Part 9 - Data Structures in Assembly Language
Dynamic Memory Allocation
Just before a program starts running, the loader copies machine code from the executable file into the text segment of memory. It also copies data from the executable file into the data segment of memory.
Source code declares a fixed amount of memory (in the .data section for assembly language). But often as a program runs it requests more memory for data. The operating system finds a block of available memory and allocates it to the program. This is dynamic memory allocation.
Chapter Topics:
- Dynamic Memory Allocation
- Records and Structures
- Subroutine Calls with Structures
- C program versions of the above
Dynamic memory allocation is used in assembly language and high level languages for building data structures. In object oriented languages it is used to get the memory used to construct objects.
Question 1
(Review:) How many addresses does MIPS main storage have?
Answer
232 — about four billionReview of memory
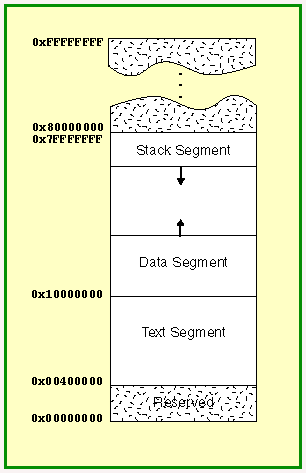
Recall (from chapter 10) that there are 232 bytes available in main memory, each one with its own address. Most of these bytes are virtual. They are implemented by the virtual memory system and do not directly correspond to bytes in RAM chips. But to executing programs it looks as if all the bytes are present.
Usually, with a multitasking system, the processor is shared among many executing programs. But the operating system makes it appear to each executing program as if it is the only one running on the system. Also, the operating system makes it look to each program as if 231 bytes are there for it alone. (The other half of memory is for the operating system.) For these chapters, ignore these details and just think of a program as running by itself in two billion bytes of memory and the operating system running in the other two billion bytes.
The picture shows a program running in the bottom half of memory and the operating system in the top half. The operating system divides the memory available to a program into sections. This is not required by hardware, but makes managing computer operations easier. The Text Segment holds the machine language of the program. The Data Segment holds the memory that has been allocated to the program just as it starts. The Stack Segment is for the run-time stack.
Between the data segment and the stack segment there is unallocated memory that is used for growing the stack (shown as the downward-pointing arrow at the top) or for creating dynamic data structures (shown as the upward-pointing arrow at the bottom). Both of these activities occur as the program is running.
The portion of memory above the data segment that has been allocated to data structures is called the heap.
Question 2
What is the process of allocating memory from the heap called?
Answer
Dynamic memory allocation
Dynamic memory allocation
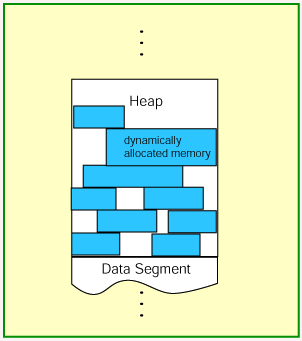
Dynamic memory allocation is when an executing program requests that the operating system give it a block of main memory. The program then uses this memory for some purpose. Usually the purpose is to add a node to a data structure. In object oriented languages, dynamic memory allocation is used to get the memory for a new object.
The memory comes from above the static part of the data segment. Programs may request memory and may also return previously dynamically allocated memory. Memory may be returned whenever it is no longer needed. Memory can be returned in any order without any relation to the order in which it was allocated. The heap may develop "holes" where previously allocated memory has been returned between blocks of memory still in use.
A new dynamic request for memory might return a range of addresses out of one of the holes. But it might not use up all the hole, so further dynamic requests might be satisfied out of the original hole.
If too many small holes develop, memory is wasted because the total memory used by the holes may be large, but the holes cannot be used to satisfy dynamic requests. This situation is called memory fragmentation. Keeping track of allocated and deallocated memory is complicated. A modern operating system does all this.
Question 3
Does the Stack Segment also have memory holes in it?
Answer
No. Recall that a stack has a "last-in, first-out" organization. Unneeded memory is always returned from the top of the stack.
SPIM dynamic memory
A stack is an easily managed structure. Only a few memory addresses are needed to keep track of it. (Some of these addresses are in the stack pointer and in the frame pointer registers.) As a program executes, the stack grows and shrinks as subroutines are called and exited.
The heap is more like a book shelf. Books are constantly being taken off the shelf from various locations, leaving gaps, and then later returned, filling the gaps.
Here is how a SPIM program requests a block of memory from SPIM's heap. The program uses code 9 for get more space.
li $a0,xxx # $a0 contains the number of bytes you need.
# This must be a multiple of four.
li $v0,9 # code 9 == allocate memory
syscall # call the service.
# $v0 <-- the address of the first byte
# of the dynamically allocated block
You don't know in advance what range of addresses you will get back for the allocate memory request. The SPIM service returns the first address of a contiguous block with as many bytes as you requested in $a0. (This is similar to a call to malloc() in "C".)
Question 4
In a full operating system, is there a service for deallocating memory, for returning a previously allocated block to the system?
Answer
Yes. But the SPIM service does not implement that. With SPIM you can request memory, but can't return it.
Impractical example
Here is a program that illustrates memory allocation. Of course, it is not a practical program except for use as an example.
The program: (1) asks SPIM for a block of memory four bytes long. It (2) makes a safe copy of the block's address in $s0. This program does not really need to do this, but it is good practice.
Next, (3), an integer is stored in the block. The address of the block is determined at run time. You can't get to it using a symbolic address in the program. But at run time the address is in $s0. So sw $t0,0($s0) stores 32 bits into the block.
# MallocOne.asm
#
# Allocate one block of memory, put an integer into it,
# print out the integer.
.text
.globl main
main:
li $v0,9 # (1) Allocate a block of memory
li $a0,4 # 4 bytes long
syscall # $v0 <-- address
move $s0,$v0 # (2) Make a safe copy
li $t0,77 # (3) Store value 77
sw $t0,0($s0) # into the block
lw $a0,0($s0) # (4) Load from the block
li $v0,1 # into $a0.
syscall # (5) Print the integer
li $v0,10 # Return to OS
syscall
## end of file
To illustrate that the first three steps worked as expected, the program next (4) loads register $a0 from the block of memory and (5) prints out that integer.
Question 5
Does the programmer ever need to know the address of the block?
Answer
No. When you get the block's address from SPIM you can use it. But you don't need to know what it is.
Picture
Except for debugging, usually you have no need to know the actual address of dynamically allocated blocks. But to start out let us look carefully at what happened. The picture shows SPIM after the program has run. The address of the block of memory is in $s0. This address is 10040000.
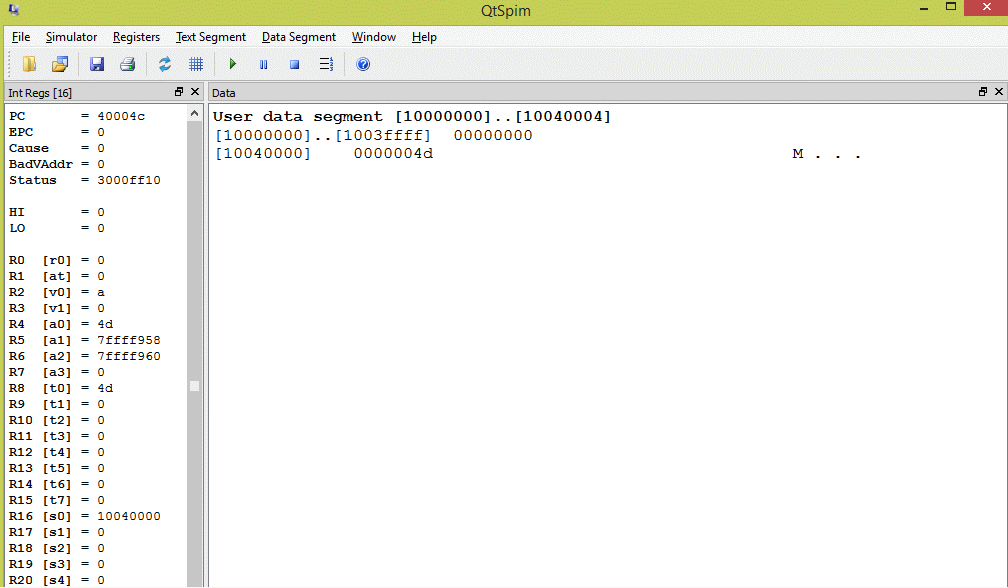
Looking in the data section at address 10040000 you find the block of four bytes. The program put the integer 77 (0x4d) into that block and the picture shows this.
Question 6
If another block of memory is allocated where will it be?
Answer
You can guess that it will follow the first block. However, this is not necessarily so, and you should not rely on this expectation. In a real operating system with many tasks and threads, it is almost certain that the next block will not immediately follow the first.
Records and structs
A record is a block of memory that contains several data items. The data may be of several types, say an int followed by a float followed by a short. The language "C" calls this idea a struct (short for "structure"). An big extension of this idea is called an "object". Records are frequently stored in dynamically allocated memory. Say that you had hundreds of data that look like this:
struct
{
int age;
int pay;
int class;
};
This just says that each data item consists of three integers, the age of a person, their pay rate, and their job classification.
Question 7
In MIPS, how many bytes are needed for this struct?
Answer
12 bytes, four bytes for each of three integers.
Fields within a struct
A block of memory for this struct consists of twelve bytes. The first field (age) is located at a displacement of zero into the block. The second field (pay) is located at a displacement of four into the block. The last field (class) is located at a displacement of eight into the block.
struct
{
int age;
int pay;
int class;
};
Warning: C and C++ compilers are free to rearrange the order of items inside a struct and to do other things for optimization or hardware compatibility. Worse yet, different compilers may do different things. Do not write C programs that make assumptions about the internal structure of a struct.
Question 8
Say that register $s1 holds the address of a struct like the above. Fill in the blank so that register $t0 gets the value in the pay field:
lw $t0 , ______ ( ______ ) # load the pay
Answer
lw $t0,4($s1) # load the pay
Example program with struct
Here is a program that allocates memory for a struct, then puts data in each field. It then makes a copy of the struct by allocating another block of memory and copying corresponding fields from the first struct to the second struct.

Question 9
Fill in the blanks to compete the program.
Answer
# copy data from first struct to second
lw $t0,0($s1) # copy age from first
sw $t0,0($s2) # to second struct
lw $t0, 4 ($s1) # copy pay from first
sw $t0, 4 ($s2) # to second struct
lw $t0, 8 ($s1) # copy class from first
sw $t0, 8 ($s2) # to second struct
Classic confusion
Students who rush through this material often pay for their speed with hours of confusion later on. Working with addresses and the contents of addresses can be confusing. I speak from experience here, both experience with students and experience in being confused.
The classic prevention to classic confusion is to study a simple program. Such as this one. Copy the program into your editor, paste it to a file and play with it.
The program is more interesting if it writes some output. Here is another block of code to insert just before the end:

Question 10
You weren't expecting to get that code for free, were you? Fill in those blanks.
Hint: pick from li, la, and lw for each blank.
Answer
# write out the second struct
la $a0,agest # print "age:"
li $v0,4 # print string service
syscall
lw $a0,0($s2) # print age
li $v0,1 # print int service
syscall
li $v0,10 # return to OS
syscall
.data
pay: .word 24000 # rate of pay, in static memory
agest: .asciiz "age: "
Print struct subroutine
Data that is contained in a struct is treated as a whole. In OO terms, it is treated like an object. It would be nice to have a subroutine that takes one of our structs as a parameter and prints it out. Let us write a subroutine that uses the Stack-based Calling Convention of Chapter 27. (It might not hurt you to review that chapter.)
Here is a small subroutine. For now, it only prints out the age field of the argument struct. It uses register $s0 so it must first push the value in that register on the stack. It does not call any other subroutine so it does not need to push $ra. (The SPIM service requests do not change $ra.)
The argument is the address of the struct. A large struct can be passed as an argument to a subroutine by giving the subroutine the address of the struct. The various fields of the struct are accessed using displacements off the address.
# Subroutine PStruct: print a struct
#
# Registers on entry: $a0 --- address of the struct
# $ra --- return address
#
# Registers: $s0 --- address of the struct
#
.text
PStruct:
sub $sp,$sp,4 # push $s0
sw $s0,($sp) # onto the stack
move $s0,$a0 # make a safe copy
# of struct address
la $a0,agest # print "age:"
li $v0,4
syscall
lw $a0,0($s0) # print age
li $v0,1
syscall
add $sp,$sp,4 # restore $s0 of caller
lw $s0,($sp)
jr $ra # return to caller
.data
agest: .asciiz "age: "
For example, the age field of our struct is a displacement of zero off of the struct's base address. So this code gets the integer age using the statement lw $a0,0($s0).
Question 11
Why is register $s0 used in this routine?
Answer
By convention, register $a0 is used to pass the argument. But in the body of the subroutine register $a0 is used to pass arguments to the SPIM service. So a safe copy must be made in an "S" register.
Calling the subroutine
Here is a section of the main program. It prints out the contents of both structs:

