.- Beginning: At the beginning of the iterative process, the result set of
CTE_auxiliary_query_1, if any, constitutes the working table and we can refer to this working table ascte_nameinCTE_auxiliary_query_2. Note that the final result of the recursive query, which we ultimately refer to ascte_nameinCTE_primary_queryonce the iterative process has finished, is different from thecte_namereferred to inCTE_auxiliary_query_2during each iteration. (This will become clearer momentarily by means of some examples.) - Not beginning: For every iteration, except at the beginning, the
cte_namereferred to inCTE_auxiliary_query_2refers to the output of the priorCTE_auxiliary_query_2query; that is, for every iteration except the first, the temporary working table is the query output ofCTE_auxiliary_query_2for the previous iteration. Once the recursive termCTE_auxiliary_query_2finishes executing, the following rough sequence of operations takes place:- If the recursive term
CTE_auxiliary_query_2has an empty query output, then the query terminates and control is passed toCTE_primary_query. - If the recursive term
CTE_auxiliary_query_2has a non-empty query output, then the following sequence of operations takes place:- The result set from
CTE_auxiliary_query_2is appended to the total result set for theWITH RECURSIVEquery (i.e., thecte_namewe refer to inCTE_primary_queryonce the iterative process has finished). Duplicate rows will be kept when usingUNION ALLbut discarded when using onlyUNION. - The result set from
CTE_auxiliary_query_2is placed in a temporary intermediate table. - The contents of the working table just used by
CTE_auxiliary_query_2are replaced by the contents of the intermediate table referred to above. The intermediate table is then emptied so we can repeat this whole process again (i.e., the "Not beginning" process).
- The result set from
- If the recursive term
- Beginning: At the beginning of the iterative process, the result set of
CTE_primary_query: This is whereWITH RECURSIVEreally pays off, of course. The table we built in an iterative fashion,cte_name, is now available in its entirety for us to query from however we like. This could be a simpleSELECT * FROM cte_nameor it could be a much more complicated query involving joins and/or whatever else we might want to throw in there.
Examples:
Example 1: Generating integers 1 through 10, inclusive, without GENERATE_SERIES function (detailed explanation):
Postgres provides a GENERATE_SERIES function that makes it trivial to generate a table containing the integers 1 through 10, inclusive. But many database systems (e.g., MySQL) do not have such a function. One way we can generate such a sequence of numbers is by means of WITH RECURSIVE:
WITH RECURSIVE nums_consecutive AS (
SELECT 1 AS num
UNION ALL
SELECT num + 1 FROM nums_consecutive WHERE num < 10
) SELECT * FROM nums_consecutive;
This query yields the following:
┌─────┐
│ num │
├─────┤
│ 1 │
│ 2 │
│ 3 │
│ 4 │
│ 5 │
│ 6 │
│ 7 │
│ 8 │
│ 9 │
│ 10 │
└─────┘
(10 rows)
How does this query work exactly? Here's a detailed breakdown like before, but this time we will have actual data to work with instead of just vague concepts:
WITH RECURSIVE cte_name AS (...): We specify viaWITH RECURSIVEthat we will not just be building a CTE but one that we will build iteratively. Note that we refer tonums_consecutiveinCTE_auxiliary_query_2(i.e., the recursive term):SELECT num + 1 FROM nums_consecutive WHERE num < 10And we also refer to
nums_consecutiveinCTE_primary_queryonce the iterative process has finished and the final CTE has been built:SELECT * FROM nums_consecutive;CTE_auxiliary_query_1: This is the non-recursive term and its result set gives us our first working table:SELECT 1 AS numgives us
┌─────┐
│ num │
├─────┤
│ 1 │
└─────┘
(1 row)as our first working table
CTE_auxiliary_query_2: Since the query output from the non-recursive term was non-empty, the iterative process begins and the working table seen above can now be referred to asnums_consecutiveinCTE_auxiliary_query_2:SELECT num + 1 FROM nums_consecutive WHERE num < 10Since
nums_consecutiveabove really refers to the working table┌─────┐
│ num │
├─────┤
│ 1 │
└─────┘
(1 row)it's not hard to see why the result set of
