Array and String Manipulation
Readings
Array
Quick Reference
Other names: static array
Description: Stores things in order. Has quick lookups by index. An array organizes items sequentially, one after another in memory. Each position in the array has an index, starting at 0.
Visual description:
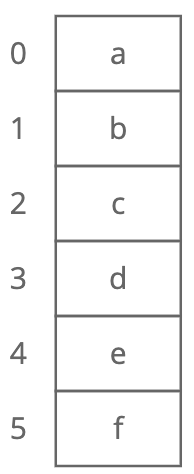
Strengths:
- Fast lookups: Retrieving the element at a given index takes time, regardless of the length of the array.
- Fast appends: Adding a new element at the end of the array takes time, if the array has space.
Weaknesses:
- Fixed size: You need to specify how many elements you're going to store in your array ahead of time. (Unless you're using a dynamic array.)
- Costly inserts and deletes: You have to "scoot over" the other elements to fill in or close gaps, which takes worst-case time.
Worst Case Analysis:
| Context | Big O |
|---|---|
| space | |
| lookup | |
| append | |
| insert | |
| delete |
In JavaScript
Some languages (including Javascript) don't have these bare-bones arrays. Here's what arrays look like in Java.
// instantiate an array that holds 10 integers
int gasPrices[] = new int[10];
gasPrices[0] = 346;
gasPrices[1] = 360;
gasPrices[2] = 354;
Inserting
If we want to insert something into an array, first we have to make space by "scooting over" everything starting at the index we're inserting into:
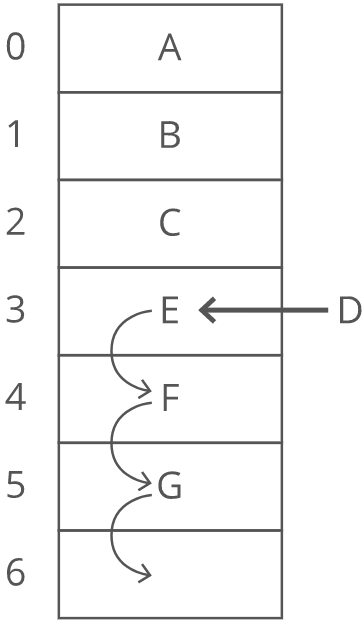
In the worst case we're inserting into the 0th index in the array (prepending), so we have to "scoot over" everything in the array. That's time.
Deleting
Array elements are stored adjacent to each other. So when we remove an element, we have to fill in the gap—-"scooting over" all the elements that were after it:
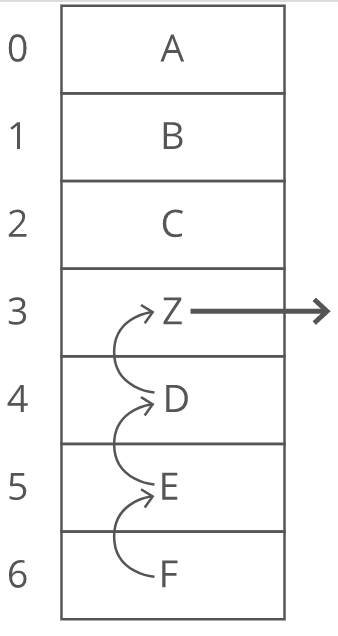
In the worst case we're deleting the 0th item in the array, so we have to "scoot over" everything else in the array. That's time. Why not just leave the gap? Because the quick lookup power of arrays depends on everything being sequential and uninterrupted. This lets us predict exactly how far from the start of the array the 138th or 9,203rd item is. If there are gaps, we can no longer predict exactly where each array item will be.
Data structures built on arrays
Arrays are the building blocks for lots of other, more complex data structures. Don't want to specify the size of your array ahead of time? One option: use a dynamic array. Want to look up items by something other than an index? Use an object.
Array Slicing
Array slicing involves taking a subset from an array and allocating a new array with those elements. In JavaScript you can create a new array of the elements in myArray, from startIndex to endIndex (exclusive), like this:
myArray.slice(startIndex, endIndex);
You can also get everything from startIndex onwards by just omitting endIndex:
myArray.slice(startIndex);
Note: There's a hidden time and space cost here! It's tempting to think of slicing as just "getting elements," but in reality you are:
- allocating a new array
- copying the elements from the original array to the new array
This takes time and space, where is the number of elements in the resulting array. That's a bit easier to see when you save the result of the slice to a variable:
const tailOfArray = myArray.slice(1);
But a bit harder to see when you don't save the result of the slice to a variable:
return myArray.slice(1);
// Whoops, I just spent O(n) time and space!
myArray.slice(1).forEach(item => {
// Whoops, I just spent O(n) time and space!
});
So keep an eye out. Slice wisely.
In-Place Algorithms
An in-place function modifies data structures or objects outside of its own stack frame (i.e., stored on the process heap or in the stack frame of a calling function). Because of this, the changes made by the function remain after the call completes.
Stack frame
Overview:
The call stack is what a program uses to keep track of function calls. The call stack is made up of stack frames—-one for each function call.
For instance, say we called a function that rolled two dice and printed the sum (the code here is in Python 2.7):
def roll_die():
return random.randint(1, 6)
def roll_two_and_sum():
total = 0
total += roll_die()
total += roll_die()
print total
roll_two_and_sum()
First, our program calls rollTwoAndSum(). It goes on the call stack:
rollTwoAndSum()
That function calls rollDie(), which gets pushed on to the top of the call stack:
rollDie()
rollTwoAndSum()
Inside of rollDie(), we call random.randint(). Here's what our call stack looks like then:
random.randint()
rollDie()
rollTwoAndSum()
When random.randint() finishes, we return back to rollDie() by removing ("popping") random.randint()'s stack frame.
rollDie()
rollTwoAndSum()
Same thing when rollDie() returns:
rollTwoAndSum()
We're not done yet! rollTwoAndSum() calls rollDie() again:
rollDie()
rollTwoAndSum()
Which calls random.randint() again:
random.randint()
rollDie()
rollTwoAndSum()
random.randint() returns, then rollDie() returns, putting us back in rollTwoAndSum():
rollTwoAndSum()
Which calls print():
print()
rollTwoAndSum()
What's stored in a stack frame?
What actually goes in a function's stack frame? A stack frame usually stores the following:
- Local variables
- Arguments passed into the function
- Information about the caller's stack frame
- The return address--what the program should do after the function returns (i.e., where it should "return to"). This is usually somewhere in the middle of the caller's code.
Some of the specifics vary between processor architectures. For instance, AMD64 (64-bit x86) processors pass some arguments in registers and some on the call stack. And, ARM processors (common in phones) store the return address in a special register instead of putting it on the call stack.
The space cost of stack frames
Each function call creates its own stack frame, taking up space on the call stack. That's important because it can impact the space complexity of an algorithm. Especially when we use recursion. For example, if we wanted to multiply all the numbers between and , we could use this recursive approach:
function product1ToN(n) {
// We assume n >= 1
return (n > 1) ? (n * product1ToN(n-1)) : 1;
}
What would the call stack look like when n = 10?
