Hashing and Hash Tables
Readings
Hashing and Hash Functions
A hash function takes data (like a string, or a file's contents) and outputs a hash, a fixed-size string or number. For example, here's the MD5 hash (MD5 is a common hash function) for a file simply containing "cake":
DF7CE038E2FA96EDF39206F898DF134D
And here’s the hash for the same file after it was edited to be "cakes":
0E9091167610558FDAE6F69BD6716771
Notice the hash is completely different, even though the files were similar. Here's the hash for a long film I have on my hard drive:
664f67364296d08f31aec6fea4e9b83f
The hash is the same length as my other hashes, but this time it represents a much bigger file--461Mb.
We can think of a hash as a "fingerprint." We can trust that a given file will always have the same hash, but we can't go from the hash back to the original file. Sometimes we have to worry about multiple files having the same hash value, which is called a hash collision.
Some uses for hashing:
- Objects. Suppose we want an array-like data structure with constant-time lookups, but we want to look up values based on arbitrary "keys," not just sequential "indices." We could allocate an array, and use a hash function to translate keys into array indices. That's the basic idea behind an object!
- Preventing man-in-the-middle attacks. Ever notice those things that say "hash" or "md5" or "sha1" on download sites? The site is telling you, "We hashed this file on our end and got this result. When you finish the download, try hashing the file and confirming you get the same result. If not, your internet service provider or someone else might have injected malware or tracking software into your download!"
Hash Table
Quick Reference
Other names: hash, hash map, map, unordered map, dictionary
Description: Like an array except instead of indices you can set arbitrary keys for each value. A hash table organizes data so you can quickly look up values for a given key.
Visual description:
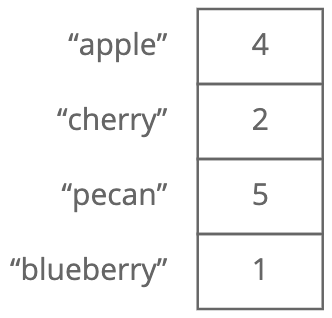
Strengths:
- Fast lookups: Lookups take time on average.
- Flexible keys: Most data types can be used for keys, as long as they're hashable.
Weaknesses:
- Slow worst-case lookups: Lookups take time in the worst case.
- Unordered: Keys aren't stored in a special order. If you're looking for the smallest key, the largest key, or all the keys in a range, you'll need to look through every key to find it.
- Single-directional lookups: While you can look up the value for a given key in time, looking up the keys for a given value requires looping through the whole dataset—- time.
- Not cache-friendly: Many hash table implementations use linked lists, which don't put data next to each other in memory.
Worst Case Analysis:
| Context | Big O |
|---|---|
| space | |
| insert | |
| lookup | |
| delete |
Average Case Analysis:
| Context | Big O |
|---|---|
| space | |
| insert | |
| lookup | |
| delete |
In JavaScript
In JavaScript, hash tables are called objects.
const lightBulbToHoursOfLight = {
'incandescent': 1200,
'compact fluorescent': 10000,
'LED': 50000,
};
What about JavaScript maps? Objects are way more common, but maps might be helpful if your keys aren't strings or you need to iterate over your data. One thing to know: maps aren't fully supported by all modern browsers yet.
Hash maps are built on arrays
Arrays are pretty similar to hash maps already. Arrays let you quickly look up the value for a given "key" ... except the keys are called "indices," and we don't get to pick them—-they're always sequential integers (0, 1, 2, 3, etc). Think of a hash map as a "hack" on top of an array to let us use flexible keys instead of being stuck with sequential integer "indices." All we need is a function to convert a key into an array index (an integer). That function is called a hashing function.