Question 12
Fill in the blanks. Look back at the subroutine if needed.
Answer
. . . .
# $s1 contains the address of the first struct
# $s2 contains the address of the second struct
#
# write out the first struct
move $a0,$s1
jal PStruct
# write out the second struct
move $a0,$s2
jal PStruct
Subroutine gets an address
When you call a subroutine in this manner, you probably think of the struct as being "sent" to the subroutine. In reality, the struct stays where it is and the subroutine just gets its address.
The subroutine now has full access to the struct and can copy values from fields and change values in field. There is only one instance of this struct. If the subroutine changes a field it is a permanent change.
Some high level language use other methods of passing arguments. The style discussed here is similar to ANSI C.
Question 13
Would looking at and playing with a complete program help?
Answer
Of course!
Complete program
Here is a complete version of the program. It creates and initializes a struct. Then it creates a second struct and copies the first struct's data to it. Finally it prints out the data in both structs using a subroutine.
# StructPrint.asm
#
# Allocate memory for a struct and then initialize it.
# Allocate memory for a second struct and copy data
# from the first into it. Print both structs
.text
.globl main
main:
# create the first struct
li $v0,9 # allocate memory
li $a0,12 # 12 bytes
syscall # $v0 <-- address
move $s1,$v0 # $s1 first struct
# initialize the first struct
li $t0,34 # store 34
sw $t0,0($s1) # in age
lw $t0,pay # store 24000
sw $t0,4($s1) # in pay
li $t0,12 # store 12
sw $t0,8($s1) # in class
# create the second struct
li $v0,9 # allocate memory
li $a0,12 # 12 bytes
syscall # $v0 <-- address
move $s2,$v0 # $s2 second struct
# copy data from first struct to second
lw $t0,0($s1) # copy age from first
sw $t0,0($s2) # to second struct
lw $t0,4($s1) # copy pay from first
sw $t0,4($s2) # to second struct
lw $t0,8($s1) # copy class from first
sw $t0,8($s2) # to second struct
# write out the first struct
move $a0,$s1
jal PStruct
# write out the second struct
move $a0,$s2
jal PStruct
li $v0,10 # return to OS
syscall
.data
pay: .word 24000 # rate of pay, in static memory
.text
# Subroutine PStruct: print a struct
#
# Registers: $a0 --- address of the struct
# $ra --- return address
PStruct:
sub $sp,$sp,4 # push $s0
sw $s0,($sp) # onto the stack
move $s0,$a0 # safe copy of struct address
la $a0,agest # print "age:"
li $v0,4
syscall
lw $a0,0($s0) # print age
li $v0,1
syscall
la $a0,payst # print " pay: "
li $v0,4
syscall
lw $a0,4($s0) # print pay
li $v0,1
syscall
la $a0,classt # print " class: "
li $v0,4
syscall
lw $a0,8($s0) # print class
li $v0,1
syscall
la $a0,lf # end the line
li $v0,4
syscall
add $sp,$sp,4 # restore $s0 of caller
lw $s0,($sp)
jr $ra # return to caller
.data
agest: .asciiz "age: "
payst: .asciiz " pay: "
classt: .asciiz " class: "
lf: .asciiz "\n"
## end of file
The subroutine has been extended so that all fields are printed. The argument remains as the address of a struct.
Question 14
How is a memory allocation request done in C?
Answer
A program in ANSI C asks for memory to be allocated with malloc().
malloc()
If you don't know C, the remaining pages of this chapter can be skipped. However, they should be readable by everyone.
The malloc() function from the C standard library requests a block of memory.
void *malloc(size_t size)
The function allocates a block of memory of size number of bytes, and returns the address of the first byte of that block. (The data type of size is an unsigned integer. The return type of the function is void * which is the way ANSI C describes a memory address.)
Here is the start of our example assembly program:
main:
# create the first struct
li $v0,9 # allocate memory
li $a0,12 # 12 bytes
syscall # $v0 <-- address
move $s1,$v0 # $s1 first struct
. . . .
And here is how this would be done in C:
#include <stdlib.h> /* include a header file of standard definitions */
struct EMPLOYEE /* Declaration of a type of struct */
{ /* This does not allocate any memory */
int age;
int pay;
int class;
};
main()
{
struct EMPLOYEE *empA; /* declaration of the pointer variable empA */
empA = (struct EMPLOYEE *)malloc( sizeof( struct EMPLOYEE) );
. . . .
The source code starts by including a file of standard definitions that the compiler may use in compiling this source program. Then the EMPLOYEE structure is declared. This describes a layout of a memory block but does not itself request memory.
The main() routine of C is equivalent to the main entry point of an assembly language program. It is where the operating system first sends control when it starts the program running.
The declaration of empA describes it as a variable that is expected to contain an address of a block of memory suitable for an EMPLOYEE structure. In C, this type of variable is called a pointer.
The final statement (in this fragment) requests a block of memory. The number of bytes is the size needed the structure. The compiler determines this using the sizeof operator. (Or we could explicitly put "12", but this is poor coding technique.)
The address of the dynamically allocated block of memory is returned by malloc() and assigned to the variable empA.
Question 15
Where in memory will the allocated bytes of memory come from?
Answer
From the heap.
Assigning values to the struct
The assembly language program continues by assigning values into the dynamically allocated block of memory:
# initialize the first struct
li $t0,34 # store 34
sw $t0,0($s1) # in age
lw $t0,pay # store 24000
sw $t0,4($s1) # in pay
li $t0,12 # store 12
sw $t0,8($s1) # in class
Here is how the C program does this:
empA->age = 34;
empA->pay = 24000;
empA->class = 12;
The pointer variable empA holds the address of a block of memory, just as does the register $s1. The expression empA->pay means to go to the block of memory at the address in empA, then use the bytes where pay is located.
Question 16
Could C allocate a second block of memory for a second struct?
Answer
Of course!
A second struct
The assembly language program continues by allocating memory for a second struct and copying values from the first struct to the second:
# create the second struct
li $v0,9 # allocate memory
li $a0,12 # 12 bytes
syscall # $v0 <-- address
move $s2,$v0 # $s2 second struct
# copy data from first struct to second
lw $t0,0($s1) # copy age from first
sw $t0,0($s2) # to second struct
lw $t0,4($s1) # copy pay from first
sw $t0,4($s2) # to second struct
lw $t0,8($s1) # copy class from first
sw $t0,8($s2) # to second struct
And so does the C program:
struct EMPLOYEE *empB; /* declaration of a second pointer variable empB */
empB = (struct EMPLOYEE *)malloc( sizeof( struct EMPLOYEE) );
empB->age = empA->age;
empB->pay = empA->pay;
empB->class = empA->class;
The variables empA and empB act as base addresses. The a field of a struct is located at a displacement off of a base address.
Question 17
What do you think would be the result of the following C statement?
empB = empA;
Answer
empB = empA;
The address contained in empA is copied to empB.
Copying addresses
The statement
empB = empA;
is the equivalent of
move $s2,$s1
Addresses are copied from one variable to another, but the structs in memory are unaffected.
Question 18
Do C programs call subroutines?
Answer
Yes.
Subroutine calls
Here is how the assembly language calls the subroutine with the address of a struct as a parameter:
# write out the first struct
move $a0,$s1
jal PStruct
# write out the second struct
move $a0,$s2
jal PStruct
And here is how C does this:
PStruct( empA ); /* Write out the first struct */
PStruct( empB ); /* Write out the second struct */
Notice how the C subroutine (and the assembly subroutine) is called with a value: the address of a struct.
Question 19
If a subroutine has the address of a block of memory, can it then access that memory, and perhaps alter it?
Answer
Yes.
Subroutine PStruct
Here is the original (short) version of the subroutine in assembly:
# Subroutine PStruct: print a struct
#
# Registers on entry: $a0 --- address of the struct
# $ra --- return address
#
# Registers: $s0 --- address of the struct
#
.text
PStruct:
sub $sp,$sp,4 # push $s0
sw $s0,($sp) # onto the stack
move $s0,$a0 # make a safe copy
# of struct address
la $a0,agest # print "age:"
li $v0,4
syscall
lw $a0,0($s0) # print age
li $v0,1
syscall
add $sp,$sp,4 # restore $s0 of caller
lw $s0,($sp)
jr $ra # return to caller
.data
agest: .asciiz "age: "
And here is the equivalent in C:
void PStruct( struct EMPLOYEE *emp )
{
printf("age: %d", emp->age );
}
The parameter list of the C subroutine says that its parameter is a pointer to an EMPLOYEE structure. This pointer (address) will be called emp. The structure is accessed by following the address: emp-> and parts of the structure are accessed by displacements into the block of memory: emp->age.
Question 20
Does the C subroutine explicitly contain code for the subroutine prolog and epilog?
Answer
No. The compiler supplies the machine code for this automatically.
Complete C program
Here is a complete C program, roughly the equivalent of the assembly language program:
#include <stdlib.h> /* include a header file of standard definitions */
struct EMPLOYEE /* Declaration of a type of struct */
{ /* This does not allocate any memory */
int age;
int pay;
int class;
};
main()
{
struct EMPLOYEE *empA; /* declaration of the pointer variable empA */
empA = (struct EMPLOYEE *)malloc( sizeof( struct EMPLOYEE) );
empA->age = 34;
empA->pay = 24000;
empA->class = 12;
struct EMPLOYEE *empB; /* declaration of a second pointer variable empB */
empB = (struct EMPLOYEE *)malloc( sizeof( struct EMPLOYEE) );
empB->age = empA->age;
empB->pay = empA->pay;
empB->class = empA->class;
PStruct( empA ); /* Write out the first struct */
PStruct( empB ); /* Write out the second struct */
system("pause");
}
void PStruct( struct EMPLOYEE *emp )
{
printf("age: %d ", emp->age );
printf("pay: %d ", emp->pay );
printf("class: %d\n", emp->class );
}
The print subroutine has been expanded to print out all the fields of the struct.
Question 21
Think of some interesting things to do with these programs.
Answer
No, I didn't mean that! I meant to say useful and interesting.
Here is my list of useful and things that you might like to try:
- Put statements in the print subroutine that alter data in the struct.
- Write a subroutine that copies data from one struct to another. The subroutine will have two arguments, the address of each struct.
- Write a subroutine that swaps the values of two structs.
- Put more fields in the struct and modify all the routines.
Chapter quiz
Instructions: For each question, choose the single best answer. Make your choice by clicking on its button. You can change your answers at any time. When the quiz is graded, the correct answers will appear in the box after each question.
Question 1
How much of the 4 gigabytes of virtual memory does a user program run in?
- (A) none of it
- (B) about one quarter
- (C) roughly half
- (D) all of it
Answer
C
Question 2
If the maximum address is 0xFFFFFFFF, what address is half of that?
- (A) 0x0000FFFF
- (B) 0x77777777
- (C) 0x7FFFFFFF
- (D) 0xFFFF0000
Answer
C
Question 3
What is it called when memory for a program is allocated as the program is running?
- (A) static memory allocation
- (B) dynamic memory allocation
- (C) stack memory allocation
- (D) virtual memory allocation
Answer
B
Question 4
What segment of memory is used for the data that is statically declared in a program?
- (A) data segment
- (B) static segment
- (C) stack segment
- (D) heap
Answer
A
Question 5
Which of the following code fragments requests 16 bytes of memory?
(A)
li $a0, 16
li $v0, 9
syscall(B)
li $a0, 16
li $v0, 9(C)
li $a1, 16
li $v1, 9
syscall(D)
li $a0, 9
li $v0, 16
syscall
Answer
A
Question 6
With an actual operating system (not the simple trap handler of SPIM) is dynamic memory every returned to the system?
- (A) No. Memory can never be returned because that would leave inaccessible gaps.
- (B) No. Since there is an unlimited amount of virtual memory there is no reason to every give any back.
- (C) Yes. After being returned, it might be used again to satisfy another request for memory.
- (D) Yes. But once returned it is no longer available.
Answer
C
Question 7
With an actual operating system, can the address of a block of dynamic memory be predicted before it is allocated?
- (A) No, because virtual memory addresses follow no order.
- (B) No, because the operating system uses complex algorithms to find an available block.
- (C) Yes, blocks are always allocated in sequential order.
- (D) Yes, because the program can request particular addresses.
Answer
B
Question 8
Say that the base address of the following structure is in register $s8 and that the order of data in the structure has not been altered.
struct
{
int valA;
int valB;
int rate;
}
Which of the following code fragments loads $t0 with rate?
- (A)
lw $s8,8($t0) - (B)
li $t0,8($s8) - (C)
lw $t0,($s8) - (D)
lw $t0,8($s8)
Answer
D
Question 9
In a high level language like C is the actual byte-level layout of data in a struct exactly determined by its declaration?
- (A) No. Compilers are free to rearrange the order of variables and to insert extra bytes into the data.
- (B) No. The operating system may rearrange the order of the variables.
- (C) Yes. High level languages specify exactly how data is laid out at the byte level.
- (D) Yes. C, C++, and other languages lay out structures in exactly the same way.
Answer
A
Question 10
The grouping of data that C calls a struct is called what in Pascal and COBOL?
- (A) object
- (B) entity
- (C) record
- (D) trace
Answer
C
Programming exercises
NOTE: If you have read the chapters on subroutine linkage, write each exercise as a main program calling a subroutine. Use either the stack-based linkage or the frame-based linkage convention.
In the Settings menu of SPIM set Bare Machine OFF, Allow Pseudo Instructions ON, Load Trap File ON, Delayed Branches OFF, Delayed Loads OFF, Mapped IO ON, Quiet OFF.
Run the programs by clicking SimulatorGo and then OK in the pop-up panel.
Exercise 1 - date
Consider the following structure:
struct
{
int day;
int month;
int year;
}
Write a program that allocates memory for such a structure and fills it in with values such as 9/7/2003.
Write out the values in the structure.
Exercise 2 - array of structures
Consider the following structure, the same as for Exercise 1:
struct
{
int day;
int month;
int year;
}
Write a program that asks the user for how many dates are needed and then allocates space (all at one time) for that many structs.
Then, in a loop, ask the user for the values to put in each structure. Do this by initializing a structure pointer to the first address of the allocated space. Then add the size of a structure to it for each execution of the loop.
Finally, write out the contents of all the structures.
Exercise 3 - array of structure pointers
Consider the following structure, the same as for the above exercises:
struct
{
int day;
int month;
int year;
}
In the static data section of your program declare space for an array of up to 25 addresses:
.data
size: .word 0
dates: .space 25*4
Not all of the potential addresses will be used. The field size starts at zero because to start, none of the addresses are used.
Write a program that asks the user for how many dates are needed. Set size to that amount. Now a counting loop executes for that many times. Each execution of the loop allocates space for one data, puts the address of that date in the array of addresses, asks the user for values for that data, and finally, fills the date with those values.
At the end of the program write out the values in the dates. Do this by scanning through the array of addresses to access each date. (Probably the dates will be in order in a contiguous block of memory, but a real-world program can not count on this being true.)
Exercise 4 - image allocation
Write a program that asks the user for the size of an image: R rows and C columns. Then allocate space for R*C bytes.
Fill row 1 with 1s, fill row 2 with 2s, and so on. Examine the data section of the simulator to see if you did this correctly.
Data Structures
Today, assembly language would not be your first choice for building a data structure. But in the past, data structures were more easily built with assembly language than with the other programming languages of the time. In the first book written about data structures, The Art of Computer Programming by Donald Knuth (1968), the examples were done in assembly language.
Times have changed. Today most programming is done with languages like Java or C. Data structures are easily implemented in these languages. But of course, the programs are compiled, and ultimately they execute as machine code. To find out what is really going on, it helps to look at data structures in assembly language.
Chapter Topics:
- Data structures
- Linear structures
- Linked lists in assembly language
- Traversal of a linked list
- Pointers
Question 1
(Review:) What is a data structure?
Answer
A data structure is a collection of data that includes the structural relationships between the data.
Data structures
If you didn't know what a data structure was, it is doubtful if this (or any other) definition would help much. So consider an everyday data structure: an ordered list. Here is a list of five numbers:
1
2
3
5
7
Each integer is an item of data. The structure is the order in which they are listed. Each integer is put in the correct place in relation to the other data.
An ordered list is a variety of linear data structure. The structural relationship between the data is this: Except for the first item and the last item, each item in the list has one successor and one predecessor. The first item in the list has one successor but no predecessor. The last item in the list has one predecessor but no successor.
Question 2
Is the following the same list as the one above?
2
7
3
1
5
Answer
No. The nodes (data items) are the same, but their relationships are different.
Node
Data structures can be built in main memory, on hard disk, on punch cards, across the Internet, or in any combination of any media that can store bits. Let us simplify things and only talk about data structures built in main memory.
A node in a data structure is an item of data. The "structure" of the data structure consists of the relationships between the nodes. Often nodes are called elements. When thinking about the structure part of a data structure each node is an indivisible unit. Here is a picture of the list of the five numbers:

The arrows show the successor and predecessor relationships. The first node of the list has no arrow going into it; the last node of the list has no arrow leaving it. Here is the structure without the data:

Question 3
Could types of data other than integers fit into the structure of this list?
Answer
But of course!
Node data
Here is a list of types of mustard:
- Dijon
- Yellow
- Honey
- Brown
- Colonel
Here is a picture of the data structure (both data and structure):

Question 4
What is the third letter in the first node of this data structure?
Answer
The character 'j'.
Internal structure
Often the nodes of a data structure themselves have structure. Each item on our list is a sequence of characters. This is OK. The internal structure of the nodes does not interfere with our view of the relationships between nodes.
It is common to have data structures that contain data structures as data, that further contain data structures as data, somewhat like a college campus contains buildings, that contain rooms, that contain rows of desks.
Question 5
Have you already seen ordered lists of integers in assembly language?
Answer
Yes. An array of integers.
Ordered list as array
The list of integers could be placed into an array. In assembly language an array of integers is declared using the directive .word followed by a list of comma separated integers. Often the array is preceded by a word that holds the size of the array.
.data
size: .word 5
list: .word 1,2,3,5,7
In practical programming a list of integers would probably be implemented as an array. Arrays have many advantages. But they also have disadvantages. Sometimes the nodes of the data structure come in several sizes, or the length of the list is highly variable. Then a linked list may be the best implementation.
Question 6
In the array implementation of the list, is it possible for the list to grow in size?
Answer
No, not easily.
Linked list
A linked list overcomes some of the disadvantages of arrays (and introduces its own disadvantages). In a linked list, each node consists of two items:
- The data
- The address of the next node
The picture shows the idea. Each rectangle represents a block of memory. Part of the block holds the data, and the other part holds the address of the next block of data.

The arrows represent memory addresses. The diagonal slash in the last node stands for the value null which is how the last node shows that it has no successor. In MIPS assembly (and in most other languages), null is a word full of zero bits.
Question 7
Here is a node of a linked list:
.data
elmnt01: .word 1
next01: .word _____
Here, somewhere else in the program, is the second node:
elmnt02: .word 2
next02: .word .....
Fill in the blank so that the field next01 contains the address of the second node.
Answer
.data
elmnt01: .word 1
next01: .word elmnt02
. . . . .
elmnt02: .word 2
next02: .word .....
Links of a linked list
A symbolic address such as elmnt02 is a symbol in a source program that stands for an address. The above program fragment corresponds to this picture:

The two nodes are not necessarily next to each other in memory. The following fragment implements the entire five node linked list:
.data
elmnt01: .word 1
.word elmnt02
elmnt02: .word 2
.word elmnt03
elmnt03: .word 3
.word elmnt04
elmnt04: .word 5
.word elmnt05
elmnt05: .word 7
.word 0
Each node contains the address of its successor node. The field that holds this address is called the next field or (to avoid ambiguity) the link field. There is no need to provide a label for this field in the nodes.
In a practical program you would never implement a linked list by explicitly coding it this way. And usually there is more data per node than a single integer. But for now let us keep it simple.
Question 8
Is the following a logically equivalent implementation of the list?
.data
elmnt05: .word 7
.word 0
elmnt02: .word 2
.word elmnt03
elmnt03: .word 3
.word elmnt04
elmnt01: .word 1
.word elmnt02
elmnt04: .word 5
.word elmnt05
Answer
Yes. The new arrangement of memory implements the logical structure of the linked list.
Memory dump
Here is the code fragment (again). Notice how the address is put into the link field of each node by using the symbolic address of the node's successor.
.data
elmnt01: .word 1
.word elmnt02
elmnt02: .word 2
.word elmnt03
elmnt03: .word 3
.word elmnt04
elmnt04: .word 5
.word elmnt05
elmnt05: .word 7
.word 0
And here is how it is assembled by SPIM:

Each node consists of two words of data: the integer followed by the address of the next node. In this memory dump the nodes follow each other in order.
Question 9
At what address is the first node in the linked list?
What is the address in its link field?
What is the address of the second node in the linked list?
Answer
At what address is the first node in the linked list? 0x10010000
What is the address in its link field? 0x10010008
What is the address of the second node in the linked list? 0x10010008
Pointers
When a memory address is used as a link between nodes of a data structure it is sometimes called a pointer. In some higher level languages (such as C) a pointer is exactly the same as a main memory address. Other languages (such as object oriented languages) require a pointer to have more features than a raw memory address can provide. In these languages a "pointer" is more elaborate than a memory address.
For this course, let us regard "pointer" and "memory address" as exactly the same. Sometimes the word "reference" is used for the link to a node. But in Java (for example), an object reference is not a raw memory address.
Question 10
(Review:) What bit pattern is used to represent null?
Answer
In MIPS, 32 zero bits.
Traversing a linked list
Let us write a program that visits every node of a linked list and prints out its data. A visit to every node of a data structure is called a traversal. Here is a start on the program:

The first statement loads register $s0 with the address of the first node.
Question 11
Which instruction should fill the blank in the first statement:
lw— load a register with the data stored at a symbolic addressla— load a register with the address corresponding to a symbolic address
Answer
la — load a register with the address corresponding to a symbolic address
Address of a word vs. contents of a word
Here is the fragment:
## linked.asm --- hard-coded linked list
##
.text
.globl main
main:
la $s0,elmnt01 # get the address of
# the first node
loop: beqz $s0,done # while not null
. . .
done:
. . .
.data
elmnt01: .word 1
.word elmnt02
elmnt02: .word 2
.word elmnt03
. . .
Bug Alert! To get the address in memory corresponding to a symbolic address, use the la instruction. The lw loads the value stored at that address.
In this program, register $s0 contains the address of each node as it is visited. So to start it out correctly use the la instruction.
Question 12
Examine this fragment:
la $s0,head
lw $s1,head
. . .
.data
head: .word 7
Which register, $s0 or $s1, contains the value 7 after this fragment executes?
Answer
$s1
Following a link
Here is more of the program:
## linked.asm --- hard-coded linked list
##
.text
.globl main
main:
la $s0,elmnt01 # get a pointer to the first node
loop: beqz $s0,done # while the pointer is not null
lw $a0,0($s0) # get the data of this node
. . . # do something with the node
lw $s0,4($s0) # get the pointer to the next node
b loop
done:
.data
elmnt01: .word 1 # displacement 0 off the pointer
.word elmnt02 # displacement 4 off the pointer
. . .
The program starts with the first node. Then (after doing something with the first node) it moves on to the second node by loading the address contained in the link field of the node.
In this case, you want to load data from an address into a register. So the lw instruction is the correct one to use.
Question 13
What does it mean if the link field (the pointer) of a node contains a null?
Answer
The node is the last one in the list.
While not null
The idea is to keep "advancing" the pointer $s0 from node to node until it contains a null. This is done in a loop. The null pointer is detected with a beqz instruction.
main:
la $s0,elmnt01 # get a pointer to the first node
loop: beqz $s0,done # while the pointer is not null
lw $a0,0($s0) # get the data of this node
. . . # do something with the node
lw $s0,4($s0) # get the pointer to the next node
b loop
done:
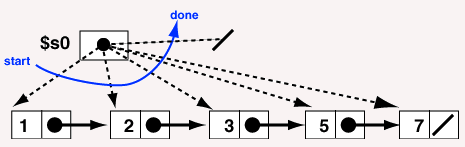
Here is a picture that shows the pointer advancing through the nodes until it becomes null:
Question 14
Is there a limit to the size of linked list that this program can handle?
Answer
No.
Printing each node
The loop is a sentinel controlled loop. It keeps going until it hits the special value that signals the end. Here is the code with some new lines that print the data of each node:
main:
la $s0,elmnt01 # get a pointer to the first node
loop: beqz $s0,done # while the pointer is not null
lw $a0,0($s0) # get the data of this node
# do something with the node
li $v0,1 # print it
syscall #
la $a0,sep # print separator
li $v0,4 #
syscall #
lw $s0,4($s0) # get the pointer to the next node
b loop
done: . . .
.data
elmnt01: .word 1
.word elmnt02
elmnt02: .word 2
.word elmnt03
elmnt03: .word 3
.word elmnt04
elmnt04: .word 5
.word elmnt05
elmnt05: .word 7
.word 0
sep: .asciiz " "
The code that traverses the list is in black; the code that processes the data at each node is in blue.
Question 15
What needs to be done after the loop is done?
Answer
Not too much: end the current output line, perhaps write a final message, and return to the OS.
Complete program
Here is the complete program. The head of a linked list is the first node of the list. The complete program uses head as an alternate name for the address of the first node.
## linked.asm --- hard-coded linked list
##
.text
.globl main
main:
la $s0,head # get pointer to head
loop: beqz $s0,done # while not null
lw $a0,0($s0) # get the data
li $v0,1 # print it
syscall #
la $a0,sep # print separator
li $v0,4
syscall
lw $s0,4($s0) # get next
b loop
done: la $a0,linef # print end of line
li $v0,4
syscall # print ending message
la $a0,endmess
li $v0,4
syscall
li $v0,10 # return to OS
syscall
.data
head:
elmnt01: .word 1
.word elmnt02
elmnt02: .word 2
.word elmnt03
elmnt03: .word 3
.word elmnt04
elmnt04: .word 5
.word elmnt05
elmnt05: .word 7
.word 0
sep: .asciiz " "
linef: .asciiz "\n"
endmess: .asciiz "done\n"
Question 16
If $s0 is pointing at the first node, is it possible to jump immediately to the fourth node?
Answer
No. You have to go through the list link by link. (Actually, in the hand-coded list, above, you could calculate where the fourth node was, but in general this can't be done.)
Chapter quiz
Instructions: For each question, choose the single best answer. Make your choice by clicking on its button. You can change your answers at any time. When the quiz is graded, the correct answers will appear in the box after each question.
Question 1
Which was the first book written on data structures?
- (A) Programming Paradigms
- (B) Fundamentals of Data Structures
- (C) DOS for Dummies
- (D) The Art of Computer Programming
Answer
D
Question 2
What is a data structure?
- (A) Any collection of data in main memory.
- (B) A collection of data that includes the structural relationships betweeen the data.
- (C) A collection of data and subroutines that operate on the data.
- (D) Any empty form that can be filled in with data.
Answer
B
Question 3
In a linear data structure, each element has a (1)___________ and a (2)_________, except for the first element which has no (3)__________ and the last element which has no (4)____________.
- (A) (1) predecessor, (2) successor, (3) predecessor, (4) successor.
- (B) (1) predecessor, (2) successor, (3) successor, (4) predecessor.
- (C) (1) head, (2) tail, (3) tail, (4) head.
- (D) (1) data, (2) link, (3) data, (4) link.
Answer
A
Question 4
May the data in an element of a data structure itself have structure?
- (A) No. Data must be the same size as the MIPS word size.
- (B) No. Data must be a primitive type such as integer or float.
- (C) Yes. The internal structure of the data in a node may be arbitrarily complex.
- (D) Yes. It can have the same structure as the outer structure of all the data.
Answer
C
Question 5
What are the two sections of a node in a linked list?
- (A) The data and the counter.
- (B) The data and the null.
- (C) The data and the link to the successor node.
- (D) The data and the link to the predecessor node.
Answer
C
Question 6
Examine this fragment:
????? $s0,head
. . .
.data
head: .word 7
Replace ???? with the instruction that will place the address of head into $s0.
- (A)
lw - (B)
li - (C)
la - (D)
sw
Answer
C
Question 7
Examine this fragment:
????? $s0,head
. . .
.data
head: .word 7
Replace ???? with the instruction that will place the contents of head into $s0.
- (A)
lw - (B)
li - (C)
la - (D)
sw
Answer
A
Question 8
Examine the following code fragment, which traverses a linked list starting at the head. Each node is 8 bytes long.
la $s1,head
loop: ???? $s1,exit
....
lw $s1,4($s1)
b loop
What instruction should replace ????
- (A)
jr - (B)
lw - (C)
bnez - (D)
beqz
Answer
D
Question 9
What is the usual value used for null with a data structure?
- (A)
0x00000000 - (B)
0x00 - (C)
0xFFFFFFFF - (D)
0x11111111
Answer
A
Question 10
Are the nodes of a linked list always arranged in in order in main memory?
- (A) No. This might happen, but usually does not.
- (B) No. The nodes are always contiguous, but not may not be in order.
- (C) Yes. In a linear data structure the data in memory is laid out in order.
- (D) Yes. In order to traverse the structure the data must be in order.
Answer
A
Programming exercises
NOTE: If you have read the chapters on subroutine linkage, write each exercise as a main program calling a subroutine. Use either the stack-based linkage or the frame-based linkage convention.
In the Settings menu of SPIM set Bare Machine OFF, Allow Pseudo Instructions ON, Load Trap File ON, Delayed Branches OFF, Delayed Loads OFF, Mapped IO ON, Quiet OFF.
Run the programs by clicking SimulatorGo and then OK in the pop-up panel.
Exercise 1 - rearranged linked list
Copy the final program of the chapter, linked.asm and get it to work. Now rearrange the order of the elements of the linked list that are declared in memory. Check that the program still works.
Next, add more elements to the list. If you wish to keep this a list of prime numbers, add elements for 11, 13, 17, 19, and 23. Add these to scattered locations in the data section. Check that the program still works.
Exercise 2 - two linked lists
In the data section declare linked list nodes for the integers 1 through 25 (using copy and paste in your text editor will help here.) Declare two symbolic addresses headP for the address of the node that contains 1, and headC for the address of the node that contains 4.
Regard headP as the head element for a linked list of primes. Edit the nodes that belong in this list so that they are linked together in order.
Regard headC as the head element for a linked list of composite numbers (all those not prime). Edit the nodes that belong in this list so that they are linked together in order.
Write a program (much like the one above) that first prints out the elements in the list of primes and then prints out the elements in the list of composites. Writing a subroutine that traverses a linked list would be very useful here.
Exercise 3 - sum of elements
Copy the final program of the chapter, linked.asm. Modify it so that instead of printing the elements of the linked list it adds them all together. Upon reaching the end of the list it prints out the sum.
Exercise 4 - linear search
Copy the final program of the chapter, linked.asm. Modify it so that it does the following: The user enters an integer and then the program traverses the list looking at each node until it finds that integer. It prints out a message when it finds the integer. If it continues to the end of the list without finding the integer it prints out a failure message.
Keep doing this until the user enters a negative value to signal the end.
Linked Lists
Dynamic memory allocation is most frequently used to build data structures. The previous chapter described linked lists. This chapter shows how that idea can be implemented with dynamic memory.
Chapter Topics:
- Linked list nodes
- Allocating memory for a node
- The current node
- Creating a linked list using a loop
- Printing a linked list
Question 1
(Review:) Except for the first and last item, each data item in an ordered list has one _____ and one _____.
Answer
Except for the first item and last item, each item in the list has one successor and one predecessor. The first item in the list has one successor but no predecessor. The last itEM in the list has one predecessor but no successor.
Ordered list
Here (again) is a picture of a list of integers. This picture shows the conceptual structure of data and its relationships. In this picture, the arrows point from a node to its successor.

A linked list is one way (out of many) to implement the concept of an ordered list. A linked list is made up of nodes. Each node contains (1) data, and (2) the address of the next node.

Question 2
In the top picture of the conceptual ordered list an arrow represents the relationship between two data items.
In the bottom picture of a linked list, what does an arrow represent?
Answer
The address of the successor node.
Linked list nodes

The previous chapter implemented linked lists using static memory and symbolic addresses. For example, here is some code and a picture of what it does:
.data
elmnt01: .word 1
.word elmnt02
elmnt02: .word 2
.word 0
Each node contains an integer followed by an address.
Question 3
How many bytes are needed for each node?
Answer
8 bytes (4 bytes for the integer, 4 bytes for the address)
Allocating memory for a node

Dynamic memory can be used for a node. Here is a program that creates the two-node linked list of the picture:
First, 8 bytes are dynamically allocated for the first node. The address of the node is saved in $s1. The data, "1", is copied into the first four bytes of the node at displacement 0 off of $s1.
The process is repeated for the second node, except that its address is saved in $s2.
To complete the structure, the first node is made to point to the second node. This is what the green arrow between the nodes shows. Also, a null should be put in the pointer field of the last node. But the code is not complete.
Question 4
Fill in the blanks.
Answer

# link the first node to the second
sw $s2,4($s1) # copy address of second node
# into the first node
# put null in the link of the second node
sw $0,4($s2)
Header of linked list
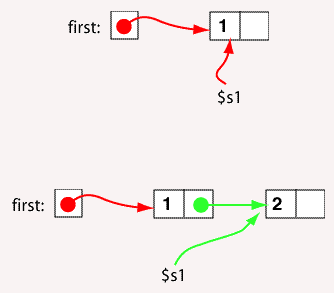
After the statements execute, the structure is complete. Memory has been laid out dynamically to implement the linked structure. In the picture the contents of $s2 and the contents of the link field of the first node contain the same address. The picture shows this as two different arrows. But both arrows are colored green to mean that they represent the same address.
The previous chapter did this in the source code by describing memory in the data section. Symbolic addresses were used to make the links:
.data
elmnt01: .word 1
.word elmnt02
elmnt02: .word 2
.word 0
Now the same structure is built dynamically. The addresses are in registers and you need to use statements to put them where you want. But the resulting structure is the same (except that it is done with different sections of memory).
Question 5
Could you copy the address of the first node to a location in the data section of memory?
Answer
Of course.
List header

When a dynamic data structure is constructed, it is common to have a field in main memory that points to the start of the structure. The picture shows this. The symbolic address first contains the address of (points to) the first node of the linked list. Sometimes a field like this is called a header to the linked list.
(Note: the first node is called the head, the field that points to it is called the header. Unfortunately people are not consistent about this.)
Now the address of the first node is contained in two places (both colored red). Here is the code that does this:

Question 6
Fill in the blanks to complete the code.
Answer
# create the first node
li $v0,9 # allocate memory
li $a0,8 # 8 bytes
syscall # $v0 <-- address
move $s1,$v0 # $s1 = &(first node)
# copy the pointer to first
sw $s1,first
# initialize the node
li $t0,1 # store 1
sw $t0,0($s1) # at displacement 0
# create the second node
. . . .
.data
first: .word 0 # address of the first node
Three node list
Now let us build a linked list with three nodes. This will be done with an eye to generalizing the procedure so that lists with any number of nodes can be built. The picture shows this.
Question 7
Why do we want to use $s1 for all nodes? Why not use a different pointer register for each node of the linked list?
Answer
You would soon run out of registers.
First node