First, product1ToN() gets called with n = 10:
product1ToN() // n = 10
This calls product1ToN() with n = 9:
product1ToN() // n = 9
product1ToN() // n = 10
Which calls product1ToN() with n = 8.
product1ToN() // n = 8
product1ToN() // n = 9
product1ToN() // n = 10
And so on until we get to n = 1.
product1ToN() // n = 1
product1ToN() // n = 2
product1ToN() // n = 3
product1ToN() // n = 4
product1ToN() // n = 5
product1ToN() // n = 6
product1ToN() // n = 7
product1ToN() // n = 8
product1ToN() // n = 9
product1ToN() // n = 10
Look at the size of all those stack frames! The entire call stack takes up space. That's right--we have an space cost even though our function itself doesn't create any data structures!
What if we had used an iterative approach instead of a recursive one?
function product1ToN(n) {
// We assume n >= 1
let result = 1;
for (let num = 1; num <= n; num++) {
result *= num;
}
return result;
}
This version takes a constant amount of space. At the beginning of the loop, the call stack looks like this:
product1ToN() // n = 10, result = 1, num = 1
As we iterate through the loop, the local variables change, but we stay in the same stack frame because we don't call any other functions.
product1ToN() // n = 10, result = 2, num = 2
product1ToN() // n = 10, result = 6, num = 3
product1ToN() // n = 10, result = 24, num = 4
In general, even though the compiler or interpreter will take care of managing the call stack for you, it's important to consider the depth of the call stack when analyzing the space complexity of an algorithm. Be especially careful with recursive functions! They can end up building huge call stacks.
What happens if we run out of space? It's a stack overflow! In JavaScript, you'll get a RangeError. If the very last thing a function does is call another function, then its stack frame might not be needed any more. The function could free up its stack frame before doing its final call, saving space. This is called tail call optimization (TCO). If a recursive function is optimized with TCO, then it may not end up with a big call stack. In general, most languages don't provide TCO. Scheme is one of the few languages that guarantee tail call optimization. Some Ruby, C, and Javascript implementations may do it. Python and Java decidedly don't.
In-place algorithms are sometimes called destructive, since the original input is "destroyed" (or modified) during the function call.
Note: "In-place" does not mean "without creating any additional variables!" Rather, it means "without creating a new copy of the input." In general, an in-place function will only create additional variables that are space.
An out-of-place function doesn't make any changes that are visible to other functions. Usually, those functions copy any data structures or objects before manipulating and changing them.
IMPORTANT: In many languages, primitive values (integers, floating point numbers, or characters) are copied when passed as arguments, and more complex data structures (arrays, heaps, or hash tables) are passed by reference. This is what Javascript does.
Here are two functions that do the same operation on an array, except one is in-place and the other is out-of-place:
function squareArrayInPlace(intArray) {
intArray.forEach((int, index) => {
intArray[index] *= int;
});
// NOTE: no need to return anything - we modified
// intArray in place
}
function squareArrayOutOfPlace(intArray) {
// We allocate a new array that we'll fill in with the new values
const squaredArray = [];
intArray.forEach((int, index) => {
squaredArray[index] = Math.pow(int, 2);
});
return squaredArray;
}
To drive this point home further, consider the following example:
const myPrimitive = 7;
function changeSomePrimitive(primitive) {
primitive += 1
}
changeSomePrimitive(myPrimitive)
console.log(myPrimitive); // 7
Why didn't myPrimitive change? Because it's a primitive in JavaScript so when it gets passed to changeSomePrimitive, the argument is first copied and then that copy is changed. To clearly see the difference when an argument is passed by reference, consider the following example that closely mirrors the example above except where a non-primitive value is passed to the function instead:
const myNonPrimitive = [7];
function changeSomeNonPrimitive(nonPrimitive) {
nonPrimitive[0] += 1
}
changeSomeNonPrimitive(myNonPrimitive)
console.log(myNonPrimitive); // [ 8 ]
Side effects: Working in-place is a good way to save time and space. An in-place algorithm avoids the cost of initializing or copying data structures, and it usually has an space cost. But be careful: an in-place algorithm can cause side effects. Your input is "destroyed" or "altered," which can affect code outside of your function.
For example:
const originalArray = [2, 3, 4, 5];
squareArrayInPlace(originalArray);
console.log('original array: ' + originalArray);
// Logs: original array: 4,9,16,25 - confusingly!
Generally, out-of-place algorithms are considered safer because they avoid side effects. You should only use an in-place algorithm if you're space constrained or you're positive you don't need the original input anymore, even for debugging.
Dynamic Array
Quick Reference
Other names: array list, growable array, resizable array, mutable array
Description: An array that automatically grows as you add more items. A dynamic array is an array with a big improvement: automatic resizing. One limitation of arrays is that they're fixed size, meaning you need to specify the number of elements your array will hold ahead of time. A dynamic array expands as you add more elements. So you don't need to determine the size ahead of time.
Visual description:
Strengths:
- Fast lookups: Just like arrays, retrieving the element at a given index takes time.
- Variable size: You can add as many items as you want, and the dynamic array will expand to hold them.
- Cache-friendly: Just like arrays, dynamic arrays place items right next to each other in memory, making efficient use of caches.
Weaknesses:
- Slow worst-case appends: Usually, adding a new element at the end of the dynamic array takes time. But if the dynamic array doesn't have any room for the new item, it'll need to expand, which takes time.
- Costly inserts and deletes: Just like arrays, elements are stored adjacent to each other. So adding or removing an item in the middle of the array requires "scooting over" other elements, which takes time.