CTE_auxiliary_query_2(i.e.,SELECT num + 1 FROM nums_consecutive WHERE num < 10) for this iteration is simply┌─────┐
│ num │
├─────┤
│ 2 │
└─────┘
(1 row)Pay special attention to the fact that the result set here is not
┌─────┐
│ num │
├─────┤
│ 1 │
│ 2 │
└─────┘
(2 rows)but simply
┌─────┐
│ num │
├─────┤
│ 2 │
└─────┘
(1 row)That is, the total result set being iteratively built right now may be
┌─────┐
│ num │
├─────┤
│ 1 │
│ 2 │
└─────┘
(2 rows)but this is not the current working table. The current working table is
┌─────┐
│ num │
├─────┤
│ 1 │
└─────┘
(1 row)and the temporary intermediate table is
┌─────┐
│ num │
├─────┤
│ 2 │
└─────┘
(1 row)By means of
UNION ALL, the total result set being iteratively built is┌─────┐
│ num │
├─────┤
│ 1 │
│ 2 │
└─────┘
(2 rows)but we have a way to go before the iterative process terminates. As indicated in the descriptions directly before this example began, we now replace the contents of the working table
┌─────┐
│ num │
├─────┤
│ 1 │
└─────┘
(1 row)with the contents of the intermediate table
┌─────┐
│ num │
├─────┤
│ 2 │
└─────┘
(1 row)and then we empty the intermediate table so it can be
┌─────┐
│ num │
├─────┤
└─────┘
(0 rows)for the pending iteration. For the next iteration, with
┌─────┐
│ num │
├─────┤
│ 2 │
└─────┘
(1 row)as the working table, we see that our
CTE_auxiliary_query_2,SELECT num + 1 FROM nums_consecutive WHERE num < 10, will give us┌─────┐
│ num │
├─────┤
│ 3 │
└─────┘
(1 row)as the new temporary intermediate table, which will then replace the working table
┌─────┐
│ num │
├─────┤
│ 2 │
└─────┘
(1 row)and so on and so forth. This process will continue for some time until our working table is
┌─────┐
│ num │
├─────┤
│ 9 │
└─────┘
(1 row)at which point our
CTE_auxiliary_query_2,SELECT num + 1 FROM nums_consecutive WHERE num < 10, will give us┌─────┐
│ num │
├─────┤
│ 10 │
└─────┘
(1 row)as the new temporary intermediate table. This table replaces
┌─────┐
│ num │
├─────┤
│ 9 │
└─────┘
(1 row)as the working table and when our recursive term is executed again, that is, when
SELECT num + 1 FROM nums_consecutive WHERE num < 10runs against the working table┌─────┐
│ num │
├─────┤
│ 10 │
└─────┘
(1 row)we actually come up empty since the
WHERE num < 10condition is not satisfied. Now both the working table and temporary intermediate table are empty and there's nothing left for the recursive term to run a query against; hence, the query terminates and control is passed toCTE_primary_query(i.e.,SELECT * FROM nums_consecutive;in this example).CTE_primary_query: The table we built in an iterative fashion,nums_consecutive, is now available in its entirety for us to run queries against as we please. Since we want everything from this small table in this example, we simply executeSELECT * FROM nums_consecutive;and this gives us the result set of having all the working tablesUNIONedALLtogether:┌─────┐
│ num │
├─────┤
│ 1 │
│ 2 │
│ 3 │
│ 4 │
│ 5 │
│ 6 │
│ 7 │
│ 8 │
│ 9 │
│ 10 │
└─────┘
(10 rows)For this example, note how the working table has just a single row in each step, and it takes on the values from
1through10in successive steps. In the 10th step, there is no output because of theWHEREclause, and so the query terminates.
Example 2: Generating sequential numbers fitting a certain pattern:
Consider the query
WITH RECURSIVE seq_nums AS (
SELECT
5 AS num,
0 AS iteration
UNION ALL
SELECT
(2 * num + num),
iteration + 1
FROM
seq_nums
WHERE
iteration < 5
) SELECT * FROM seq_nums;
with
┌─────┬───────────┐
│ num │ iteration │
├─────┼───────────┤
│ 5 │ 1 │
│ 15 │ 2 │
│ 45 │ 3 │
│ 135 │ 4 │
│ 405 │ 5 │
└─────┴───────────┘
(5 rows)
as its result set. Note how, just as in the previous example, the working table has just a single row in each step, and it takes on the values 5, 15, 45, 135, and 405 in successive steps. Each iteration value simply denotes which application of CTE_auxiliary_query_2 has been used to generate the next row (the first row indicates the initial application of the non-recursive term CTE_auxiliary_query_1 as well as the first application of CTE_auxiliary_query_2 to generate the next row; the final row indicates the 5th application of CTE_auxiliary_query_2 which has an empty query output, thus terminating the query).