Let us first look at creating the first node. This is the same as before:

Question 8
You've done it once. You can do it again: fill in the blanks.
Answer
main:
# create the first node
li $v0,9 # allocate memory
li $a0,8 # 8 bytes
syscall # $v0 <-- address
move $s1,$v0 # $s1 = &(first node)
# copy the pointer to first
sw $s1,first
# initialize the first node
li $t0,1 # store 1
sw $t0,0($s1) # at displacement 0
Second node
Now look at the second node. Rather than use a second register for the second node $s1 is used again:

Question 9
Fill in the blanks.
Answer
# create the second node
li $v0,9 # allocate memory
li $a0,8 # 8 bytes
syscall # $v0 <-- address
# link the second node to the first
sw $v0,4($s1) # copy address of second node
# into the first node
# make the new node the current node
move $s1,$v0 # $s1 = &(second node)
# initialize the second node
li $t0,2 # store 2
sw $t0,0($s1) # at displacement 0
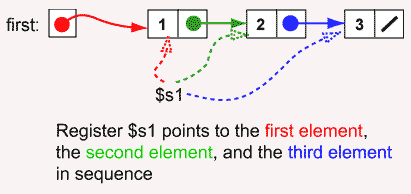
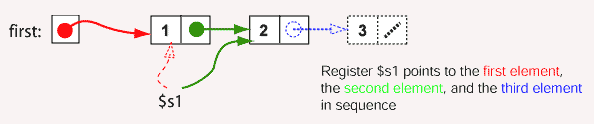
$s1 as the current node
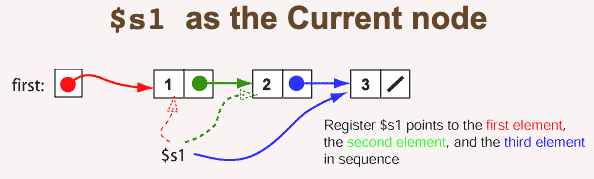
After the above code has finished, the first two nodes have been created. Register $s1 is now pointing to the second node. The first node has not been lost, because the field first points to it. When a register is used to point at the node were work is being done (as does $s1) it is sometimes called a pointer to the current node.
Now let us work on the third node. Again, $s1 is used as the pointer to the current node.
# create the third node
li $v0,9 # allocate memory
li $a0,8 # 8 bytes
syscall # $v0 <-- address
# link the third node to the second
sw $v0,4($s1) # copy address of third node
# into the second node
# make the new node the current node
move $s1,$v0 # $s1 = &(third node)
# initialize the third node
li $t0,3 # store 3
sw $t0,0($s1) # at displacement 0
# end the list
sw $0,4($s1) # put null in the link field
Linked lists can be aggravating. Look at the line of code where the current pointer is changed from the second node to the third:
# make the new node the current node
move $s1,$v0 # $s1 = &(third node)
This "change in meaning" of $s1 must be done in the correct sequence. The previous value of $s1 must already be saved in the second node.
Question 10
Register $s1 no longer points at the second node. Has the second node been lost?
Answer
No. The second node can be reached by starting at first and following the links.
Complete program
In a linked list all you need is a pointer to the head node (in our field first). Then you can follow the links from node to node to reach any node. Here is the complete program. You can run it and then look at the display of memory to see that the list has been built correctly.
# threenodeList.asm
#
.text
.globl main
main:
# create the first node
li $v0,9 # allocate memory
li $a0,8 # 8 bytes
syscall # $v0 <-- address
move $s1,$v0 # $s1 = &(first node)
# copy the pointer to first
sw $s1,first
# initialize the first node
li $t0,1 # store 1
sw $t0,0($s1) # at displacement 0
# create the second node
li $v0,9 # allocate memory
li $a0,8 # 8 bytes
syscall # $v0 <-- address
# link the second node to the first
sw $v0,4($s1) # copy address of second node
# into the first node
# make the new node the current node
move $s1,$v0 # $s1 = &(second node)
# initialize the second node
li $t0,2 # store 2
sw $t0,0($s1) # at displacement 0
# create the third node
li $v0,9 # allocate memory
li $a0,8 # 8 bytes
syscall # $v0<-- address
# link the third node to the second
sw $v0,4($s1) # copy address of third node
# into the second node
# make the new node the current node
move $s1,$v0 # $s1 = &(third node)
# initialize the third node
li $t0,3 # store 3
sw $t0,0($s1) # at displacement 0
# end the list
sw $0,4($s1) # put null in the link field
li $v0,10 # return to OS
syscall
.data
first: .word 0
Question 11
How would you create a linked list of 100 nodes?
Answer
This looks like a place for a counting loop.
Counting loop
Let us create just eight nodes. Create the first node (the head) outside of the loop so that its address can easily be copied to the field first. After doing that, the succeeding nodes are created in the loop body, one per iteration.
Here is the first part of the code:
main:
# create the first node
li $v0,9 # allocate memory
li $a0,8 # 8 bytes
syscall # $v0 <-- address
move $s1,$v0 # $s1 = &(first node)
# copy the pointer to first
sw $s1,first
# initialize the first node
li $t0,1 # store 1
sw $t0,0($s1) # at displacement 0
After doing this, the picture is:

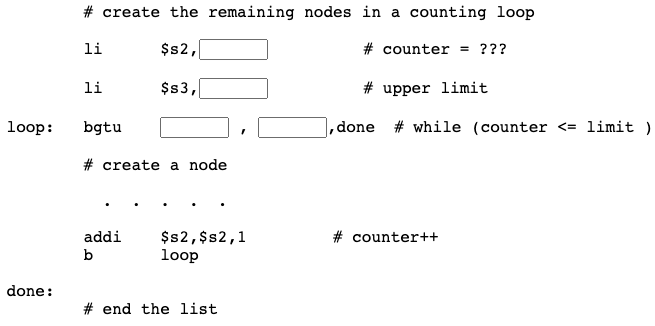
Next, concentrate on just the counting loop. All it has to do is count seven times, 2, 3, 4, ..., 7, 8 because the first node has already been created. Here is the code that does this:
Question 12
More blanks!
Answer
# create the remaining nodes in a counting loop
li $s2, 2 # counter = 2
li $s3, 8 # upper limit
loop: bgtu $s2, $s3,done # while (counter <= limit )
# create a node
. . . . .
addi $s2, $s2, 1 # counter++
b loop
done:
# end the list
First loop iteration
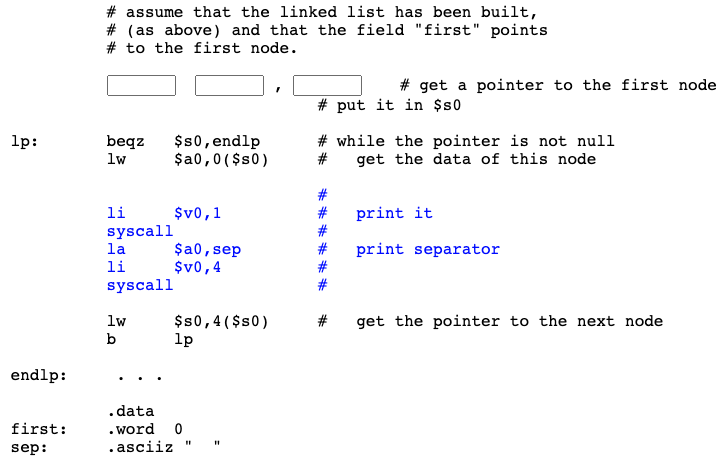
Now the loop body has been added to the code. The job of the loop body is to attach a node to the current node. The first iteration of the loop adds the second node. The first picture shows this just as the loop body starts, followed by the picture just as the loop body ends.
# On entry to the loop: $s1 points to the first node
#
loop: bgtu $s2,$s3,done # while (counter <= limit )
# create a node
li $v0,9 # allocate memory
li $a0,8 # 8 bytes
syscall # $v0 <-- address
# link this node to the previous node
# $s1 = &(previous node)
sw $v0,4($s1) # copy address of the new node
# into the previous node
# make the new node the current node
move $s1,$v0
# initialize the new node
sw $s2,0($s1) # save the counter as
# the current nodes data
addi $s2,$s2,1 # counter++
b loop
done:
Other than the fact that the code is inside a loop, this is just as before. Look at the code and the picture to see how they match.
Question 13
At the top of the loop, which is the current node?
At the bottom of the loop, which is the current node?
Answer
At the top of the loop, which is the current node? The first node.
At the bottom of the loop, which is the current node? The second node.
Third node
At the bottom of the loop, after the first iteration, the second node of the list looks just like the first node did at the top of the loop. Another iteration of the loop attaches the third node to the second node.
Linked List before the Loop

Linked List at bottom of first Loop Iteration

Linked List at bottom of second Loop Iteration

Of course, now the third node is the current node and has the same relationship to its predecessor and to $s1 as did the second node when it was the current node.
Question 14
Look at the current node (the last one) in each diagram. What does a current node look like in general?
Answer
See below.
In general ...