Worst Case Analysis:
| Context | Big O |
|---|---|
| space | |
| lookup | |
| append | |
| insert | |
| delete |
Average Case Analysis:
| Context | Big O |
|---|---|
| space | |
| lookup | |
| append | |
| insert | |
| delete |
In JavaScript
Confusingly, in JavaScript, dynamic arrays are just called arrays. Here's what they look like:
const gasPrices = [];
gasPrices[0] = 346;
gasPrices[1] = 360;
gasPrices[2] = 354;
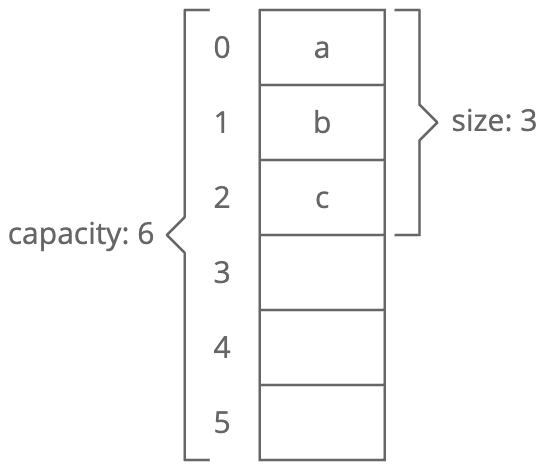
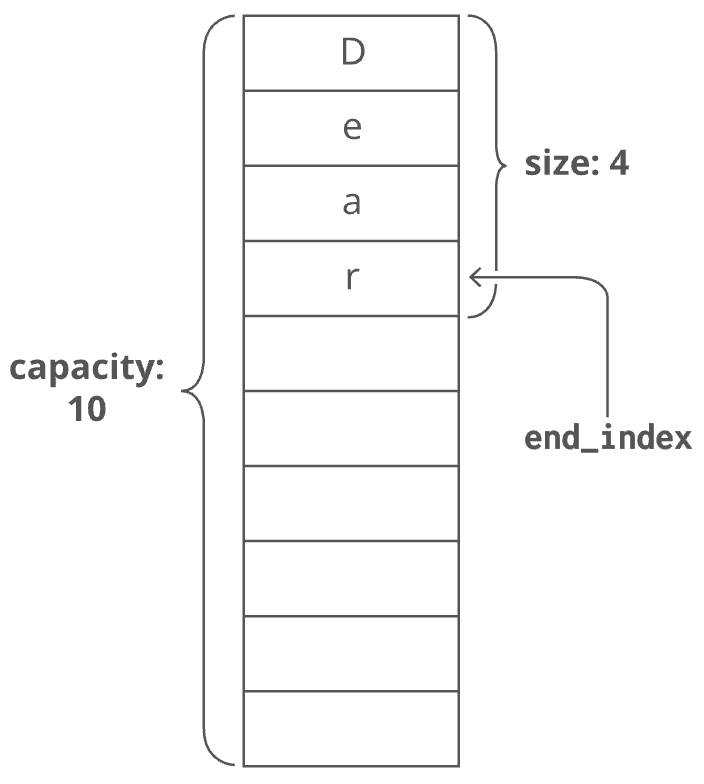
Size vs. Capacity
When you allocate a dynamic array, your dynamic array implementation makes an underlying fixed-size array. The starting size depends on the implementation—-let's say our implementation uses 10 indices. Now say we append 4 items to our dynamic array. At this point, our dynamic array has a length of 4. But the underlying array has a length of 10. We'd say this dynamic array's size is 4 and its capacity is 10. The dynamic array stores an endIndex to keep track of where the dynamic array ends and the extra capacity begins:
Doubling Appends
What if we try to append an item but our array's capacity is already full? To make room, dynamic arrays automatically make a new, bigger underlying array. Usually twice as big. Why not just extend the existing array? Because that memory might already be taken by another program. Each item has to be individually copied into the new array:
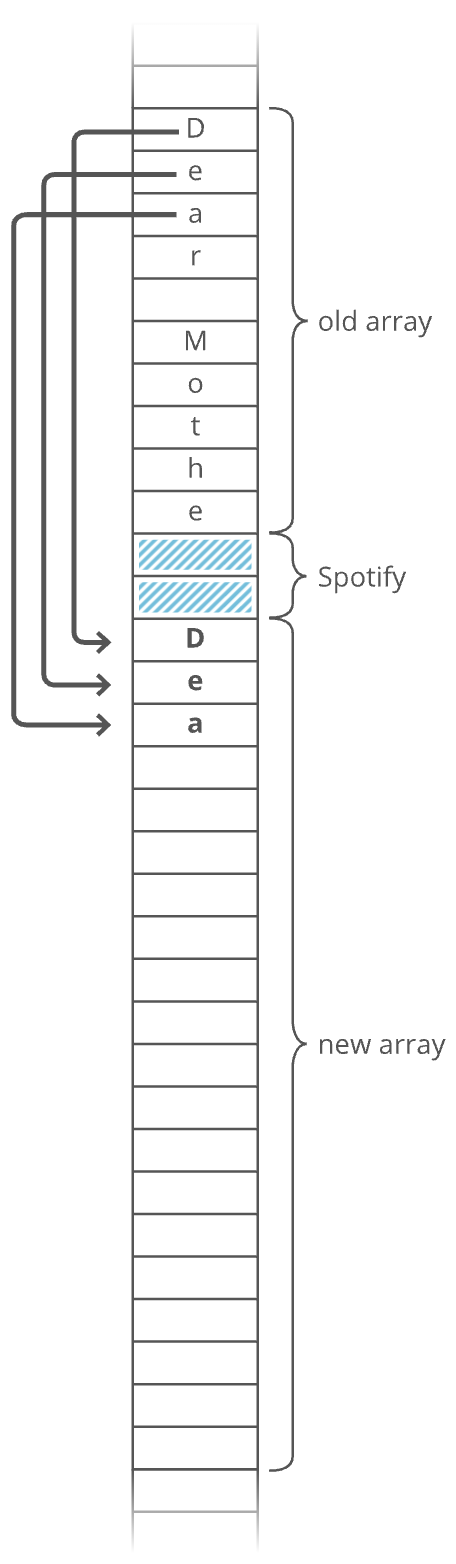
Copying each item over costs time! So whenever appending an item to our dynamic array forces us to make a new double-size underlying array, that append takes time. That's the worst case. But in the best case (and the average case), appends are just time.
Amortized cost of appending
- The time cost of each special "doubling append" doubles each time.
- At the same time, the number of appends you get until the next doubling append also doubles.
These two things sort of "cancel out," and we can say each append has an average cost or amortized cost of . Given this, in industry we usually wave our hands and say dynamic arrays have a time cost of for appends, even though strictly speaking that's only true for the average case or the amortized cost.
Amortized cost
Amortize is a fancy verb used in finance that refers to paying off the cost of something gradually. With dynamic arrays, every expensive append where we have to grow the array "buys" us many cheap appends in the future. Conceptually, we can spread the cost of the expensive append over all those cheap appends.
Instead of looking at the worst case for an append individually, let's look at the overall cost of doing many appends—-let's say appends. The cost of doing appends has two parts:
- The cost of actually appending all items.
- The cost of any "doubling" we need to do along the way.
The first part is easy—-each of our items costs time to append. So that's time for all of them.
The second part is trickier. How much do all the doubling operations cost? Remember: with each "doubling" we double the capacity of our underlying array. So it'll be twice as long until the next doubling as it was until the previous doubling. Say we start off with space for just one item. Our first doubling will involve copying over just one item. We'll need to double again with two items. That'll involve copying over two items. And we'll need to double again with four items. And again with eight items. And so on.
So, the total cost for copying over items across all of our doubling operations is:
It's helpful to look at this sum from right to left:
We can see what this comes to when we draw it out. If this is :

is half the size:

is half the size of that:

And so on:

We can see that the whole right side ends up being another square of size , making the sum . So when we do appends, the appends themselves cost , and the doubling costs . Put together, we've got a cost of , which is . So on average, each individual append is . appends cost us .
Remember: even though the amortized cost of an append is , the worst case cost is still . Some appends will take a long time.
Practice
Merging Meeting Times
To do this, you'll need to know when any team is having a meeting. In HiCal, a meeting is stored as a tuple of integers (start_time, end_time). These integers represent the number of 30-minute blocks past 9:00am.
Tuple
A tuple is like a list:
(17, 3, "My name is Parker")
(Tuples are written with parentheses to differentiate them from lists.) Like lists, tuples are ordered and you can access elements by their index:
cake_tuple = ('angel', 'bundt')
cake_tuple[0]
# returns: 'angel'
But tuples are immutable! They can't be edited after they're created.
cake_tuple = ('angel', 'bundt')
cake_tuple[1] = 'carrot'
# raises: TypeError: 'tuple' object does not support item assignment
Tuples can have any number of elements (the 'tu' in tuple doesn't mean 'two', it's just a generic name taken from words like 'septuple' and 'octuple').
(90, 4, 54)
(True, False, True, True, False)
For example:
(2, 3) # Meeting from 10:00 – 10:30 am
(6, 9) # Meeting from 12:00 – 1:30 pm
Write a function merge_ranges() that takes a list of multiple meeting time ranges and returns a list of condensed ranges.