Example 3: Finding the sum of a sequence of numbers:
A classic question from the school days: Find the sum of the first 100 consecutive positive integers. But this time use SQL implementing a WITH RECURSIVE solution! We can use the work we did in the first example to generate numbers 1 through 100, inclusive, and then our CTE_primary_query can involve an aggregate function instead of just selecting everything from the CTE we just generated:
┌──────┐
│ sum │
├──────┤
│ 5050 │
└──────┘
(1 row)
Problem solution (approach):
Returning to the problem at hand, how do we apply all the lessons from reading the documentation and grokking the examples? Whatever problem solution we engineer needs to involve the member whose ID is 27. But we don't need their name or their ID as part of the result set--what we need is who recommended them; that is, we need the recommendedby value for the member whose ID is 27. That's easy enough. So far our WITH RECURSIVE construction would look as follows:
WITH RECURSIVE up_rec_chain AS (
SELECT recommendedby AS recommender FROM cd.members M WHERE M.memid = 27
UNION ALL
-- ? (some recursive term)
) SELECT * FROM up_rec_chain;
What should our recursive term be here? Our working table looks like
┌─────────────┐
│ recommender │
├─────────────┤
│ 20 │
└─────────────┘
(1 row)
as a result of our non-recursive query SELECT recommendedby AS recommender FROM cd.members M WHERE M.memid = 27. Where can we go from here? What was the manual process we used to visually come up with an answer to this problem at the beginning? Once we found the recommendedby value for the member with ID 27 (i.e., 20), we then looked at that member's recommendedby value. And we want to keep doing this until we come across a member who was not recommended by anyone (i.e., their recommendedby value is NULL or empty). That's when we want our query to terminate. If we specified each iteration, as we did in Example 2, then we would like something like the following:
┌─────────────┬───────────┐
│ recommender │ iteration │
├─────────────┼───────────┤
│ 20 │ 1 │
│ 5 │ 2 │
│ 1 │ 3 │
└─────────────┴───────────┘
(3 rows)
How can we express all of this logic in SQL, especially in terms of the WITH RECURSIVE parlance? As a starting point, how do we use the working table
┌─────────────┐
│ recommender │
├─────────────┤
│ 20 │
└─────────────┘
(1 row)
to generate the next row? How we started this problem is a great hint (i.e., recommendees and recommenders).
Hint: We want to use a join. But the special difference in this case is that we will not be joining the cd.members table with itself like we did on recommendees.recommendedby = recommenders.memid; instead, we will treat each working table in the process of iteratively building our up_rec_chain CTE as the recommendees table with the important difference that each working table will only consist of 1 column and 1 row (instead of all member information): there will be a single recommender value that represents the ID of the recommending person (this is the recommendedby value for each record in the cd.members table). We will still use the entire cd.members table as the recommenders table. With an iteratively changing working table up_rec_chain U being INNER JOINed with a static cd.members M table ON U.recommender = M.memid, we will get all the information we need for the next recommender as a result of this join (i.e., M.recommendedby will become the new recommender value for the next working table and so on). All of this will be much easier to understand by means of a concrete walkthrough which you can find in the full solution below.