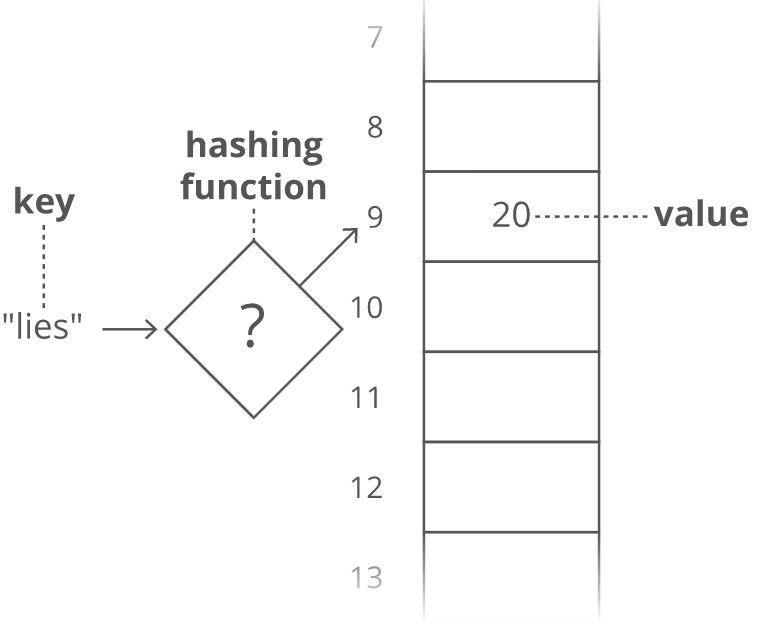
To look up the value for a given key, we just run the key through our hashing function to get the index to go to in our underlying array to grab the value. How does that hashing function work? There are a few different approaches, and they can get pretty complicated. But here's a simple proof of concept: Grab the number value for each character and add those up.
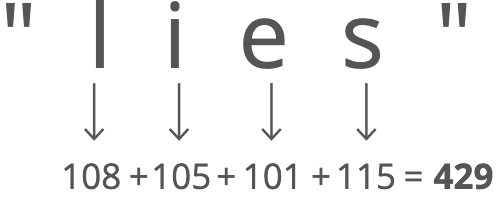
The result is 429. But what if we only have 30 slots in our array? We'll use a common trick for forcing a number into a specific range: the modulus operator (%). Modding our sum by 30 ensures we get a whole number that's less than 30 (and at least 0): 429 % 30 = 9.
The hashing functions used in modern systems get pretty complicated—the one we used here is a simplified example.
Hash collisions
What if two keys hash to the same index in our array? In our example above, look at "lies" and "foes":

They both sum up to 429! So of course they'll have the same answer when we mod by 30: 429 % 30 = 9.
This is called a hash collision. There are a few different strategies for dealing with them. Here's a common one: instead of storing the actual values in our array, let's have each array slot hold a pointer to a linked list holding the values for all the keys that hash to that index:
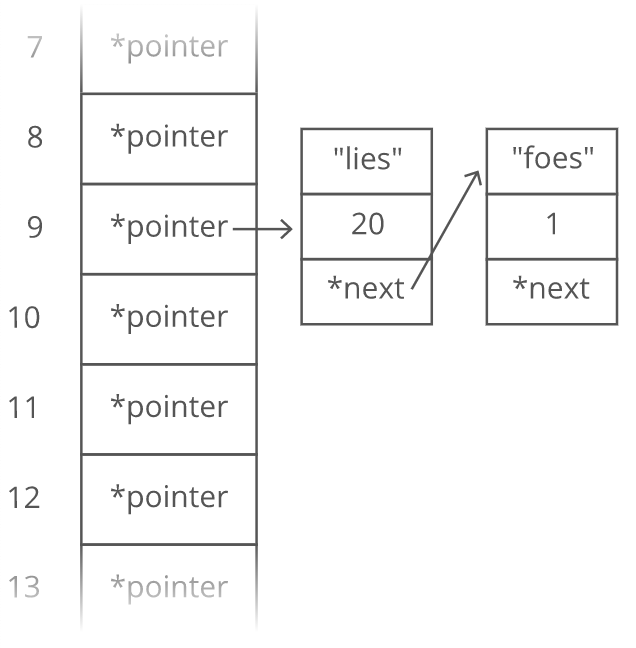
Notice that we included the keys as well as the values in each linked list node. Otherwise we wouldn't know which key was for which value! There are other ways to deal with hash collisions. This is just one of them.