For example, given:
[(0, 1), (3, 5), (4, 8), (10, 12), (9, 10)]
your function would return:
[(0, 1), (3, 8), (9, 12)]
Do not assume the meetings are in order. The meeting times are coming from multiple teams. Write a solution that's efficient even when we can't put a nice upper bound on the numbers representing our time ranges. Here we've simplified our times down to the number of 30-minute slots past 9:00 am. But we want the function to work even for very large numbers, like Unix timestamps. In any case, the spirit of the challenge is to merge meetings where start_time and end_time don't have an upper bound.
Hint 1
What if we only had two ranges? Let's take:
[(1, 3), (2, 4)]
These meetings clearly overlap, so we should merge them to give:
[(1, 4)]
But how did we know that these meetings overlap?
Hint 2
We could tell the meetings overlapped because the end time of the first one was after the start time of the second one! But our ideas of "first" and "second" are important here-—this only works after we ensure that we treat the meeting that starts earlier as the "first" one. How would we formalize this as an algorithm? Be sure to consider these edge cases:
1. The end time of the first meeting and the start time of the second meeting are equal. For example:
[(1, 2), (2, 3)]
2. The second meeting ends before the first meeting ends. For example:
[(1, 5), (2, 3)]
Hint 3
Here's a formal algorithm:
- We treat the meeting with earlier start time as "first," and the other as "second."
- If the end time of the first meeting is equal to or greater than the start time of the second meeting, we merge the two meetings into one time range. The resulting time range's start time is the first meeting's start, and its end time is the later of the two meetings' end times.
- Else, we leave them separate.
So, we could compare every meeting to every other meeting in this way, merging them or leaving them separate. Comparing all pairs of meetings would take time. We can do better!
Hint 4
If we're going to beat time, then maybe we're going to get time? Is there a way to do this in one pass?
Hint 5
It'd be great if, for each meeting, we could just try to merge it with the next meeting. But that's definitely not sufficient, because the ordering of our meetings is random. There might be a non-next meeting that the current meeting could be merged with.
Hint 6
What if we sorted our array of meetings by start time?
Hint 7
Then any meetings that could be merged would always be adjacent! So we could sort our meetings, then walk through the sorted array and see if each meeting can be merged with the one after it. Sorting takes time in the worst case. If we can then do the merging in one pass, that's another time, for overall. That's not as good as , but it's better than .
Hint 8 (solution)
Solution
First, we sort our input array of meetings by start time so any meetings that might need to be merged are now next to each other. Then we walk through our sorted meetings from left to right. At each step, either:
- We can merge the current meeting with the previous one, so we do.
- We can't merge the current meeting with the previous one, so we know the previous meeting can't be merged with any future meetings and we throw the current meeting into
merged_meetings.
def merge_ranges(meetings):
# Sort by start time
sorted_meetings = sorted(meetings)
# Initialize merged_meetings with the earliest meeting
merged_meetings = [sorted_meetings[0]]
for current_meeting_start, current_meeting_end in sorted_meetings[1:]:
last_merged_meeting_start, last_merged_meeting_end = merged_meetings[-1]
# If the current meeting overlaps with the last merged meeting, use the
# later end time of the two
if (current_meeting_start <= last_merged_meeting_end):
merged_meetings[-1] = (last_merged_meeting_start,
max(last_merged_meeting_end,
current_meeting_end))
else:
# Add the current meeting since it doesn't overlap
merged_meetings.append((current_meeting_start, current_meeting_end))
return merged_meetings
Complexity
time and space.
Even though we only walk through our array of meetings once to merge them, we sort all the meetings first, giving us a runtime of . It's worth noting that if our input were sorted, we could skip the sort and do this in time.
We create a new array of merged meeting times. In the worst case, none of the meetings overlap, giving us an array identical to the input array. Thus we have a worst-case space cost of .
Bonus
- What if did have an upper bound on the input values? Could we improve our runtime? Would it cost us memory?
- Could we do this "in place" on the input array and save some space? What are the pros and cons of doing this in place?
What We Learned
This one arguably uses a greedy approach as well, except this time we had to sort the array first. How did we figure that out?
Greedy algorithm
A greedy algorithm builds up a solution by choosing the option that looks the best at every step. Say you're a cashier and need to give someone 67 cents (US) using as few coins as possible. How would you do it? Whenever picking which coin to use, you'd take the highest-value coin you could. A quarter, another quarter, then a dime, a nickel, and finally two pennies. That's a greedy algorithm, because you're always greedily choosing the coin that covers the biggest portion of the remaining amount.
Some other places where a greedy algorithm gets you the best solution:
- Trying to fit as many overlapping meetings as possible in a conference room? At each step, schedule the meeting that ends earliest.
- Looking for a minimum spanning tree in a graph? At each step, greedily pick the cheapest edge that reaches a new vertex.
Note: sometimes a greedy algorithm doesn't give you an optimal solution as the following illustrates:
- When filling a duffel bag with cakes of different weights and values, choosing the cake with the highest value per pound doesn't always produce the best haul.
- To find the cheapest route visiting a set of cities, choosing to visit the cheapest city you haven't been to yet doesn't produce the cheapest overall itinerary.
Validating that a greedy strategy always gets the best answer is tricky. Either prove that the answer produced by the greedy algorithm is as good as an optimal answer, or run through a rigorous set of test cases to convince your interviewer (and yourself) that it is correct.
We started off trying to solve the problem in one pass, and we noticed that it wouldn't work. We then noticed the reason it wouldn't work: to see if a given meeting can be merged, we have to look at all the other meetings! That's because the order of the meetings is random.
That's what got us thinking: what if the array were sorted? We saw that then a greedy approach would work. We had to spend time on sorting the array, but it was better than our initial brute force approach, which cost us time.
Reverse String in Place
Write a function that takes a list of characters and reverses the letters in place.
Why a list of characters instead of a string?
The goal of this question is to practice manipulating strings in place. Since we're modifying the input, we need a mutable type like a list, instead of Python's immutable strings.
Hint 1
In general, an in-place algorithm will require swapping elements.
Hint 2 (solution)
Solution
We swap the first and last characters, then the second and second-to-last characters, and so on until we reach the middle.
def reverse(list_of_chars):
left_index = 0
right_index = len(list_of_chars) - 1
while left_index < right_index:
# Swap characters
list_of_chars[left_index], list_of_chars[right_index] = \
list_of_chars[right_index], list_of_chars[left_index]
# Move towards middle
left_index += 1
right_index -= 1
Complexity
time and space.
My Solution(s)
Here is one possible solution:
def reverse_char_list(arr):
right = len(arr)-1
for i in range(0,int(len(arr)/2)):
arr[i], arr[right-i] = arr[right-i], arr[i]
return arr
This seems to be simpler than the "official" solution using while as well as more efficient too (even if only in a trivially optimal way): looping over range() in Python appears to be faster than using a while loop as noted in this SO post.
Reverse Words
You're working on a secret team solving coded transmissions. Your team is scrambling to decipher a recent message, worried it's a plot to break into a major European National Cake Vault. The message has been mostly deciphered, but all the words are backward! Your colleagues have handed off the last step to you.