Problem solution (full solution): The partial WITH RECURSIVE query we had initially was
WITH RECURSIVE up_rec_chain AS (
SELECT recommendedby AS recommender FROM cd.members M WHERE M.memid = 27
UNION ALL
-- ? (some recursive term)
) SELECT * FROM up_rec_chain;
Given the hint above, consider the following query:
WITH RECURSIVE up_rec_chain AS (
SELECT recommendedby AS recommender FROM cd.members M WHERE M.memid = 27
UNION ALL
SELECT M.recommendedby AS recommender FROM up_rec_chain U INNER JOIN cd.members M ON U.recommender = M.memid
) SELECT * FROM up_rec_chain;
The above query yields
┌─────────────┐
│ recommender │
├─────────────┤
│ 20 │
│ 5 │
│ 1 │
│ │
└─────────────┘
(4 rows)
as its result set where the last row is a NULL value. With
┌─────────────┐
│ recommender │
├─────────────┤
│ 20 │
└─────────────┘
(1 row)
as the initial working table coming from the non-recursive term, the first temporary intermediate table coming from the recursive term
SELECT recommendedby AS recommender FROM up_rec_chain U INNER JOIN cd.members M ON U.recommender = M.memid
will be
┌─────────────┐
│ recommender │
├─────────────┤
│ 5 │
└─────────────┘
(1 row)
It may be helpful to see exactly how this temporary intermediate table is generated. If we mimic the recursive term for the initial iteration with the query
SELECT
*
FROM
(SELECT 20 AS recommender) U INNER JOIN cd.members M ON U.recommender = M.memid;
and select everything instead of just recommendedby, then the result set (i.e., temporary intermediate table) we get is
┌─────────────┬───────┬─────────┬───────────┬───────────────────────────────────────┬─────────┬────────────────┬───────────────┬─────────────────────┐
│ recommender │ memid │ surname │ firstname │ address │ zipcode │ telephone │ recommendedby │ joindate │
├─────────────┼───────┼─────────┼───────────┼───────────────────────────────────────┼─────────┼────────────────┼───────────────┼─────────────────────┤
│ 20 │ 20 │ Genting │ Matthew │ 4 Nunnington Place, Wingfield, Boston │ 52365 │ (811) 972-1377 │ 5 │ 2012-08-19 14:55:55 │
└─────────────┴───────┴─────────┴───────────┴───────────────────────────────────────┴─────────┴────────────────┴───────────────┴─────────────────────┘
(1 row)
Note how the first column has the value of the current working table (which is just the ID of the recommending person), and everything else is the member information for that recommending person, including who recommended them (i.e., recommendedby). In the context of this problem, all we are interested in is the chain of recommenders--so we will only select the recommendedby value from this temporary intermediate table:
┌─────────────┐
│ recommender │
├─────────────┤
│ 5 │
└─────────────┘
(1 row)
Per the Postgres spec for WITH RECURSIVE, we will now replace the contents of the working table with the contents of the intermediate table and then empty the intermediate table. With
┌─────────────┐
│ recommender │
├─────────────┤
│ 5 │
└─────────────┘
(1 row)
as our new working table, our recursive term will give us
┌─────────────┬───────┬─────────┬───────────┬────────────────────────────────┬─────────┬────────────────┬───────────────┬─────────────────────┐
│ recommender │ memid │ surname │ firstname │ address │ zipcode │ telephone │ recommendedby │ joindate │
├─────────────┼───────┼─────────┼───────────┼────────────────────────────────┼─────────┼────────────────┼───────────────┼─────────────────────┤
│ 5 │ 5 │ Butters │ Gerald │ 1065 Huntingdon Avenue, Boston │ 56754 │ (844) 078-4130 │ 1 │ 2012-07-09 10:44:09 │
└─────────────┴───────┴─────────┴───────────┴────────────────────────────────┴─────────┴────────────────┴───────────────┴─────────────────────┘
(1 row)
if we select everything or
┌─────────────┐
│ recommender │
├─────────────┤
│ 1 │
└─────────────┘
(1 row)
which is what we actually select. Again, with the immediately above table as our working table, our recursive term gives us
┌─────────────┬───────┬─────────┬───────────┬────────────────────────────┬─────────┬──────────────┬───────────────┬─────────────────────┐
│ recommender │ memid │ surname │ firstname │ address │ zipcode │ telephone │ recommendedby │ joindate │
├─────────────┼───────┼─────────┼───────────┼────────────────────────────┼─────────┼──────────────┼───────────────┼─────────────────────┤
│ 1 │ 1 │ Smith │ Darren │ 8 Bloomsbury Close, Boston │ 4321 │ 555-555-5555 │ │ 2012-07-02 12:02:05 │