When hash table operations cost time
Hash collisions: If all our keys caused hash collisions, we'd be at risk of having to walk through all of our values for a single lookup (in the example above, we'd have one big linked list). This is unlikely, but it could happen. That's the worst case.
Dynamic array resizing: Suppose we keep adding more items to our hash map. As the number of keys and values in our hash map exceeds the number of indices in the underlying array, hash collisions become inevitable. To mitigate this, we could expand our underlying array whenever things start to get crowded. That requires allocating a larger array and rehashing all of our existing keys to figure out their new position-- time.
Sets
A set is like a hash map except it only stores keys, without values. Sets often come up when we're tracking groups of items-—nodes we've visited in a graph, characters we've seen in a string, or colors used by neighboring nodes. Usually, we're interested in whether something is in a set or not. Sets are usually implemented very similarly to hash maps-—using hashing to index into an array—-but they don't have to worry about storing values alongside keys.
lightBulbs = new Set(["incandescent", "compact fluorescent", "LED"]);
lightBulbs.has("LED"); // true
lightBulbs.has("halogen"); // false
Practice
Inflight Entertainment
You've built an inflight entertainment system with on-demand movie streaming.
Users on longer flights like to start a second movie right when their first one ends, but they complain that the plane usually lands before they can see the ending. So you're building a feature for choosing two movies whose total runtimes will equal the exact flight length.
Write a function that takes an integer flight_length (in minutes) and a list of integers movie_lengths (in minutes) and returns a boolean indicating whether there are two numbers in movie_lengths whose sum equals flight_length.
When building your function:
- Assume your users will watch exactly two movies
- Don't make your users watch the same movie twice
- Optimize for runtime over memory
Hint 1
How would we solve this by hand? We know our two movie lengths need to sum to flight_length. So for a given first_movie_length, we need a second_movie_length that equals flight_length - first_movie_length.
To do this by hand we might go through movie_lengths from beginning to end, treating each item as first_movie_length, and for each of those check if there's a second_movie_length equal to flight_length - first_movie_length.
How would we implement this in code? We could nest two loops (the outer choosing first_movie_length, the inner choosing second_movie_length). That'd give us a runtime of . We can do better.
Hint 2
To bring our runtime down we'll probably need to replace that inner loop (the one that looks for a matching second_movie_length) with something faster.
Hint 3
We could sort the movie_lengths first—-then we could use binary search to find second_movie_length in time instead of time. But sorting would cost , and we can do even better than that.
Could we check for the existence of our second_movie_length in constant time?
Hint 3
What data structure gives us convenient constant-time lookups?
Hint 4
A set!
So we could throw all of our movie_lengths into a set first, in time. Then we could loop through our possible first_movie_lengths and replace our inner loop with a simple check in our set. This'll give us runtime overall!
Of course, we need to add some logic to make sure we're not showing users the same movie twice...
But first, we can tighten this up a bit. Instead of two sequential loops, can we do it all in one loop? (Done carefully, this will give us protection from showing the same movie twice as well.)
Hint 5 (solution)
Solution
We make one pass through movie_lengths, treating each item as the first_movie_length. At each iteration, we:
- See if there's a
matching_second_movie_lengthwe've seen already (stored in ourmovie_lengths_seenset) that is equal toflight_length - first_movie_length. If there is, we short-circuit and returnTrue. - Keep our
movie_lengths_seenset up to date by throwing in the currentfirst_movie_length.
def can_two_movies_fill_flight(movie_lengths, flight_length):
# Movie lengths we've seen so far
movie_lengths_seen = set()
for first_movie_length in movie_lengths:
matching_second_movie_length = flight_length - first_movie_length
if matching_second_movie_length in movie_lengths_seen:
return True
movie_lengths_seen.add(first_movie_length)
# We never found a match, so return False
return False
We know users won't watch the same movie twice because we check movie_lengths_seen for matching_second_movie_length before we've put first_movie_length in it!