Write a function reverse_words() that takes a message as a list of characters and reverses the order of the words in place.
For example:
message = [ 'c', 'a', 'k', 'e', ' ',
'p', 'o', 'u', 'n', 'd', ' ',
's', 't', 'e', 'a', 'l' ]
reverse_words(message)
# Prints: 'steal pound cake'
print(''.join(message))
When writing your function, assume the message contains only letters and spaces, and all words are separated by one space.
Hint 1
Let's start with a simpler problem. What if we wanted to reverse all the characters in the message?
Hint 2
Well, we could swap the first character with the last character, then the second character with the second to last character, and so on, moving towards the middle. Can you implement this in code?
Hint 3
def reverse_characters(message):
left_index = 0
right_index = len(message) - 1
# Walk towards the middle, from both sides
while left_index < right_index:
# Swap the left char and right char
message[left_index], message[right_index] = \
message[right_index], message[left_index]
left_index += 1
right_index -= 1
We're using a cute one-liner to do the swap. In other languages you might need to do the swap by hand, recording one of the values in a temp variable. Ok, looks good. Does this help us? Can we use the same concept but apply it to words instead of characters?
Hint 4
Probably. We'll have to figure out a couple things:
- How do we figure out where words begin and end?
- Once we know the start and end indices of two words, how do we swap those two words?
We could attack either of those first, but I'm already seeing a potential problem in terms of runtime. Can you guess what it is?
Hint 5
What happens when you swap two words that aren't the same length?
# the eagle has landed
[ 't', 'h', 'e', ' ', 'e', 'a', 'g', 'l', 'e', ' ',
'h', 'a', 's', ' ', 'l', 'a', 'n', 'd', 'e', 'd' ]
Supposing we already knew the start and end indices of 'the' and 'landed', how long would it take to swap them?
Hint 6
time, where is the total length of the message!
Why? Notice that in addition to moving 'the' to the back and moving 'landed' to the front, we have to "scoot over" everything in between, since 'landed' is longer than 'the'.
So what'll be the total time cost with this approach? Assume we'll be able to learn the start and end indices of all of our words in just one pass ( time).
Hint 7
total time. Why? In the worst case we have almost as many words as we have characters, and we're always swapping words of different lengths. For example:
# a bb c dd e ff g hh
[ 'a', ' ', 'b', 'b', ' ', 'c', ' ', 'd', 'd', ' ',
'e', ' ', 'f', 'f', ' ', 'g', ' ', 'h', 'h' ]
We take time to swap the first and last words (we have to move all characters):
# Input: a bb c dd e ff g hh
[ 'a', ' ', 'b', 'b', ' ', 'c', ' ', 'd', 'd', ' ',
'e', ' ', 'f', 'f', ' ', 'g', ' ', 'h', 'h' ]
# First swap: hh bb c dd e ff g a
[ 'h', 'h', ' ', 'b', 'b', ' ', 'c', ' ', 'd', 'd',
' ', 'e', ' ', 'f', 'f', ' ', 'g', ' ', 'a' ]
Then for the second swap:
# Input: a bb c dd e ff g hh
[ 'a', ' ', 'b', 'b', ' ', 'c', ' ', 'd', 'd', ' ',
'e', ' ', 'f', 'f', ' ', 'g', ' ', 'h', 'h' ]
# First swap: hh bb c dd e ff g a
[ 'h', 'h', ' ', 'b', 'b', ' ', 'c', ' ', 'd', 'd',
' ', 'e', ' ', 'f', 'f', ' ', 'g', ' ', 'a' ]
# Second swap: hh g c dd e ff bb a
[ 'h', 'h', ' ', 'g', ' ', 'c', ' ', 'd', 'd',
' ', 'e', ' ', 'f', 'f', ' ', 'b', 'b', ' ', 'a' ]
We have to move all characters except the first and last words, and a couple spaces. So we move characters in total.
For the third swap, we have another 5 characters we don't have to move. So we move in total. We'll end up with a series like this:
This is a subsection of the common triangular series. We're just skipping 4 terms between each term!
So we have the sum of "every fifth number" from that triangular series. That means our sum will be about a fifth the sum of the original series! But in big O notation dividing by 5 is a constant, so we can throw it out. The original triangular series is , and so is our series with every fifth element!
Okay, so time. That's pretty bad. It's possible that's the best we can do...but maybe we can do better?
Hint 8
Let's try manipulating a sample input by hand.
And remember what we did for our character-level reversal...
Hint 9
Look what happens when we do a character-level reversal:
# Input: the eagle has landed
[ 't', 'h', 'e', ' ', 'e', 'a', 'g', 'l', 'e', ' ',
'h', 'a', 's', ' ', 'l', 'a', 'n', 'd', 'e', 'd' ]
# Character-reversed: dednal sah elgae eht
[ 'd', 'e', 'd', 'n', 'a', 'l', ' ', 's', 'a', 'h', ' ',
'e', 'l', 'g', 'a', 'e', ' ', 'e', 'h', 't' ]
Notice anything?
Hint 10
What if we put it up against the desired output:
# Input: the eagle has landed
[ 't', 'h', 'e', ' ', 'e', 'a', 'g', 'l', 'e', ' ',
'h', 'a', 's', ' ', 'l', 'a', 'n', 'd', 'e', 'd' ]
# Character-reversed: dednal sah elgae eht
[ 'd', 'e', 'd', 'n', 'a', 'l', ' ', 's', 'a', 'h', ' ',
'e', 'l', 'g', 'a', 'e', ' ', 'e', 'h', 't' ]
# Word-reversed (desired output): landed has eagle the
[ 'l', 'a', 'n', 'd', 'e', 'd', ' ', 'h', 'a', 's', ' ',
'e', 'a', 'g', 'l', 'e', ' ', 't', 'h', 'e' ]
Hint 11
The character reversal reverses the words! It's a great first step. From there, we just have to "unscramble" each word.
More precisely, we just have to re-reverse each word!
Hint 12 (solution)
Solution
We'll write a helper function reverse_characters() that reverses all the characters between a left_index and right_index. We use it to:
- Reverse all the characters in the entire message, giving us the correct word order but with each word backward.
- Reverse the characters in each individual word.
def reverse_words(message):
# First we reverse all the characters in the entire message
reverse_characters(message, 0, len(message)-1)
# This gives us the right word order
# but with each word backward
# Now we'll make the words forward again
# by reversing each word's characters
# We hold the index of the *start* of the current word
# as we look for the *end* of the current word
current_word_start_index = 0
for i in range(len(message) + 1):
# Found the end of the current word!
if (i == len(message)) or (message[i] == ' '):
reverse_characters(message, current_word_start_index, i - 1)
# If we haven't exhausted the message our
# next word's start is one character ahead
current_word_start_index = i + 1
def reverse_characters(message, left_index, right_index):
# Walk towards the middle, from both sides
while left_index < right_index:
# Swap the left char and right char
message[left_index], message[right_index] = \
message[right_index], message[left_index]
left_index += 1
right_index -= 1
Complexity
time and space!
Hmm, the team used your function to finish deciphering the message. There definitely seems to be a heist brewing, but no specifics on where. Any ideas?
Bonus
How would you handle punctuation?
What We Learned
The naive solution of reversing the words one at a time had a worst-case . That's because swapping words with different lengths required "scooting over" all the other characters to make room.