└─────────────┴───────┴─────────┴───────────┴────────────────────────────┴─────────┴──────────────┴───────────────┴─────────────────────┘
(1 row)
if we select everything or
┌─────────────┐
│ recommender │
├─────────────┤
│ │
└─────────────┘
(1 row)
which is what we actually select (no one recommended the member with ID 1). Finally, there's no query output whatsoever if we try to join the working table immediately above (which has only a NULL value) on cd.members. Thus the query terminates and we are left with the result of unioning together all of the working tables over the course of the iterative procedure:
┌─────────────┐
│ recommender │
├─────────────┤
│ 20 │
│ 5 │
│ 1 │
│ │
└─────────────┘
(4 rows)
Since we neither want nor need the NULL value in the final row, we could modify our recursive term ever so slightly to ensure we never get NULL values:
SELECT M.recommendedby AS recommender FROM up_rec_chain U INNER JOIN cd.members M ON U.recommender = M.memid WHERE M.recommendedby IS NOT NULL
And we can generally clean up our query to be more presentable by not putting so much on one line:
WITH RECURSIVE up_rec_chain AS (
SELECT
recommendedby AS recommender
FROM
cd.members M
WHERE
M.memid = 27
UNION ALL
SELECT
M.recommendedby AS recommender
FROM
up_rec_chain U
INNER JOIN cd.members M ON U.recommender = M.memid
WHERE
M.recommendedby IS NOT NULL
)
SELECT
*
FROM
up_rec_chain;
This yields
┌─────────────┐
│ recommender │
├─────────────┤
│ 20 │
│ 5 │
│ 1 │
└─────────────┘
(3 rows)
as our result set. We now have all we need (i.e., the ID numbers of all recommending members in the upward recommendation chain for member with ID 27) to form the expected result set for this proble--we simply need to add an inner join at the end to take advantage of our recursive CTE in order to get the actual requested member info for the recommending members:
WITH RECURSIVE up_rec_chain AS (
SELECT
recommendedby AS recommender
FROM
cd.members M
WHERE
M.memid = 27
UNION ALL
SELECT
M.recommendedby AS recommender
FROM
up_rec_chain U
INNER JOIN cd.members M ON U.recommender = M.memid
WHERE
M.recommendedby IS NOT NULL
)
SELECT
recommender, M.firstname, M.surname
FROM
up_rec_chain U
INNER JOIN cd.members M ON U.recommender = M.memid
ORDER BY
recommender DESC;
This gives us the desired result set:
┌─────────────┬───────────┬─────────┐
│ recommender │ firstname │ surname │
├─────────────┼───────────┼─────────┤
│ 20 │ Matthew │ Genting │
│ 5 │ Gerald │ Butters │
│ 1 │ Darren │ Smith │
└─────────────┴───────────┴─────────┘
(3 rows)
WITH RECURSIVE recommenders(recommender) AS (
SELECT
recommendedby
FROM
cd.members
WHERE
memid = 27
UNION
all
SELECT
mems.recommendedby
FROM
recommenders recs
INNER JOIN cd.members mems ON mems.memid = recs.recommender
)
SELECT
recs.recommender,
mems.firstname,
mems.surname
FROM
recommenders recs
INNER JOIN cd.members mems ON recs.recommender = mems.memid
ORDER BY
memid DESC;
WITH RECURSIVE is a fantastically useful piece of functionality that many developers are unaware of. It allows you to perform queries over hierarchies of data, which is very difficult by other means in SQL. Such scenarios often leave developers resorting to multiple round trips to the database system.
You've seen WITH before. The Common Table Expressions (CTEs) defined by WITH give you the ability to produce inline views over your data. This is normally just a syntactic convenience, but the RECURSIVE modifier adds the ability to join against results already produced to produce even more. A recursive WITH takes the basic form of:
WITH RECURSIVE NAME(columns) AS (
<initial statement>
UNION ALL
<recursive statement>
)
The initial statement populates the initial data, and then the recursive statement runs repeatedly to produce more. Each step of the recursion can access the CTE, but it sees within it only the data produced by the previous iteration. It repeats until an iteration produces no additional data.
The most simple example of a recursive WITH might look something like this:
WITH RECURSIVE increment(num) AS (
SELECT 1
UNION ALL
SELECT increment.num + 1 FROM increment WHERE increment.num < 5
)
SELECT * FROM increment;
The initial statement produces '1'. The first iteration of the recursive statement sees this as the content of increment, and produces '2'. The next iteration sees the content of increment as '2', and so on. Execution terminates when the recursive statement produces no additional data.