The general case is illustrated at right. The register $s1 points to the current node, which is already linked to its predecessor. Another iteration of the loop will attach another node at the end.
loop: bgtu $s2,$s3,done # while (counter <= limit )
# create a node
li $v0,9 # allocate memory
li $a0,8 # 8 bytes
syscall # $v0 <-- address
# link this node to the previous
# $s1 = &(previous node)
sw $v0,4($s1) # copy address of the new node
# into the previous node
# make the new node the current node
move $s1,$v0 # $s1 = &(new node)
# initialize the node
sw $s2,0($s1) # save the counter as
# the current node's data
addi $s2,$s2,1 # counter++
b loop
done:
Question 15
When the loop ends, control is passed to done. What must now be done?
Answer
A null (zero) is placed in the link field of the last node. (Actually, for SPIM, a zero is already there. But with a real OS where dynamic memory is both allocated and deallocated you must be sure to zero the link.)
done:
# end the list
sw $0,4($s1) # put null in the link field
# of the current node, which
# is the last node.
Traversomg the list
Now the linked list has been constructed. The field first points to the first node. Here is some code from the previous chapter. The code traverses a linked list, printing out the data found at each node.
Our new linked list has the same form as the previous chapter's linked list. This code will work fine.
Question 16
But, those blanks... Fill them in.
Answer
lw $s0,first # get a pointer to the first node
The field first contains the address of the first node (node). So you want to copy (load) the contents into the register.
Complete program
Here is the program, complete with a section for printing out the list.
# eightnodeList.asm
#
.text
.globl main
main:
# create the linked list
# $s1 --- current node in creation loop
# $s2 --- loop counter
# create the first node
li $v0,9 # allocate memory
li $a0,8 # 8 bytes
syscall # $v0 <-- address
move $s1,$v0 # $s1 = &(first node)
# copy the pointer to first
sw $s1,first
# initialize the first node
li $t0,1 # store 1
sw $t0,0($s1) # at displacement 0
# create the remaining nodes in a counting loop
li $s2,2 # counter = 2
li $s3,8 # upper limit
loop: bgtu $s2,$s3,done # while (counter <= limit )
# create a node
li $v0,9 # allocate memory
li $a0,8 # 8 bytes
syscall # $v0 <-- address
# link this node to the previous
# $s1 = &(previous node)
sw $v0,4($s1) # copy address of the new node
# into the previous node
# make the new node the current node
move $s1,$v0
# initialize the node
sw $s2,0($s1) # at displacement 0
addi $s2,$s2,1 # counter++
b loop
done:
# end the list
sw $0,4($s1) # put null in the link field
# of the current node, which
# is the last node.
# print out the list
# $s0 --- current node in print loop
lw $s0,first # get a pointer to the first node
lp: beqz $s0,endlp # while the pointer is not null
lw $a0,0($s0) # get the data of this node
li $v0,1 # print it
syscall #
la $a0,sep # print separator
li $v0,4 #
syscall #
lw $s0,4($s0) # get the pointer to the next node
b lp
endlp:
li $v0,10 # return to OS
syscall
.data
first: .word 0
sep: .asciiz " "
Question 17
You've run the program and it works exactly as expected. What do you do next?
Answer
Break it.
Yes. Break it into a main routine and two subroutines, create and print. Other things you can try: add several more data fields to the nodes. Modify the creation and printing routines.
Try altering the program so that each node contains a string that the user types in. To start, put the strings in a fixed-length field of each node. After that is working, further modify the program so each node is allocated only enough memory for its string and its link field. This will be really interesting.
Chapter quiz
Instructions: For each question, choose the single best answer. Make your choice by clicking on its button. You can change your answers at any time. When the quiz is graded, the correct answers will appear in the box after each question.
Question 1
Here is a description of one node of a linked list (using the language C):
struct size
{
int width;
int height;
struct size *next; // this means a pointer to
// the next node.
} ;
This describes a node that consists of two integers followed by an address.
Which of the following code fragments dynamically allocates enough memory for the node and puts its address in $s0?
(A)
li $v0,9
li $a0,12
syscall
move $s1,$v0(B)
li $v0,12
li $a0,8
syscall
move $s1,$v0(C)
li $v0,12
li $a0,8
syscall
move $v0,$s1(D)
li $v0,12
li $a0,8
syscall
move $a0,$s1
Answer
A
Question 2
Here (again) is a description of one node of a linked list:
struct size
{
int width;
int height;
struct size *next; // this means a pointer to
// the next node.
} ;
Assume that the address of a node is in $v0. Which of the following puts a width of 12 and a height of 17 into the node?
(A)
li $t0,17
sw $t0,0($v0)
li $t0,12
sw $t0,4($v0)(B)
li $t0,12
sw $t0,4($v0)
li $t0,17
sw $t0,0($v0)(C)
li $t0,12
sw $t0,0($v0)
li $t0,17
sw $t0,4($v0)(D)
li $t0,12
sw $v0,0($t0)
li $t0,17
sw $v0,4($t0)
Answer
C
Question 3
Here is a description of one node of a linked list:
struct size
{
int width;
int height;
struct size *next; // this means a pointer to
// the next node.
} ;
Assume that $s1 points at node 1 and that $s2 points at node 2. Which of the following makes node 2 the successor of node 1?
- (A)
sw $s2,4($s1) - (B)
sw $s2,8($s1) - (C)
sw $s1,0($s2) - (D)
sw $s1,4($s2)
Answer
B
Question 4
Here is a description of one node of a linked list:
struct size
{
int width;
int height;
struct size *next; // this means a pointer to
// the next node.
} ;
The field head contains the address of a linked list of such nodes. Which of the following segments visits each node of the list?
(A)
lw $s0,done
loop: beqz $s0,head
. . . # do something
lw $s0,4($s0)
b loop
done:(B)
lw $s0,head
loop: beqz $s0,done
. . . # do something
lw $s0,$s0
b loop
done:(C)
lw $s0,head
loop: beqz $s0,done
. . . # do something
lw $s0,8($s0)
b loop
done:(D)
lw $s0,head
loop: beqz $s0,done
. . . # do something
sw $s0,4($s0)
b loop
done:
Answer
C
Question 5
Here is a description of one node of a linked list:
struct size
{
int width;
int height;
struct size *next; // this means a pointer to
// the next node.
} ;
$s0 is pointing to the last node of a linked list. Which of the following code segments attaches one more node to the list and points $s0 to it?
(A)
li $v0,9
li $a0,12
syscall
sw $v0,8($s0)
move $s0,$v0(B)
li $v0,9
li $a0,12
syscall
sw $v0,8($v0)
move $s0,$v0(C)
li $v0,9
li $a0,8
syscall
sw $v0,4($v0)
move $s0,$v0(D)
li $v0,12
li $a0,8
syscall
sw $v0,8($v0)
move $s0,$v0
Answer
A
Programming exercises
NOTE: If you have read the chapters on subroutine linkage, write each exercise as a main program calling a subroutine. Use either the stack-based linkage or the frame-based linkage convention.
In the Settings menu of SPIM set Bare Machine OFF, Allow Pseudo Instructions ON, Load Trap File ON, Delayed Branches OFF, Delayed Loads OFF, Mapped IO ON, Quiet OFF.
Run the programs by clicking SimulatorGo and then OK in the pop-up panel.
Exercise 1 (**) - subroutines
Divide the last program of the chapter into three parts: a main routine, a subroutine that creates the linked list, and a subroutine that prints the linked list. Have linked list creation routine ask the user for each value that is stored in a node. The first value that the user enters is the number of nodes that will be in the list.
Exercise 2 (***) - linked list of strings
Modify the program (either the one from from the chapter or the one in Exercise 1) so that the data in each node is a null-terminated string. For this exercise, make all nodes the same size. Allow for strings of up to 16 characters (counting the null).
Put the link to the next node in the first for bytes of a node (this will make things easier later.) The user enters string data in a loop. The string "done" signals the end of input. Print out the linked list.
Exercise 3 (****) - linked list of variable-length strings
Modify the program so that each node has the link to the next node in the first four bytes, followed by a null-terminated string. Unlike the previous exercise, allocate only enough memory for each node to hold the link and the string. Read the string into a buffer, compute its length, allocate enough memory for the node, and then copy the string from the buffer to the node.
Objects
In an object oriented language, a collection of related data and subroutines are grouped together into an object. Programming is done by creating objects and invoking the objects' subroutines. (In some languages, subroutines are called methods.) This chapter is an overview of what objects look like at the implementation level.
Chapter Topics:
- Jump Table
jalrinstruction- Dynamically loaded libraries
- Objects, conceptual
- Objects, implementation
- Objects in static memory
- Objects in dynamic memory
For this chapter, in the SPIM settings menu turn load and branch delays off, turn trap file and pseudoinstructions on.
To start, let us once again look at addresses:
Question 1
Can a 32-bit word in main storage contain an address?
Answer
Of course.
Addresses in memory
An address is a 32-bit pattern, and any 32-bit word of main storage can hold it. For example, here is a fragment of a program:
.text
sub1: li $v0,4 # service code 4, print string
la $a0,messH # address of string to print
syscall # invoke the service
jr $ra # return to caller
.data
messH: .asciiz "Hello "
.text
sub2: li $v0,4 # service code 4, print string
la $a0,messW # address of string to print
syscall # invoke the service
jr $ra # return to caller
.data
messW: .asciiz "World\n"
.data
sub1add: .word sub1 # address of the first subroutine
sub2add: .word sub2 # address of the second subroutine
The symbolic address sub1 stands for whatever 32-bit address the first byte of the first subroutine gets loaded into at run time. In the .data section at the end of the program, the address represented by sub1 is stored in memory, at the symbolic address sub1add.
The source code interleaves text and data, but the assembler and loader will put all machine code into the text section of memory and all data into the data section of memory.
Question 2
If the address of sub1 is 0x00400000, what bit pattern do you expect to see in memory at the location sub1add?
Answer
0x00400000
Memory dump
Here is a display of memory showing part of the first subroutine and the start of the data section. The address of the subroutine is circled in red. The data section contains that address followed by the address of the second subroutine.
Note Carefully: The top of the picture shows the contents of the text section of memory. The contents of address 0x00400000 is the bit pattern 0x34020004.
The bottom of the picture shows the contents of the data section of memory. The contents of address 0x1000010 is the bit pattern 0x00400000.
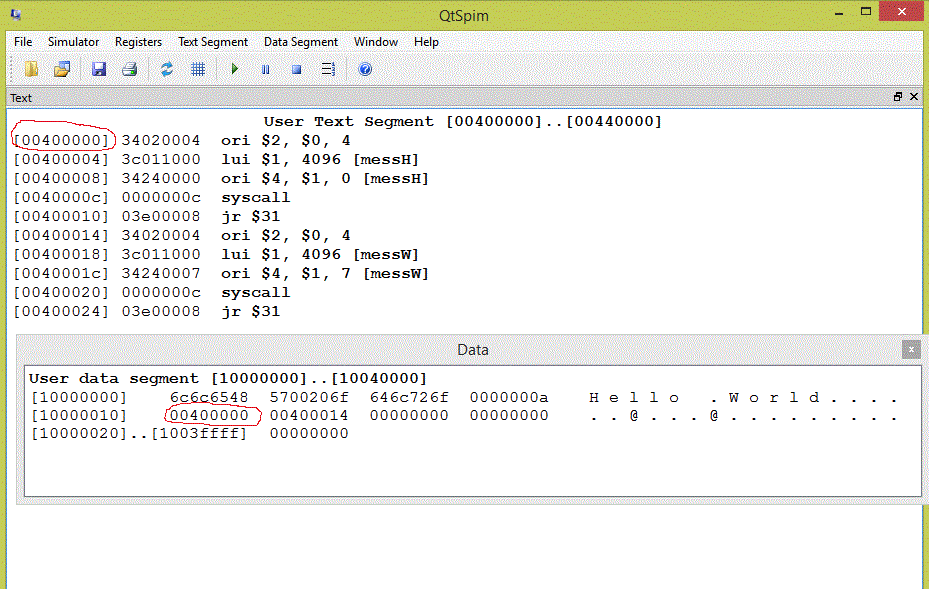
The assembler and loader put all strings in memory in the data section. Note that the strings of the subroutines are not stored with the code of the subroutines. The subroutines are put in memory in the text section.
The symbolic address sub1 stands for the value 0x00400000, the entry point of the first subroutine. This address is shown in the first red circle.
The symbolic address sub1add stands for an address in the data section. The value that is stored at that address is the value 0x00400000, the entry point of the first subroutine. This value is shown in the second red circle.
Question 3
What is the address of the second subroutine? (Hint: look at the program and at the above memory dump.)
Answer
0x00400014
Look at the data section. The second subroutine's address is stored in memory right after the first subroutine's address.
Jump table
Look again at the example program. A table of addresses of entry points is called a jump table. It is a list of locations that that control can jump to.
.text
sub1: li $v0,4
la $a0,messH
syscall
jr $ra
.data
messH: .asciiz "Hello "
.text
sub2: li $v0,4
la $a0,messW
syscall
jr $ra
.data
messW: .asciiz "World\n"
.data
sub1add: .word sub1 # Jump Table
sub2add: .word sub2
Usually there would be a main or other routine that calls the subroutines. Our example does not have this, yet.
Question 4
What is the usual instruction for passing control to a subroutine?
Answer
jal address
The jalr instruction
A specific jal instruction in a program always calls the same subroutine. For example, here is how main would usually call the first subroutine:
jal sub1
But what if you wanted the same instruction to call different subroutines depending on circumstances? This is where a jump table is useful. The table contains a list of subroutine entry points. To call a subroutine, copy its address from the table into a register. Now use the following instruction:
jalr r # $ra <— PC+4 $ra <— return address
# PC <— $r load the PC with the address in $r
This works just like the jal instruction except the address of the subroutine now comes from a register.
Question 5
Here is a section of main. Fill in the blanks so that control is passed to sub1:

Answer
.text
main:
lw $t0,sub1add # get the first entry point in the Jump Table
jalr $t0 # pass control to sub1
li $v0,10 # return to OS
syscall
.data
sub1add: .word sub1 # Jump Table
sub2add: .word sub2
Complete, impractical, program