Complexity
time, and space. Note while optimizing runtime we added a bit of space cost.
Bonus
- What if we wanted the movie lengths to sum to something close to the flight length (say, within 20 minutes)?
- What if we wanted to fill the flight length as nicely as possible with any number of movies (not just 2)?
- What if we knew that
movie_lengthswas sorted? Could we save some space and/or time?
What We Learned
The trick was to use a set to access our movies by length, in time.
Using hash-based data structures, like dictionaries or sets, is so common in coding challenge solutions, it should always be your first thought. Always ask yourself, right from the start: "Can I save time by using an dictionary?"
Permutation Palindrome
Write an efficient function that checks whether any permutation of an input string is a palindrome.
You can assume the input string only contains lowercase letters.
Examples:
- "civic" should return
True - "ivicc" should return
True - "civil" should return
False - "livci" should return
False
"But 'ivicc' isn't a palindrome!"
If you had this thought, read the question again carefully. We're asking if any permutation of the string is a palindrome. Spend some extra time ensuring you fully understand the question before starting. Jumping in with a flawed understanding of the problem doesn't look good in an interview.
Hint 1
The brute force approach would be to check every permutation of the input string to see if it is a palindrome.
What would be the time cost?
- We'd have to generate every permutation of the input string. If the string has characters, then there are choices for the first character, choices for the second character, and so on. In total, that's permutations.
- We'd have to check each permutation to see if it's a palindrome. That takes time per permutation, since each permutation is letters.
Together, that's time. Yikes! We can do better.
Hint 2
Let's try rephrasing the problem. How can we tell if any permutation of a string is a palindrome?
Hint 3
Well, how would we check that a string is a palindrome? We could use the somewhat-common "keep two pointers" pattern. We'd start a pointer at the beginning of the string and a pointer at the end of the string, and check that the characters at those pointers are equal as we walk both pointers towards the middle of the string.
civic
^ ^
civic
^ ^
civic
^
Can we adapt the idea behind this approach to checking if any permutation of a string is a palindrome?
Hint 4
Notice: we're essentially checking that each character left of the middle has a corresponding copy right of the middle.
Hint 5
We can simply check that each character appears an even number of times (unless there is a middle character, which can appear once or some other odd number of times). This ensures that the characters can be ordered so that each char on the left side of the string has a matching char on the right side of the string.
But we'll need a data structure to keep track of the number of times each character appears. What should we use?
Hint 6
We could use a dictionary. (Tip: using a dictionary is the most common way to get from a brute force approach to something more clever. It should always be your first thought.)
Hint 7
So we'll go through all the characters and track how many times each character appears in the input string. Then we just have to make sure no more than one of the characters appears an odd numbers of times.
That will give us a runtime of , which is the best we can do since we have to look at a number of characters dependent on the length of the input string.
Ok, so we've reached our best run time. But can we still clean our solution up a little?
Hint 8
We don't really care how many times a character appears in the string, we just need to know whether the character appears an even or odd number of times.
Hint 9
What if we just track whether or not each character appears an odd number of times? Then we can map characters to booleans. This will be more explicit (we don't have to check each number's parity, we already have booleans) and we'll avoid the risk of integer overflow ↴ if some characters appear a high number of times.
Can we take this a step further and clean it up even more?
Hint 10
Even more specifically than whether characters appear an even or odd number of times, we really just need to know there isn't more than one character that appears an odd number of times.
What if we only track the characters that appear an odd number of times? Is there a data structure even simpler than a dictionary we could use?