To get around this "scooting over" issue, we reversed all the characters in the message first. This put all the words in the correct spots, but with the characters in each word backward. So to get the final answer, we reversed the characters in each word. This all takes two passes through the message, so time total.
This might seem like a blind insight, but we derived it by using a clear strategy:
Solve a simpler version of the problem (in this case, reversing the characters instead of the words), and see if that gets us closer to a solution for the original problem.
We talk about this strategy in the "get unstuck" section of our coding interview tips.
My solution(s)
def reverse_words(message):
# reverse all characters in message
# this will give us the right word order
# but with each word in reverse order
reverse_char_list(message)
# reverse the reverse ordering of each
# word so that each word has the correct order
# each space marks the end of one word and the
# beginning of the next word
# reverse all characters before each encountered space
# and the space prior to that space
space_index = 0
for i in range(0, len(message)):
if message[i] == ' ':
reverse_char_list(message, space_index, i-1)
space_index = i+1
# ensure the last word has its characters reversed
reverse_char_list(message, space_index)
return message
def reverse_char_list(arr, start=None, end=None):
if start is None: start = 0
if end is None: end = len(arr)-1
while start < end:
arr[start], arr[end] = arr[end], arr[start]
start += 1
end -= 1
return arr
Merge Sorted Arrays
In order to win the prize for most cookies sold, my friend Alice and I are going to merge our Girl Scout Cookies orders and enter as one unit.
Each order is represented by an "order id" (an integer).
We have our lists of orders sorted numerically already, in lists. Write a function to merge our lists of orders into one sorted list.
For example:
my_list = [3, 4, 6, 10, 11, 15]
alices_list = [1, 5, 8, 12, 14, 19]
# Prints [1, 3, 4, 5, 6, 8, 10, 11, 12, 14, 15, 19]
print(merge_lists(my_list, alices_list))
Hint 1
We could simply concatenate (join together) the two lists into one, then sort the result:
def merge_sorted_lists(arr1, arr2):
return sorted(arr1 + arr2)
What would the time cost be?
Hint 2
, where is the total length of our output list (the sum of the lengths of our inputs).
We can do better. With this algorithm, we're not really taking advantage of the fact that the input lists are themselves already sorted. How can we save time by using this fact?
Hint 3
A good general strategy for thinking about an algorithm is to try writing out a sample input and performing the operation by hand. If you're stuck, try that!
Hint 4
Since our lists are sorted, we know they each have their smallest item in the 0th index. So the smallest item overall is in the 0th index of one of our input lists!
Which 0th element is it? Whichever is smaller!
To start, let's just write a function that chooses the 0th element for our sorted list.
Hint 5
def merge_lists(my_list, alices_list):
# Make a list big enough to fit the elements from both lists
merged_list_size = len(my_list) + len(alices_list)
merged_list = [None] * merged_list_size
head_of_my_list = my_list[0]
head_of_alices_list = alices_list[0]
if head_of_my_list < head_of_alices_list:
# Case: 0th comes from my list
merged_list[0] = head_of_my_list
else:
# Case: 0th comes from Alice's list
merged_list[0] = head_of_alices_list
# Eventually we'll want to return the merged list
return merged_list
Okay, good start! That works for finding the 0th element. Now how do we choose the next element?
Hint 6
Let's look at a sample input:
[3, 4, 6, 10, 11, 15] # my_list
[1, 5, 8, 12, 14, 19] # alices_list
To start we took the 0th element from alices_list and put it in the 0th slot in the output array:
[3, 4, 6, 10, 11, 15] # my_list
[1, 5, 8, 12, 14, 19] # alices_list
[1, x, x, x, x, x] # merged_list
We need to make sure we don't try to put that 1 in merged_list again. We should mark it as "already merged" somehow. For now, we can just cross it out:
[3, 4, 6, 10, 11, 15] # my_list
[x, 5, 8, 12, 14, 19] # alices_list
[1, x, x, x, x, x] # merged_list
Or we could even imagine it's removed from the list:
[3, 4, 6, 10, 11, 15] # my_list
[5, 8, 12, 14, 19] # alices_list
[1, x, x, x, x, x] # merged_list
Now to get our next element we can use the same approach we used to get the 0th element—-it's the smallest of the earliest unmerged elements in either array! In other words, it's the smaller of the leftmost elements in either array, assuming we've removed the elements we've already merged in.
So in general we could say something like:
- We'll start at the beginnings of our input arrays, since the smallest elements will be there.
- As we put items in our final
merged_list, we'll keep track of the fact that they're "already merged." - At each step, each array has a first "not-yet-merged" item.
- At each step, the next item to put in the
merged_listis the smaller of those two "not-yet-merged" items!
Can you implement this in code?
Hint 7
def merge_lists(my_list, alices_list):
merged_list_size = len(my_list) + len(alices_list)
merged_list = [None] * merged_list_size
current_index_alices = 0
current_index_mine = 0
current_index_merged = 0
while current_index_merged < merged_list_size:
first_unmerged_alices = alices_list[current_index_alices]
first_unmerged_mine = my_list[current_index_mine]
if first_unmerged_mine < first_unmerged_alices:
# Case: next comes from my list
merged_list[current_index_merged] = first_unmerged_mine
current_index_mine += 1
else:
# Case: next comes from Alice's list
merged_list[current_index_merged] = first_unmerged_alices
current_index_alices += 1
current_index_merged += 1
return merged_list
Okay, this algorithm makes sense. To wrap up, we should think about edge cases and check for bugs. What edge cases should we worry about?
Hint 8
Here are some edge cases:
- One or both of our input arrays is 0 elements or 1 element
- One of our input arrays is longer than the other.
- One of our arrays runs out of elements before we're done merging.
Actually, (3) will always happen. In the process of merging our arrays, we'll certainly exhaust one before we exhaust the other.
Does our function handle these cases correctly?
Hint 9
If both lists are empty, we're fine. But for all other edge cases, we'll get an IndexError. How can we fix this?
Hint 10
We can probably solve these cases at the same time. They're not so different—-they just have to do with indexing past the end of lists.
To start, we could treat each of our lists being out of elements as a separate case to handle, in addition to the 2 cases we already have. So we have 4 cases total. Can you code that up?
Be sure you check the cases in the right order!
Hint 11
def merge_lists(my_list, alices_list):
merged_list_size = len(my_list) + len(alices_list)
merged_list = [None] * merged_list_size
current_index_alices = 0
current_index_mine = 0
current_index_merged = 0
while current_index_merged < merged_list_size:
if current_index_mine >= len(my_list):
# Case: my list is exhausted
merged_list[current_index_merged] = alices_list[current_index_alices]
current_index_alices += 1
elif current_index_alices >= len(alices_list):
# Case: Alice's list is exhausted
merged_list[current_index_merged] = my_list[current_index_mine]
current_index_mine += 1
elif my_list[current_index_mine] < alices_list[current_index_alices]:
# Case: my item is next
merged_list[current_index_merged] = my_list[current_index_mine]
current_index_mine += 1
else:
# Case: Alice's item is next
merged_list[current_index_merged] = alices_list[current_index_alices]
current_index_alices += 1
current_index_merged += 1
return merged_list
Cool. This'll work, but it's a bit repetitive. We have these two lines twice:
merged_list[current_index_merged] = my_list[current_index_mine]
current_index_mine += 1
Same for these two lines:
merged_list[current_index_merged] = alices_list[current_index_alices]
current_index_alices += 1
That's not DRY. Maybe we can avoid repeating ourselves by bringing our code back down to just 2 cases.