With the basics out of the way, it's fairly easy to explain our answer here. The initial statement gets the ID of the person who recommended the member we're interested in. The recursive statement takes the results of the initial statement, and finds the ID of the person who recommended them. This value gets forwarded on to the next iteration, and so on.
Now that we've constructed the recommenders CTE, all our main SELECT statement has to do is get the member IDs from recommenders, and join to them members table to find out their names.
Find the downward recommendation chain for member ID 1
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Find the downward recommendation chain for member ID 1: that is, the members they recommended, the members those members recommended, and so on. Return member ID and name, and order by ascending member id.
┌───────┬───────────┬───────────┐
│ memid │ firstname │ surname │
├───────┼───────────┼───────────┤
│ 4 │ Janice │ Joplette │
│ 5 │ Gerald │ Butters │
│ 7 │ Nancy │ Dare │
│ 10 │ Charles │ Owen │
│ 11 │ David │ Jones │
│ 14 │ Jack │ Smith │
│ 20 │ Matthew │ Genting │
│ 21 │ Anna │ Mackenzie │
│ 26 │ Douglas │ Jones │
│ 27 │ Henrietta │ Rumney │
└───────┴───────────┴───────────┘
(10 rows)
Read up on WITH RECURSIVE.
WITH RECURSIVE down_rec_chain AS (
SELECT
M.memid
FROM
cd.members M
WHERE
M.recommendedby = 1
UNION ALL
SELECT
M.memid
FROM
down_rec_chain U
INNER JOIN cd.members M ON U.memid = M.recommendedby
WHERE
M.recommendedby IS NOT NULL
)
SELECT
U.memid, M.firstname, M.surname
FROM
down_rec_chain U
INNER JOIN cd.members M ON U.memid = M.memid
ORDER BY
U.memid ASC;
WITH RECURSIVE recommendeds(memid) AS (
SELECT
memid
FROM
cd.members
WHERE
recommendedby = 1
UNION ALL
SELECT
mems.memid
FROM
recommendeds recs
INNER JOIN cd.members mems ON mems.recommendedby = recs.memid
)
SELECT
recs.memid,
mems.firstname,
mems.surname
FROM
recommendeds recs
INNER JOIN cd.members mems ON recs.memid = mems.memid
ORDER BY
memid;
This is a pretty minor variation on the previous question. The essential difference is that we're now heading in the opposite direction. One interesting point to note is that unlike the previous example, this CTE produces multiple rows per iteration, by virtue of the fact that we're heading down the recommendation tree (following all branches) rather than up it.
Produce a CTE that can return the upward recommendation chain for any member
- Question
- Expected Result
- Hint
- My Answer
- Discussion
- Schema Reminder
Produce a CTE that can return the upward recommendation chain for any member. You should be able to select recommender from recommenders where member=x. Demonstrate it by getting the chains for members 12 and 22. Results table should have member and recommender, ordered by member ascending, recommender descending.
┌────────┬─────────────┬───────────┬──────────┐
│ member │ recommender │ firstname │ surname │
├────────┼─────────────┼───────────┼──────────┤
│ 12 │ 9 │ Ponder │ Stibbons │
│ 12 │ 6 │ Burton │ Tracy │
│ 22 │ 16 │ Timothy │ Baker │
│ 22 │ 13 │ Jemima │ Farrell │
└────────┴─────────────┴───────────┴──────────┘
(4 rows)
Your initial statement should return all the recommendedby and memid fields in the members table.
WITH RECURSIVE up_rec_chain AS (
SELECT
M.memid AS member,
M.recommendedby AS recommender
FROM
cd.members M
UNION ALL
SELECT
member,
M.recommendedby AS recommender
FROM
up_rec_chain U
INNER JOIN cd.members M ON U.recommender = M.memid
WHERE
M.recommendedby IS NOT NULL
)
SELECT
member, recommender, firstname, surname
FROM
up_rec_chain U
INNER JOIN cd.members M ON U.recommender = M.memid
WHERE
member = 12 OR member = 22
ORDER BY
member ASC, recommender DESC;
WITH RECURSIVE recommenders(recommender, member) AS (
SELECT
recommendedby,
memid
FROM
cd.members
UNION ALL
SELECT
mems.recommendedby,
recs.member
FROM
recommenders recs
INNER JOIN cd.members mems ON mems.memid = recs.recommender
)
SELECT
recs.member member,
recs.recommender,
mems.firstname,
mems.surname
FROM
recommenders recs
INNER JOIN cd.members mems ON recs.recommender = mems.memid
WHERE
recs.member = 22
OR recs.member = 12
ORDER BY
recs.member ASC,
recs.recommender DESC;
This question requires us to produce a CTE that can calculate the upward recommendation chain for any user. Most of the complexity of working out the answer is in realising that we now need our CTE to produce two columns: one to contain the member we're asking about, and another to contain the members in their recommendation tree. Essentially what we're doing is producing a table that flattens out the recommendation hierarchy.