Hint 11
We could use a set, adding and removing characters as we look through the input string, so the set always only holds the characters that appear an odd number of times.
Hint 12 (solution
Solution
Our approach is to check that each character appears an even number of times, allowing for only one character to appear an odd number of times (a middle character). This is enough to determine if a permutation of the input string is a palindrome.
We iterate through each character in the input string, keeping track of the characters we've seen an odd number of times using a set unpaired_characters.
As we iterate through the characters in the input string:
- If the character is not in
unpaired_characters, we add it. - If the character is already in
unpaired_characters, we remove it.
Finally, we just need to check if less than two characters don't have a pair.
def has_palindrome_permutation(the_string):
# Track characters we've seen an odd number of times
unpaired_characters = set()
for char in the_string:
if char in unpaired_characters:
unpaired_characters.remove(char)
else:
unpaired_characters.add(char)
# The string has a palindrome permutation if it
# has one or zero characters without a pair
return len(unpaired_characters) <= 1
Complexity
time, since we're making one iteration through the characters in the string.
Our unpaired_characters set is the only thing taking up non-constant space. We could say our space cost is as well, since the set of unique characters is less than or equal to . But we can also look at it this way: there are only so many different characters. How many? The ASCII character set has just 128 different characters (standard english letters and punctuation), while Unicode has 110,000 (supporting several languages and some icons/symbols). We might want to treat our number of possible characters in our character set as another variable and say our space complexity is . Or we might want to just treat it as a constant, and say our space complexity is .
What We Learned
One of the tricks was to use a dictionary or set.
This is the most common way to get from a brute force approach to something more efficient. Especially for easier problems.
I even know interviewers who just want to hear you say "dictionary", and once they hear that they'll say, "Great, let's move on."
So always ask yourself, right from the start: "Can I save time by using an dictionary?"
Word Cloud Data
You want to build a word cloud, an infographic where the size of a word corresponds to how often it appears in the body of text.
To do this, you'll need data. Write code that takes a long string and builds its word cloud data in a dictionary, where the keys are words and the values are the number of times the words occurred.
Think about capitalized words. For example, look at these sentences:
"After beating the eggs, Dana read the next step:"
"Add milk and eggs, then add flour and sugar."
What do we want to do with "After", "Dana", and "add"? In this example, your final map should include one "Add" or "add" with a value of 22. Make reasonable (not necessarily perfect) decisions about cases like "After" and "Dana".
Assume the input will only contain words and standard punctuation.
You could make a reasonable argument to use regex in your solution. We won't, mainly because performance is difficult to measure and can get pretty bad.
Hint 1
We'll have to go through the entire input string, and we're returning a dictionary with every unique word. In the worst case every word is different, so our runtime and space cost will both be at least .
Hint 2
This challenge has several parts. Let's break them down.
- Splitting the words from the input string
- Populating the dictionary with each word
- Handling words that are both uppercase and lowercase in the input string
How would you start the first part?
Hint 3
We could use the built-in split() function to separate our words, but if we just split on spaces we'd have to iterate over all the words before or after splitting to clean up the punctuation. And consider em dashes or ellipses, which aren't surrounded by spaces but nonetheless separate words. Instead, we'll make our own split_words() function, which will let us iterate over the input string only once.
We'll check if each character is a letter with the string method isalpha().
Hint 4
Now how can we split each word? Let's assume, for now, that our helper function will return a list of words.
Hint 5
We'll iterate over all the characters in the input string. How can we identify when we've reached the end of a word?
Hint 6
Here's a simple example. It doesn't work perfectly yet—-you'll need to add code to handle the end of the input string, hyphenated words, punctuation, and edge cases.
def split_words(input_string):
words = []
current_word_start_index = 0
current_word_length = 0
for i, char in enumerate(input_string):
if char.isalpha():
if current_word_length == 0:
current_word_start_index = i
current_word_length += 1
else:
word = input_string[current_word_start_index:
current_word_start_index + current_word_length]
words.append(word)
current_word_length = 0
return words
Careful—-if you thought of building up the word character by character (using +=), you'd be doing a lot more work than you probably think. Every time we append a character to a string, Python makes a whole new string. If our input is one long word, then creating all these copies is time.