See if you can do this in just one "if else" by combining the conditionals.
Hint 12
You might try to simply squish the middle cases together:
if (is_alices_list_exhausted or
my_list[current_index_mine] < alices_list[current_index_alices]):
merged_list[current_index_merged] = my_list[current_index_mine]
current_index_mine += 1
But what happens when my_list is exhausted?
Hint 13
We'll get an IndexError when we try to access my_list[current_index_mine]! How can we fix this?
Hint 14 (solution)
Solution
First, we allocate our answer list, getting its size by adding the size of my_list and alices_list.
We keep track of a current index in my_list, a current index in alices_list, and a current index in merged_list. So at each step, there's a "current item" in alices_list and in my_list. The smaller of those is the next one we add to the merged_list!
But careful: we also need to account for the case where we exhaust one of our arrays and there are still elements in the other. To handle this, we say that the current item in my_list is the next item to add to merged_list only if my_list is not exhausted AND, either:
alices_listis exhausted, or- the current item in
my_listis less than the current item inalices_list
def merge_lists(my_list, alices_list):
# Set up our merged_list
merged_list_size = len(my_list) + len(alices_list)
merged_list = [None] * merged_list_size
current_index_alices = 0
current_index_mine = 0
current_index_merged = 0
while current_index_merged < merged_list_size:
is_my_list_exhausted = current_index_mine >= len(my_list)
is_alices_list_exhausted = current_index_alices >= len(alices_list)
if (not is_my_list_exhausted and
(is_alices_list_exhausted or
my_list[current_index_mine] < alices_list[current_index_alices])):
# Case: next comes from my list
# My list must not be exhausted, and EITHER:
# 1) Alice's list IS exhausted, or
# 2) the current element in my list is less
# than the current element in Alice's list
merged_list[current_index_merged] = my_list[current_index_mine]
current_index_mine += 1
else:
# Case: next comes from Alice's list
merged_list[current_index_merged] = alices_list[current_index_alices]
current_index_alices += 1
current_index_merged += 1
return merged_list
The if statement is carefully constructed to avoid an IndexError from indexing past the end of a list. We take advantage of Python's short circuit evaluation ↴ and check first if the lists are exhausted.
Complexity
time and additional space, where is the number of items in the merged list.
The added space comes from allocating the merged_list. There's no way to do this "in place" because neither of our input lists are necessarily big enough to hold the merged list.
But if our inputs were linked lists, we could avoid allocating a new structure and do the merge by simply adjusting the next pointers in the list nodes!
In our implementation above, we could avoid tracking current_index_merged and just compute it on the fly by adding current_index_mine and current_index_alices. This would only save us one integer of space though, which is hardly anything. It's probably not worth the added code complexity.
Trivia! Python's native sorting algorithm is called Timsort. It's actually optimized for sorting lists where subsections of the lists are already sorted. For this reason, a more naive algorithm:
def merge_sorted_lists(arr1, arr2):
return sorted(arr1 + arr2)
is actually faster until gets pretty big. Like 1,000,000.
Also, in Python 2.6+, there's a built-in function for merging sorted lists into one sorted list: heapq.merge().
Bonus
What if we wanted to merge several sorted lists? Write a function that takes as an input a list of sorted lists and outputs a single sorted list with all the items from each list.
Do we absolutely have to allocate a new list to use for the merged output? Where else could we store our merged list? How would our function need to change?
What We Learned
We spent a lot of time figuring out how to cleanly handle edge cases.
Sometimes it's easy to lose steam at the end of a coding interview when you're debugging. But keep sprinting through to the finish! Think about edge cases. Look for off-by-one errors.
Cafe Order Checker
My cake shop is so popular, I'm adding some tables and hiring wait staff so folks can have a cute sit-down cake-eating experience.
I have two registers: one for take-out orders, and the other for the other folks eating inside the cafe. All the customer orders get combined into one list for the kitchen, where they should be handled first-come, first-served.
Recently, some customers have been complaining that people who placed orders after them are getting their food first. Yikes—-that's not good for business!
To investigate their claims, one afternoon I sat behind the registers with my laptop and recorded:
- The take-out orders as they were entered into the system and given to the kitchen. (
take_out_orders) - The dine-in orders as they were entered into the system and given to the kitchen. (
dine_in_orders) - Each customer order (from either register) as it was finished by the kitchen. (
served_orders)
Given all three lists, write a function to check that my service is first-come, first-served. All food should come out in the same order customers requested it.
We'll represent each customer order as a unique integer.
As an example,
Take Out Orders: [1, 3, 5]
Dine In Orders: [2, 4, 6]
Served Orders: [1, 2, 4, 6, 5, 3]
would not be first-come, first-served, since order 3 was requested before order 5 but order 5 was served first.
But,
Take Out Orders: [17, 8, 24]
Dine In Orders: [12, 19, 2]
Served Orders: [17, 8, 12, 19, 24, 2]
would be first-come, first-served.
Note: Order numbers are arbitrary. They do not have to be in increasing order.
Hint 1
How can we re-phrase this problem in terms of smaller subproblems?
Hint 2
Breaking the problem into smaller subproblems will clearly involve reducing the size of at least one of our lists of customer order numbers. So to start, let's try taking the first customer order out of served_orders.
What should be true of this customer order number if my service is first-come, first-served?
Hint 3
If my cake cafe is first-come, first-served, then the first customer order finished (first item in served_orders) has to either be the first take-out order entered into the system (take_out_orders[0]) or the first dine-in order entered into the system (dine_in_orders[0]).
Once we can check the first customer order, how can we verify the remaining ones?
Hint 4
Let's "throw out" the first customer order from served_orders as well as the customer order it matched with from the beginning of take_out_orders or dine_in_orders. That customer order is now "accounted for."
Now we're left with a smaller version of the original problem, which we can solve using the same approach! So we keep doing this over and over until we exhaust served_orders. If we get to the end and every customer order "checks out," we return True.
How do we implement this in code?
Hint 5
Now that we have a problem that's the same as the original problem except smaller, our first thought might be to use recursion. All we need is a base case. What's our base case?
Hint 6
We stop when we run out of customer orders in our served_orders. So that's our base case: when we've checked all customer orders in served_orders, we return True because we know all of the customer orders have been "accounted for."
def is_first_come_first_served(take_out_orders, dine_in_orders, served_orders):
# Base case
if len(served_orders) == 0:
return True
# If the first order in served_orders is the same as the
# first order in take_out_orders
# (making sure first that we have an order in take_out_orders)
if len(take_out_orders) and take_out_orders[0] == served_orders[0]:
# Take the first order off take_out_orders and served_orders and recurse
return is_first_come_first_served(take_out_orders[1:], dine_in_orders, served_orders[1:])
# If the first order in served_orders is the same as the first
# in dine_in_orders
elif len(dine_in_orders) and dine_in_orders[0] == served_orders[0]:
# Take the first order off dine_in_orders and served_orders and recurse
return is_first_come_first_served(take_out_orders, dine_in_orders[1:], served_orders[1:])
# First order in served_orders doesn't match the first in
# take_out_orders or dine_in_orders, so we know it's not first-come, first-served
else:
return False
This solution will work. But we can do better.