Since we're looking to produce the chain for every user, our initial statement needs to select data for each user: their ID and who recommended them. Subsequently, we want to pass the member field through each iteration without changing it, while getting the next recommender. You can see that the recursive part of our statement hasn't really changed, except to pass through the 'member' field.
Custom
Produce a CTE that can return the downward recommendation chain for any member
- Question
- Expected Result
- My Answer
- Schema Reminder
Produce a CTE that can return the downward recommendation chain for any member. You should be able to select recommender from recommenders where member=x. Demonstrate it by getting the chains for members 12 and 22. Results table should have member and recommender, ordered by member ascending, recommender descending.
┌────────────────────┬───────┬───────────┬───────────────────┐
│ common_recommender │ memid │ firstname │ surname │
├────────────────────┼───────┼───────────┼───────────────────┤
│ 1 │ 4 │ Janice │ Joplette │
│ 1 │ 5 │ Gerald │ Butters │
│ 1 │ 7 │ Nancy │ Dare │
│ 1 │ 10 │ Charles │ Owen │
│ 1 │ 11 │ David │ Jones │
│ 1 │ 14 │ Jack │ Smith │
│ 1 │ 20 │ Matthew │ Genting │
│ 1 │ 21 │ Anna │ Mackenzie │
│ 1 │ 26 │ Douglas │ Jones │
│ 1 │ 27 │ Henrietta │ Rumney │
│ 2 │ 29 │ Henry │ Worthington-Smyth │
│ 2 │ 30 │ Millicent │ Purview │
│ 2 │ 35 │ John │ Hunt │
│ 2 │ 36 │ Erica │ Crumpet │
│ 3 │ 8 │ Tim │ Boothe │
│ 4 │ 7 │ Nancy │ Dare │
│ 4 │ 11 │ David │ Jones │
│ 4 │ 26 │ Douglas │ Jones │
│ 5 │ 20 │ Matthew │ Genting │
│ 5 │ 27 │ Henrietta │ Rumney │
│ 6 │ 9 │ Ponder │ Stibbons │
│ 6 │ 12 │ Anne │ Baker │
│ 6 │ 15 │ Florence │ Bader │
│ 6 │ 24 │ Ramnaresh │ Sarwin │
│ 9 │ 12 │ Anne │ Baker │
│ 9 │ 15 │ Florence │ Bader │
│ 9 │ 24 │ Ramnaresh │ Sarwin │
│ 11 │ 26 │ Douglas │ Jones │
│ 13 │ 16 │ Timothy │ Baker │
│ 13 │ 17 │ David │ Pinker │
│ 13 │ 22 │ Joan │ Coplin │
│ 15 │ 24 │ Ramnaresh │ Sarwin │
│ 16 │ 22 │ Joan │ Coplin │
│ 20 │ 27 │ Henrietta │ Rumney │
│ 30 │ 35 │ John │ Hunt │
└────────────────────┴───────┴───────────┴───────────────────┘
(35 rows)
WITH RECURSIVE down_rec_chain AS (
SELECT
M.recommendedby AS common_recommender,
M.memid AS memid
FROM
cd.members M
WHERE
M.recommendedby IS NOT NULL
UNION ALL
SELECT
U.common_recommender,
M.memid
FROM
down_rec_chain U
INNER JOIN cd.members M ON U.memid = M.recommendedby
WHERE
M.recommendedby IS NOT NULL
)
SELECT
D.common_recommender, M.memid, M.firstname, M.surname
FROM
down_rec_chain D INNER JOIN cd.members M ON D.memid = M.memid
ORDER BY
D.common_recommender, M.memid, M.firstname, M.surname;