Confusion Alert: Notice that the instruction that is used to load $t0 with the entry point to sub1 is lw $t0,sub1add. We want $t0 to get what is stored in the location sub1add, which is what a lw instruction does.
Here is the full program. main calls the two subroutines. This is a contrived example that shows a jump table and a jalr instruction. It is not a sensible way to write a "Hello World" program.
.globl main
.text
main:
lw $t0,sub1add # get first entry point
jalr $t0 # pass control
lw $t0,sub2add # get second entry point
jalr $t0 # pass control
li $v0,10 # return to OS
syscall
.data
sub1add: .word sub1 # Jump Table
sub2add: .word sub2
.text
sub1: li $v0,4
la $a0,messH
syscall
jr $ra
.data
messH: .asciiz "Hello "
.text
sub2: li $v0,4
la $a0,messW
syscall
jr $ra
.data
messW: .asciiz "World\n"
Question 6
How many bytes are in each entry in the Jump Table?
Answer
4
Dynamic jump table (simulated)
With SPIM, you write a program as one big source file. All entry points are labeled, and subroutines can be called with jal. However, large programming projects are usually written with dozens of source files which are later on assembled (or compiled) and linked together (see Chapter One.)
Operating systems often support dynamic loading, where the machine code for a subroutine is loaded only when a running program requires it. After the subroutine is loaded, its entry point is put into a jump table. A collection of machine code that can be dynamically loaded is kept in a dynamically loaded library.
Here is our example program modified to give the feel of this:
.globl main
.text
main:
. . . .
# Assume that when the program is first loaded into
# memory that the subroutines are NOT loaded with it.
# After running for a while, the program needs to
# call sub1. Only at that time is sub1 loaded and
# the first entry in the jump table is filled in.
lw $t0,jtable # call sub1
jalr $t0 # pass control
. . . .
# After running for a while longer, the program
# needs to call sub2. At that time, sub2 is loaded
# and the second entry in the jump table is filled in.
lw $t0,jtable+4 # call sub2
jalr $t0 # pass control
li $v0,10 # return to OS
syscall
.data
jtable:
.word sub1 # Jump Table (pretend that the
.word sub2 # addresses are filled in at run-time).
.globl sub1 # Pretend that this subroutine is loaded
.text # into memory only after the main routine
sub1: li $v0,4 # has started running, and that its entry
la $a0,messH # point is then filled into the jump table.
syscall
jr $ra
.data
messH: .asciiz "Hello "
.globl sub2 # The second subroutine works the same
.text # as the first.
sub2: li $v0,4
la $a0,messW
syscall
jr $ra
.data
messW: .asciiz "World\n"
Pretend that at first only main and its jump table are loaded into memory, and that the jump table is full of zeros. Then, later on, the program needs to call the first subroutine. At that time, the operating system pauses the program, loads the needed subroutine, and fills in its part of the jump table. The program then resumes running.
Now the only way to call the subroutine is through the jump table. The instruction
lw $t0,jtable # call sub1
loads the first address of the jump table into $t0. Then the jalr instruction calls it.
Later on the process is repeated with the second subroutine. The instruction
lw $t0,jtable+4 # call sub2
loads the second address of the jump table into $t0. The jtable+4 means to use the address that is four bytes away from the symbolic address jtable.
Question 7
Could several running programs share the same dynamic library?
Answer
Yes
Dynamic load libraries
With a dynamic load library, a subroutine is loaded from the library into main memory only when it is needed by a program running on the computer system. Several programs might share the same subroutine by having its entry point in their jump tables. By sharing subroutines, programs can share and coordinate system resources. For example, nearly all programs interact with the user by using the resources of the windowing system. The windowing system is managed through dynamically loaded subroutines that are shared by the programs.
If you followed the above discussion you will have (I hope) a better idea of how this works. The idea has been around since about the middle nineteen sixties.
Object oriented programming has recently become very popular.
Question 8
(Review of OOP: ) What is an object?
Answer
An object is a section of main memory that contains both data and methods and that behaves like an individual entity.
Objects
Objects are often described as follows:
- An object has identity (it acts as a single whole).
- An object has state (it has various properties, which might change).
- An object has behavior (it can do things and can have things done to it).
It is useful (but not quite accurate) to think of an object as a contiguous chunk of memory that contains both data and machine code, as in the picture.
Of course, general purpose memory (symbolized by the yellow bricks in the picture) can hold both data and machine code. So an object can be built out of general purpose memory.
In object oriented programming, a subroutine of an object is often called a method of the object. So an object consists of data and methods.
Question 9
If a program constructed 1000 objects, would it be efficient to make 1000 copies of the machine code for each object?
Answer
No.
Objects as implemented

Rather than make many copies of the same machine code, the run-time system makes one copy of the code for each type of object.
When an object is constructed, it gets space for its own data (which is unique to itself) and a jump table filled with addresses of its subroutines (which are common to all objects of that type.) The new picture shows an object as implemented in this manner.
Of course, there are many details left out of this discussion.
Question 10
Does an object as implemented consist of one contiguous block of memory?
Answer
No. The machine code for all objects of the same type are shared, and not part of any one object.
However, when thinking about objects, when coding in an object oriented language, it is best to think of an object as one "thing" consisting of all of its parts.
Example program

Let's write an example program that contains two objects. Conceptually, each object consists of a text message and a print() method that prints the message. In implementation, the code for the method will be outside of the object. The picture shows the program conceptually.
The main() routine holds the address of each object. This is symbolized by the arrows that point to each object. The program will first call the print() method of the first object, and then call the print() method of the second object.
This part of the code is shown using Java syntax:
object1.print();
object2.print();
Question 11
What output do you expect from this program?
Answer
Hello World
Silly Example
Static objects
In Java, objects are constructed from dynamic memory. To simplify the discussion (and the code) let us use static memory for our objects. The following program uses two objects in static memory declared in a source file:
.globl main
.text
main: # object1.print();
la $a0,object1 # get address of first object
lw $t0,0($a0) # get address of object's method
jalr $t0 # call the object's method
# object2.print();
la $a0,object2 # get address of second object
lw $t0,0($a0) # get address of object's method
jalr $t0 # call the object's method
li $v0,10 # return to OS
syscall
# code for print method
. . .
.data
object1: .word print # Jump Table
.asciiz "Hello World\n" # object data
object2: .word print # Jump Table
.asciiz "Silly Example\n" # object's data
Each object looks like this:
byte 0-3: address of a method # single-entry jump table
byte 4- : null terminated string # as many bytes as needed
The jump table consists of one address, the entry point of print(), at the start of the object. To copy this address from object1 to $t0, the following code is used:
la $a0,object1 # get address of first object
lw $t0,0($a0) # get address of object's method
Now that the entry point is in $t0 object1's method can be called.
Question 12
What instruction is used to call object1's method?
Answer
jalr $t0 # call the object's method
Implementation of an object
After the object's print method has run, control returns to the instruction after the jalr (if delays are set to off in SPIM).
Now look at the implementation of object1. It follows this plan:
byte 0-3: address of print() # single-entry jump table
byte 4- : null terminated string # as many bytes as needed
Here is the actual code:
.data
object1:
.word print # Jump Table
.asciiz "Hello World\n" # This object's data
In a larger object there would be more entries in the jump table.
Question 13
Complete the declaration for object2:
object2:
.word ______ # Jump Table
.asciiz ______ # This object's data
Answer
object2:
.word print # Jump Table
.asciiz "Silly Example\n" # This object's data
The print() method
The print() method is put in the .text section of memory:
# Single copy of the print method
# Parameter: $a0 == address of the object
.text
print:
li $v0,4 # print string service
addu $a0,$a0,4 # address of object's string
syscall #
jr $ra # return to caller
There is only one copy of this method. But it is supposed to act as if were a part of each object. This is done by copying into $a0 the address of the object using print. Here is how main() does this:
# object1.print();
la $a0,object1 # Get address of first object.
lw $t0,0($a0) # Get address of object's method.
jalr $t0 # Call the object's method.
# The address of the object is
# in $a0.
In print(), the address of the string within the object that is using print() is computed by:
addu $a0,$a0,4 # address of object's string
This places the string's address in $a0 where the print string service expects it.
Question 14
(Thought Question:) In a real-world program, should a subroutine calling convention be used when object methods are called?
Answer
Yes.
Complete OOP program
The methods (subroutines) of objects in actual programs would be called using a stack-based linkage convention. Local variables of methods would be locations in a stack frame that is pushed onto the run-time stack with each method activation. Parameters would be passed to methods and values returned to the caller as described by the convention. But let us avoid these complications.
Here is the complete program. If you copy it to a file and compile and run it, your understanding of object oriented programming will greatly increase.
.globl main
.text
main: # object1.print();
la $a0,object1 # get address of first object
lw $t0,0($a0) # get address of object's method
jalr $t0 # call the object's method
# object2.print();
la $a0,object2 # get address of second object
lw $t0,0($a0) # get address of object's method
jalr $t0 # call the object's method
li $v0,10 # return to OS
syscall
# Objects constructed in static memory. An object consists of the data
# for each object and a jump table of entry points common to all objects
# of its type.
.data
object1:
.word print # Jump Table
.asciiz "Hello World\n" # This object's data
object2:
.word print # Jump Table
.asciiz "Silly Example\n" # This object's data
# Single copy of the print method
# Parameter: $a0 == address of the object
.text
print:
li $v0,4 # print string service
addu $a0,$a0,4 # address of object's string
syscall #
jr $ra
Question 15
(Thought Question:) What two things would have to be done to add a second method to the objects of this program?
Answer
- Add an entry to the jump table of each object.
- Add the code for the method to the program.
Since the layout of the object has changed, some other small changes also need to be made.
cancel() method
Let us add the cancel() method to the objects. This (somewhat silly) method replaces all the characters of an object's string with x's.
Here is the new design for an object:
# jump table:
byte 0-3: address of print() # first entry point
byte 4-7: address of cancel() # second entry point
# data:
byte 4- : null terminated string # as many bytes as needed
Question 16
Complete the declaration for object1::
object1:
.word _____ # entry point for print
.word _____ # entry point for cancel
.asciiz _____ # string data
Answer
object1:
.word print # entry point for print
.word cancel # entry point for cancel
.asciiz "Hello World" # string data
Behavior of object's methods
The cancel() method must affect only the data of the object it is called with. Here is a hypothetical program written in an object oriented language:
object1.print();
object1.cancel();
object1.print();
object2.print();
The first activation of print() causes it to work with the data of object1. Then, The activation of cancel() causes it to alter just that data. Next, The second activation of print() causes it to print the altered data of object1. The data of object2 has not been affected by all this:
Hello World
xxxxxxxxxxx
Silly Example
Question 17
(Review:) How does a method access the data of an object?
Answer
When a method is called, it is given the address of the object.
Implementatin of cancel()
Here is cancel(). The details are not important except for the beginning where access to the object's data is done by using the address in $a0.
# cancel() method
# Parameter: $a0 == address of the object
#
# Registers:
# $t0 == address of the char in the string
# $t1 == char from the string
# $t2 == 'x'
.text
cancel:
addiu $t0,$a0,8 # the string starts 8 bytes
# from the start of the object
li $t2,'x' # replacement character
lb $t1,0($t0) # get first ch of string
loop: beqz $t1,done # while ( ch != '\0' )
sb $t2,0($t0) # replace ch with 'x'
addiu $t0,$t0,1 #
lb $t1,0($t0) # get next ch
b loop # end while
done:
jr $ra # return to caller
Question 18
Do the object's methods know how many objects have been declared in the program?
Answer
No.
Complete program
Here is the complete, revised program. You may wish to play with it.
.globl main
.text
main: # object1.print();
la $a0,object1 # get address of first object
lw $t0,0($a0) # get address of print method
jalr $t0 # call the method
# object1.cancel();
la $a0,object1 # get address of first object
lw $t0,4($a0) # get address of cancel method
jalr $t0 # call the method
# object1.print();
la $a0,object1 # get address of first object
lw $t0,0($a0) # get address of print method
jalr $t0 # call the method
# object2.print();
la $a0,object2 # get address of second object
lw $t0,0($a0) # get address of object's method
jalr $t0 # call the object's method
li $v0,10 # return to OS
syscall
# Objects constructed in static memory.
# The implementation of an object consists of the data for each object
# and a jump table of entry points common to all objects
# of this type.
.data
object1:
.word print # Jump Table
.word cancel
.asciiz "Hello World\n" # This object's data
object2:
.word print # Jump Table
.word cancel
.asciiz "Silly Example\n" # This object's data
# print() method
# Parameter: $a0 == address of the object
.text
print:
li $v0,4 # print string service
addiu $a0,$a0,8 # address of object's string
syscall #
jr $ra
# cancel() method
# Parameter: $a0 == address of the object
#
# Registers:
# $t0 == address of the char in the string
# $t1 == char from the string
# $t2 == 'x'
.text
cancel:
addiu $t0,$a0,8 # the string starts 8 bytes
# from the start of the object
li $t2,'x' # replacement character
lb $t1,0($t0) # get first ch of string
loop: beqz $t1,done # while ( ch != '\0' )
sb $t2,0($t0) # replace ch with 'x'
addiu $t0,$t0,1 #
lb $t1,0($t0) # get next ch
b loop # end while
done:
jr $ra # return to caller
Question 19
While a program is running, can an object be created out of dynamic memory?
Answer
Of course. This is how Java, for instance, usually constructs objects.
Dynamic objects
Let us write an assembly language program that is roughly equivalent to the following program in a Java-like language:
begin
object1 = new object();
object1.read();
object1.print();
end;
The assembly program we will write will be similar to what a compiler might output if it compiled the Java-like program into MIPS assembly. For a compiler, the definition of an object and its methods is contained in another file (for java, in a class file).
Let us redesign our objects.
byte 0- 3: address of print() # jump table
byte 4- 7: address of read()
byte 8-31: null terminated string # 24 bytes (fixed size)
To simplify things, our objects have a fixed size.
Question 20
Do objects in real programs have a fixed size?
Answer
Usually not.
Allocating memory for an object
Object one is built out of dynamically allocated memory. Here is the start of the program that allocates the memory for one object. The address of the newly allocated memory is saved at object1. (this is roughly equivalent to a reference variable in Java.)
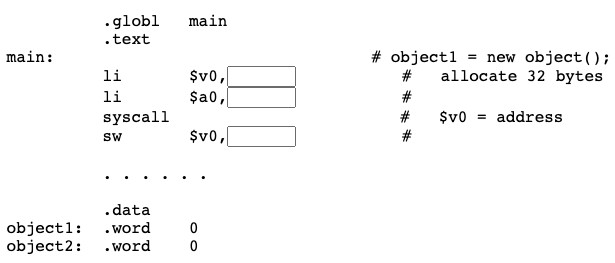
Question 21
Fill in the blanks. (Hint: the code for the dynamic memory allocation service is 9).
Answer
.globl main
.text
main: # object1 = new object();
li $v0,9 # allocate 32 bytes
li $a0,32 #
syscall # $v0 = address
sw $v0,object1 #
. . . . . .
.data
object1: .word 0
object2: .word 0
The code allocates memory for the object and saves its address.
Initializing the object
Next, the newly allocated memory must be initialized (in an object-oriented language this would be done by the object constructor). Here, again, is the layout of the object:
byte 0- 3: address of print() # jump table
byte 4- 7: address of read()
byte 8-31: null terminated string # 24 bytes (fixed size)
Here is the code that initializes the object. Register $v0 contains the address of the object.
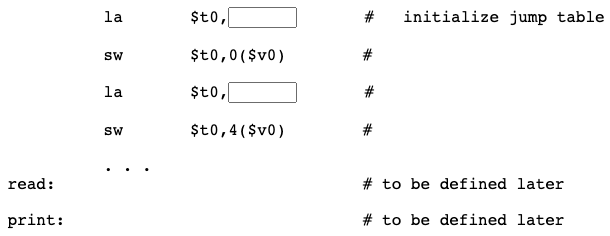
Assume that the entry point for the read() is given by symbolic address read, and that the entry point for the print() is given by symbolic address print.
Question 22
Fill in the blanks.
Answer
la $t0,print # initialize jump table
sw $t0,0($v0) #
la $t0,read #
sw $t0,4($v0) #
The la is the correct one to use because we need the address that print stands for, not the contents of that location.
Calling the methods
After constructing the object, the program invokes each method of the object and then ends.