Instead, we keep track of the index where our word starts and its current length. Once we hit a space, we can use string slicing to extract the current word to append to the list. That keeps our split function at time.
Now we've solved the first part of the challenge, splitting the words. The next part is populating our dictionary with unique words. What do we do with each word?
Hint 7
If the word is in the dictionary, we'll increment its count. Otherwise, we'll add it to the dictionary with a count of 1.
words_to_counts = {}
def add_word_to_dictionary(word):
if word in words_to_counts:
words_to_counts[word] += 1
else:
words_to_counts[word] = 1
Hint 8
Alright, last part! How should we handle words that are uppercase and lowercase?
Hint 9
Consider these sentences:
'We came, we saw, we ate cake.'
'Friends, Romans, countrymen! Let us eat cake.'
'New tourists in New York often wait in long lines for cronuts.'
Take some time to think of possible approaches. What are some other sentences you might run into. What are all your options?
Hint 10
When are words that should be lowercase not? Why not? What are the ideal cases we'd want in our dictionary?
Hint 11
Here are a few options:
- Only make a word uppercase in our dictionary if it is always uppercase in the original string.
- Make a word uppercase in our dictionary if it is ever uppercase in the original string.
- Make a word uppercase in our dictionary if it is ever uppercase in the original string in a position that is not the first word of a sentence.
- Use an API or other tool that identifies proper nouns.
- Ignore case entirely and make every word lowercase.
What are the pros and cons for each one?
Hint 12
Pros and cons include:
- Only make a word uppercase in our dictionary if it is always uppercase in the original string: this will have reasonable accuracy in very long strings where words are more likely to be included multiple times, but words that only ever occur as the first word in a sentence will always be included as uppercase.
- Make a word uppercase in our dictionary if it is ever uppercase in the original string: this will ensure proper nouns are always uppercase, but any words that are ever at the start of sentences will always be uppercase too.
- Make a word uppercase in our dictionary if it is ever uppercase in the original string in a position that is not the first word of a sentence: this addresses the problem with option (2), but proper nouns that are only ever at the start of sentences will be made lowercase.
- Use an API or other tool that identifies proper nouns: this has a lot of potential to give us a high level of accuracy, but we'll give up control over decisions, we'll be relying on code we didn't write, and our practical runtime may be significantly increased.
- Ignore case entirely and make every word lowercase: this will give us simplicity and consistency, but we'll lose all accuracy for words that should be uppercase.
Any of these could be considered reasonable. Importantly, none of them are perfect. They all have tradeoffs, and it is very difficult to write a highly accurate algorithm. Consider "cliff" and "bill" in these sentences:
"Cliff finished his cake and paid the bill."
"Bill finished his cake at the edge of the cliff."
You can choose whichever of the options you'd like, or another option you thought of. For this breakdown, we're going to choose option (1).
Now, how do we update our add_word_to_dictionary() function to avoid duplicate words?
Hint 13
Think about the different possibilities:
- The word is uppercase or lowercase.
- The word is already in the dictionary or not.
- A different case of the word is already in the dictionary or not.
Hint 14
Moving forward, we can either:
- Check for words that are in the dictionary in both cases when we're done populating the dictionary. If we add "Vanilla" three times and "vanilla" eight times, we'll combine them into one "vanilla" at the end with a value 11.
- *Avoid ever having a word in our dictionary that's both uppercase and lowercase. As we add "Vanilla"s and "vanilla"s, we'd always only ever have one version* in our dictionary.
We'll choose the second approach since it will save us a walk through our dictionary. How should we start?