Before we talk about optimization, note that our inputs are probably pretty small. This function will take hardly any time or space, even if it could be more efficient. In industry, especially at small startups that want to move quickly, optimizing this might be considered a "premature optimization." Great engineers have both the skill to see how to optimize their code and the wisdom to know when those optimizations aren't worth it. At this point in the interview I recommend saying, "I think we can optimize this a bit further, although given the nature of the input this probably won't be very resource-intensive anyway...should we talk about optimizations?"
Suppose we do want to optimize further. What are the time and space costs to beat? This function will take time and additional space.
Whaaaaat? Yeah. Take a look at this snippet:
return is_first_come_first_served(take_out_orders[1:], dine_in_orders, served_orders[1:])
In particular this expression:
take_out_orders[1:]
That's a slice, and it costs time and space, where is the size of the resulting array. That's going to determine our overall time and space cost here—-the rest of the work we're doing is constant space and time.
In our recursing we'll build up frames on the call stack. Each of those frames will hold a different slice of our original served_orders (and take_out_orders and dine_in_orders, though we only slice one of them in each recursive call).
So, what's the total time and space cost of all our slices?
If served_orders has items to start, taking our first slice takes time and space (plus half that, since we're also slicing one of our halves-—but that's just a constant multiplier so we can ignore it). In our second recursive call, slicing takes time and space. Etc.
So our total time and space cost for slicing comes to:
This is a common series that turns out to be .
We can do better than this time and space cost. One way we could to that is to avoid slicing and instead keep track of indices in the array:
def is_first_come_first_served(take_out_orders, dine_in_orders, served_orders,
take_out_orders_index=0, dine_in_orders_index=0,
served_orders_index=0):
# Base case we've hit the end of served_orders
if served_orders_index == len(served_orders):
return True
# If we still have orders in take_out_orders
# and the current order in take_out_orders is the same
# as the current order in served_orders
if ((take_out_orders_index < len(take_out_orders)) and
take_out_orders[take_out_orders_index] == served_orders[served_orders_index]):
take_out_orders_index += 1
# If we still have orders in dine_in_orders
# and the current order in dine_in_orders is the same
# as the current order in served_orders
elif ((dine_in_orders_index < len(dine_in_orders)) and
dine_in_orders[dine_in_orders_index] == served_orders[served_orders_index]):
dine_in_orders_index += 1
# If the current order in served_orders doesn't match
# the current order in take_out_orders or dine_in_orders, then we're not
# serving in first-come, first-served order.
else:
return False
# The current order in served_orders has now been "accounted for"
# so move on to the next one
served_orders_index += 1
return is_first_come_first_served(
take_out_orders, dine_in_orders, served_orders,
take_out_orders_index, dine_in_orders_index, served_orders_index)
So now we're down to time, but we're still taking space in the call stack because of our recursion. We can rewrite this as an iterative function to get that memory cost down to .
Hint 7
What's happening in each iteration of our recursive function? Sometimes we're taking a customer order out of take_out_orders and sometimes we're taking a customer order out of dine_in_orders, but we're always taking a customer order out of served_orders.
So what if instead of taking customer orders out of served_orders 1-by-1, we iterated over them?
That should work. But are we missing any edge cases?
Hint 8
What if there are extra orders in take_out_orders or dine_in_orders that don't appear in served_orders? Would our kitchen be first-come, first-served then?
Maybe.
It's possible that our data doesn't include everything from the afternoon service. Maybe we stopped recording data before every order that went into the kitchen was served. It would be reasonable to say that our kitchen is still first-come, first-served, since we don't have any evidence otherwise.
On the other hand, if our input is supposed to cover the entire service, then any orders that went into the kitchen but weren't served should be investigated. We don't want to accept people's money but not serve them!
When in doubt, ask! This is a great question to talk through with your interviewer and shows that you're able to think through edge cases.
Both options are reasonable. In this writeup, we'll enforce that every order that goes into the kitchen (appearing in take_out_orders or dine_in_orders) should come out of the kitchen (appearing in served_orders). How can we check that?
Hint 9
To check that we've served every order that was placed, we'll validate that when we finish iterating through served_orders, we've exhausted take_out_orders and dine_in_orders.
Hint 10 (solution)
Solution
We walk through served_orders, seeing if each customer order so far matches a customer order from one of the two registers. To check this, we:
- Keep pointers to the current index in
take_out_orders,dine_in_orders, andserved_orders. - Walk through
served_ordersfrom beginning to end. - If the current order in
served_ordersis the same as the current customer order intake_out_orders, incrementtake_out_orders_indexand keep going. This can be thought of as "checking off" the current customer order intake_out_ordersandserved_orders, reducing the problem to the remaining customer orders in the arrays. - Same as above with
dine_in_orders. - If the current
orderisn't the same as the customer order at the front oftake_out_ordersordine_in_orders, we know something's gone wrong and we're not serving food first-come, first-served. - If we make it all the way to the end of
served_orders, we'll check that we've reached the end oftake_out_ordersanddine_in_orders. If every customer order checks out, that means we're serving food first-come, first-served.
def is_first_come_first_served(take_out_orders, dine_in_orders, served_orders):
take_out_orders_index = 0
dine_in_orders_index = 0
take_out_orders_max_index = len(take_out_orders) - 1
dine_in_orders_max_index = len(dine_in_orders) - 1
for order in served_orders:
# If we still have orders in take_out_orders
# and the current order in take_out_orders is the same
# as the current order in served_orders
if take_out_orders_index <= take_out_orders_max_index and order == take_out_orders[take_out_orders_index]:
take_out_orders_index += 1
# If we still have orders in dine_in_orders
# and the current order in dine_in_orders is the same
# as the current order in served_orders
elif dine_in_orders_index <= dine_in_orders_max_index and order == dine_in_orders[dine_in_orders_index]:
dine_in_orders_index += 1
# If the current order in served_orders doesn't match the current
# order in take_out_orders or dine_in_orders, then we're not serving first-come,
# first-served.
else:
return False
# Check for any extra orders at the end of take_out_orders or dine_in_orders
if dine_in_orders_index != len(dine_in_orders) or take_out_orders_index != len(take_out_orders):
return False
# All orders in served_orders have been "accounted for"
# so we're serving first-come, first-served!
return True
Complexity
time and additional space.
Bonus
- This assumes each customer order in
served_ordersis unique. How can we adapt this to handle arrays of customer orders with potential repeats? - Our implementation returns
truewhen all the items indine_in_ordersandtake_out_ordersare first-come first-served inserved_ordersandFalseotherwise. That said, it'd be reasonable to throw an exception if some orders that went into the kitchen were never served, or orders were served but not paid for at either register. How could we check for those cases? - Our solution iterates through the customer orders from front to back. Would our algorithm work if we iterated from the back towards the front? Which approach is cleaner?
What We Learned
If you read the whole breakdown section, you might have noticed that our recursive function cost us extra space. If you missed that part, go back and take a look.
Be careful of the hidden space costs from a recursive function's call stack! If you have a solution that's recursive, see if you can save space by using an iterative algorithm instead.