Question 23
Fill in the blanks.
Answer
See below.
Complete main
Here is the complete main().
.globl main
.text
main: # object1 = new object();
li $v0,9 # allocate 32 bytes
li $a0,32 #
syscall # $v0 = address
sw $v0,object1 #
la $t0,print # initialize jump table
sw $t0,0($v0) #
la $t0,read #
sw $t0,4($v0) #
# object1.read();
lw $a0,object1 # get address of object1
lw $t0,4($a0) # get address of read method
jalr $t0 # call the method
# object1.print();
lw $a0,object1 # get address of first object
lw $t0,0($a0) # get address of print method
jalr $t0 # call the method
li $v0,10 # return to OS
syscall
.data
object1: .word 0
object2: .word 0
The program needs the code for the print() and the read() method.
Question 24
Where would a compiler of an OO language find the code for the methods?
Answer
In a file that defines the object. In Java, this would be a class file. (Or, a source file written in Java that is compiled into a class file.)
Method definitions
We will not copy method definitions from a separate file but will include them in the program. Here is the code for the print() method:
# print() method
# Parameter: $a0 == address of the object
.text
print:
li $v0,4 # print string service
addiu $a0,$a0,8 # address of object's string
syscall #
jr $ra
Question 25
Is this print() method for our dynamically-allocated object the same as for the static objects?
Answer
Yes. It makes no difference where the memory for the object came from.
Read method
The read() method, like the print() method, is called with the address of the object in $a0 as a parameter. Since $a0 is needed by syscall, its value must be saved on entry to the method.
Later in the code the base address of the object is used to calculate the location of the string in the object. The jump table has two 4-byte addresses in it, so 8 is added to the base address.
# read() method
# Parameter: $a0 == address of the object
#
.text
read:
move $s1,$a0 # save object's address
li $v0,4 # print string service
la $a0,prompt # address of object's string
syscall #
addiu $a0,$s1,8 # $a0 = address of buffer
# in object
li $a1,24 # $a1 = size of buffer
li $v0,8 # read string service
syscall
jr $ra # return to caller
.data
prompt: .asciiz "enter data > "
Our objects are fixed-sized, with a 24 byte buffer. The read string service is given the buffer size as one of its parameters.
Question 26
Say that you wanted the objects to hold strings of any size. How could this be done? (Hint: think about the previous chapter.)
Answer
The object could contain a header to a linked list of sub-strings. The linked list could grow to contain a string of any size.
Complete dynamic OO program
Here is the complete program, available for play.
.globl main
.text
main: # object1 = new object();
li $v0,9 # allocate 32 bytes
li $a0,32 #
syscall # $v0 = address
sw $v0,object1 #
la $t0,print # initialize jump table
sw $t0,0($v0) #
la $t0,read #
sw $t0,4($v0) #
# object1.read();
lw $a0,object1 # get address of object1
lw $t0,4($a0) # get address of read method
jalr $t0 # call the method
# object1.print();
lw $a0,object1 # get address of first object
lw $t0,0($a0) # get address of print method
jalr $t0 # call the method
li $v0,10 # return to OS
syscall
.data
object1: .word 0
object2: .word 0
# print() method
# Parameter: $a0 == address of the object
.text
print:
li $v0,4 # print string service
addiu $a0,$a0,8 # address of object's string
syscall #
jr $ra
# read() method
# Parameter: $a0 == address of the object
#
.text
read:
move $s1,$a0 # save object's address
li $v0,4 # print string service
la $a0,prompt # address of object's string
syscall #
addiu $a0,$s1,8 # $a0 = address of buffer
# in object
li $a1,24 # $a1 = size of buffer
li $v0,8 # read string service
syscall
jr $ra # return to caller
.data
prompt: .asciiz "enter data > "
Question 27
Does a true object oriented language have more features than the ones covered in this chapter?
Answer
Yes, many more. But all can be implemented on any general purpose computer.
Chapter quiz
Instructions: For each question, choose the single best answer. Make your choice by clicking on its button. You can change your answers at any time. When the quiz is graded, the correct answers will appear in the box after each question.
Question 1
What is the name for a list of entry points used to call subroutines?
- (A) call table
- (B) entry table
- (C) call list
- (D) jump table
Answer
D
Question 2
Here is a list of five entry points.
jtab: .word sub0
.word sub1
.word sub2
.word sub3
.word sub4
Which of the following sequences calls sub3?
(A)
lw $t1,jtab+3
jalr $t1(B)
lw $t1,jtab+12
jalr $t1(C)
jal jtab+3(D)
jal jtab+12
Answer
B
Question 3
Where does the instruction jalr $t0 put the return address?
- (A)
$t0 - (B)
$sp - (C)
$ra - (D)
$jr
Answer
C
Question 4
What is it called when the machine code for a subroutine is loaded only when a running program requires it?
- (A) run time loading
- (B) linking
- (C) library loading
- (D) dynamic loading
Answer
D
Question 5
Does each software object of an executing program need a copy of its methods.
- (A) No — all objects of any type can use any method in the system.
- (B) No — all objects of the same type can share the code for their methods.
- (C) Yes — to enforce modularity each object has its own copy of each method.
- (D) Yes — in order to access the data of an object, the code must be part of it.
Answer
B
Question 6
What is a DISadvantage when running programs share subroutines?
- (A) The subroutines need to be written only once.
- (B) The sizes of the programs is reduced.
- (C) Calling a subroutine is more complicated.
- (D) System resources managed by the subroutines can be effectively coordinated.
Answer
C
Question 7
What are the characteristics of a software object?
- (A) A software object has identity, state, and behavior.
- (B) A software object is any block of main memory.
- (C) A software object has variables, values, and entry points.
- (D) A software object has data and methods to initialize the data.
Answer
A
Question 8
Here is an object constructed in static memory:
.data
object: .word print # methods
.word read
.word clear
.word 0 # data
.word 7
Which of the following invokes the read method of the object? (Assume that the method expects the address of the object in $a0.)
(A)
la $a0,object
lw $t0,0($a0)
jalr $t0(B)
la $a0,object
lw $t0,4($a0)
jalr $t0(C)
la $a0,object
lw $t0,1($a0)
jr $t0(D)
lw $a0,object
lw $t0,8($a0)
jr $t0
Answer
B
Question 9
Here is an object constructed in static memory:
.data
object: .word print # methods
.word read
.word clear
.word 0 # data
.word 7
Which of the following implements the clear method of the object? The method clears the second word of data to zero. (Assume that the method expects the address of the object in $a0.)
(A)
clear: sw $0,4($a0)
jr $ra(B)
clear: lw $t1,8($a0)
jalr $t1
jr $ra(C)
clear: lw $t1,8($a0)
sw $t1,16($a0)
jr $ra(D)
clear: sw $0,16($a0)
jr $ra
Answer
D
Question 10
If a program is changed so that one new method is added to an object type, how much larger does each object of that type become?
- (A) Larger by as many bytes as it takes for the code of the new method.
- (B) 0 bytes
- (C) 4 bytes
- (D) This is impossible to estimate.
Answer
C
Programming exercises
In the Settings menu of SPIM set Bare Machine OFF, Allow Pseudo Instructions ON, Load Trap File ON, Delayed Branches OFF, Delayed Loads OFF, Mapped IO ON, Quiet OFF.
Run the programs by clicking SimulatorGo and then OK in the pop-up panel.
Exercise 1 (*) - jump table
Add a third subroutine that prints "Wonderful" to the Full, Impractical, Program of the chapter (ass36_6.html). Add an entry to the jump table and a call to the new subroutine to the main routine of the program.
Exercise 2 (*) - jump table with loop
Add several more subroutines that print out various words to the Full, Impractical, Program of the chapter. Put each new entry point into the jump table. Write a loop in the main program so that the entry points in the jump table are invoked in order, one per loop iteration.
Exercise 3 (*) - static objects
Add several additional objects to the Complete Program of ass36_19.html. Modify the main program so that it exercises several of the methods of the objects.
Exercise 4 (*) - more methods with static objects
Add two methods to the Complete Program> (above). Add a clear() method that makes the first byte of an objects string the null byte (in effect deleting the string). Add a capitalize() method that changes each lower case character of the object's string to a capital letter. Do this by adding 0x20 to each lower case letter. Modify main to test the new methods.
Exercise 5 (**) - dynamic objects
Design an object that has an integer for its data. Its methods are set(), double(), and print(). The set() method is passed a parameter in $a0 and sets the object's data to that value. The double() method doubles an object's integer, and the print() method prints out the integer.
Write a main routine that creates several objects and tests their methods.