Hint 15
If the word we're adding is already in the dictionary in its current case, let's increment its count. What if it's not in the dictionary?
Hint 16
There are three possibilities:
- A lowercase version is in the dictionary (in which case we know our input word is uppercase, because if it is lowercase and already in the dictionary it would have passed our first check and we'd have just incremented its count)
- An uppercase version is in the dictionary (so we know our input word is lowercase)
- The word is not in the dictionary in any case
Let's start with the first possibility. What do we want to do?
Hint 17
Because we only include a word as uppercase if it is always uppercase, we simply increment the lowercase version's count.
# Current dictionary
# {'blue': 3}
# Adding
# 'Blue'
# Code
words_to_counts[word.lower()] += 1
# Updated dictionary
# {'blue': 4}
What about the second possibility?
Hint 18
This is a little more complicated. We need to remove the uppercase version from our dictionary if we encounter a lowercase version. But we still need the uppercase version's count!
# Current dictionary
# {'Yellow': 6}
# Adding
# 'yellow'
# Code (we will write our "capitalize()" method later)
words_to_counts[word] = 1
words_to_counts[word] += words_to_counts[word.capitalize()]
del words_to_counts[word.capitalize()]
# Updated dictionary
# {'yellow': 7}
Finally, what if the word is not in the dictionary at all?
Hint 19
Easy—-we add it and give it a count of 1.
# Current dictionary
# {'purple': 2}
# Adding
# 'indigo'
# Code
words_to_counts[word] = 1
# Updated dictionary
# {'purple': 2, 'indigo': 1}
Now we have all our pieces! We can split words, add them to a dictionary, and track the number of times each word occurs without having duplicate words of the same case. Can we improve our solution?
Hint 20
Let's look at our runtime and space cost. We iterate through every character in the input string once and then every word in our array once. That's a runtime of , which is the best we can achieve for this challenge (we have to look at the entire input string). The space we're using includes an array for each word and a dictionary for every unique word. Our worst case is that every word is different, so our space cost is also , which is also the best we can achieve for this challenge (we have to return a dictionary of words).
But we can still make some optimizations!
How can we make our space cost even smaller?
Hint 21
We're storing all our split words in a separate list. That at least doubles the memory we use! How can we eliminate the need for that list?
Hint 22
Right now, we store each word in our list as we split them. Instead, let's just immediately populate each word in our dictionary!
Hint 23 (solution)
Solution
In our solution, we make three decisions:
- We use a class. This allows us to tie our methods together, calling them on instances of our class instead of passing references.
- To handle duplicate words with different cases, we choose to make a word uppercase in our dictionary only if it is always uppercase in the original string. While this is a reasonable approach, it is imperfect (consider proper nouns that are also lowercase words, like "Bill" and "bill").
- We build our own
split_words()method instead of using a built-in one. This allows us to pass each word to ouradd_word_to_dictionary()method as it was split, and to split words and eliminate punctuation in one iteration.
To split the words in the input string and populate a dictionary of the unique words to the number of times they occurred, we:
- Split words by spaces, em dashes, and ellipses—-making sure to include hyphens surrounded by characters. We also include all apostrophes (which will handle contractions nicely but will break possessives into separate words).
- Populate the words in our dictionary as they are identified, checking if the word is already in our dictionary in its current case or another case.
If the input word is uppercase and there's a lowercase version in the dictionary, we increment the lowercase version's count. If the input word is lowercase and there's an uppercase version in the dictionary, we "demote" the uppercase version by adding the lowercase version and giving it the uppercase version's count.
class WordCloudData:
def __init__(self, input_string):
self.words_to_counts = {}
self.populate_words_to_counts(input_string)
def populate_words_to_counts(self, input_string):
# Iterates over each character in the input string, splitting
# words and passing them to add_word_to_dictionary()
current_word_start_index = 0
current_word_length = 0
for i, character in enumerate(input_string):
# If we reached the end of the string we check if the last
# character is a letter and add the last word to our dictionary
if i == len(input_string) - 1:
if character.isalpha():
current_word_length += 1
if current_word_length > 0:
current_word = input_string[current_word_start_index:
current_word_start_index + current_word_length]
self.add_word_to_dictionary(current_word)
# If we reach a space or emdash we know we're at the end of a word
# so we add it to our dictionary and reset our current word
elif character == ' ' or character == '\u2014':
if current_word_length > 0:
current_word = input_string[current_word_start_index:
current_word_start_index + current_word_length]
self.add_word_to_dictionary(current_word)
current_word_length = 0
# We want to make sure we split on ellipses so if we get two periods in
# a row we add the current word to our dictionary and reset our current word
elif character == '.':
if i < len(input_string) - 1 and input_string[i + 1] == '.':
if current_word_length > 0:
current_word = input_string[current_word_start_index:
current_word_start_index + current_word_length]
self.add_word_to_dictionary(current_word)
current_word_length = 0
# If the character is a letter or an apostrophe, we add it to our current word
elif character.isalpha() or character == '\'':
if current_word_length == 0:
current_word_start_index = i
current_word_length += 1
# If the character is a hyphen, we want to check if it's surrounded by letters
# If it is, we add it to our current word
elif character == '-':
if i > 0 and input_string[i - 1].isalpha() and \
input_string[i + 1].isalpha():
current_word_length += 1
else:
if current_word_length > 0:
current_word = input_string[current_word_start_index:
current_word_start_index + current_word_length]
self.add_word_to_dictionary(current_word)
current_word_length = 0
def add_word_to_dictionary(self, word):
# If the word is already in the dictionary we increment its count
if word in self.words_to_counts:
self.words_to_counts[word] += 1
# If a lowercase version is in the dictionary, we know our input word must be uppercase
# but we only include uppercase words if they're always uppercase
# so we just increment the lowercase version's count
elif word.lower() in self.words_to_counts:
self.words_to_counts[word.lower()] += 1
# If an uppercase version is in the dictionary, we know our input word must be lowercase.
# since we only include uppercase words if they're always uppercase, we add the
# lowercase version and give it the uppercase version's count
elif word.capitalize() in self.words_to_counts:
self.words_to_counts[word] = 1
self.words_to_counts[word] += self.words_to_counts[word.capitalize()]
del self.words_to_counts[word.capitalize()]
# Otherwise, the word is not in the dictionary at all, lowercase or uppercase
# so we add it to the dictionary
else:
self.words_to_counts[word] = 1
Complexity
Runtime and memory cost are both . This is the best we can do because we have to look at every character in the input string and we have to return a map of every unique word. We optimized to only make one pass over our input and have only one data structure.
Bonus
- We haven't explicitly talked about how to handle more complicated character sets. How would you make your solution work with more unicode characters? What changes need to be made to handle silly sentences like these:
I'm singing ♬ on a ☔ day.
☹ + ☕ = ☺.
- We limited our input to letters, hyphenated words and punctuation. How would you expand your functionality to include numbers, email addresses, twitter handles, etc.?
- How would you add functionality to identify phrases or words that belong together but aren't hyphenated? ("Fire truck" or "Interview Cake")
- How could you improve your capitalization algorithm?
- How would you avoid having duplicate words that are just plural or singular possessives?
What We Learned
To handle capitalized words, there were lots of heuristics and approaches we could have used, each with their own strengths and weaknesses. Open-ended questions like this can really separate good engineers from great engineers.
Good engineers will come up with a solution, but great engineers will come up with several solutions, weigh them carefully, and choose the best solution for the given context. So as you're running practice questions, challenge yourself to keep thinking even after you have a first solution. See how many solutions you can come up with. This will grow your ability to quickly see multiple ways to solve a problem, so you can figure out the best solution. And use the hints and gotchas on each Interview Cake question-—they're designed to help you cultivate this skill.