Dynamic Programming and Recursion
Introduction
Readings
Overlapping Subproblems
A problem has overlapping subproblems if finding its solution involves solving the same subproblem multiple times.
As an example, let's look at the Fibonacci sequence (the series where each number is the sum of the two previous ones—0, 1, 1, 2, 3, 5, 8, ...).
If we wanted to compute the th Fibonacci number, we could use this simple recursive algorithm:
function fib(n) {
if (n === 0 || n === 1) {
return n;
}
return fib(n-1) + fib(n-2);
}
We'd call fib(n-1) and fib(n-2) subproblems of fib(n).
Now let's look at what happens when we call fib(5):
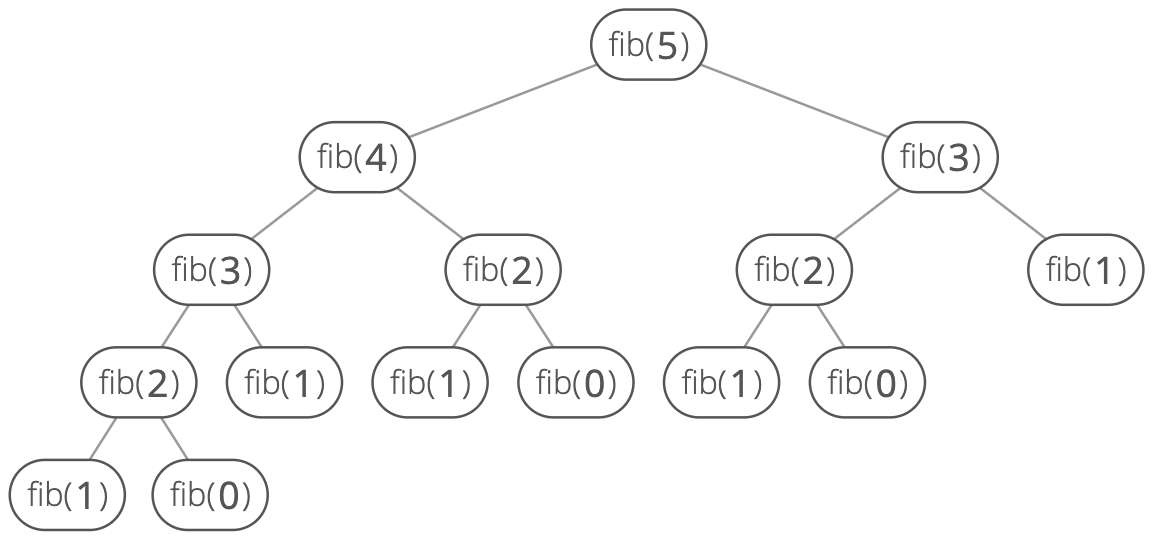
Our function ends up recursively calling fib(2) three times. So the problem of finding the th Fibonacci number has overlapping subproblems.
Memoization
Memoization ensures that a function doesn't run for the same inputs more than once by keeping a record of the results for the given inputs (usually in an object). For example, a simple recursive function for computing the th Fibonacci number:
function fib(n) {
if (n < 0) {
throw new Error(
'Index was negative. No such thing as a negative index in a series.');
}
// Base cases
if (n === 0 || n === 1) {
return n;
}
console.log(`computing fib(${n})`);
return fib(n - 1) + fib(n - 2);
}
Will run on the same inputs multiple times:
❯ fib(5)
computing fib(5)
computing fib(4)
computing fib(3)
computing fib(2)
computing fib(2)
computing fib(3)
computing fib(2)
❮ 5
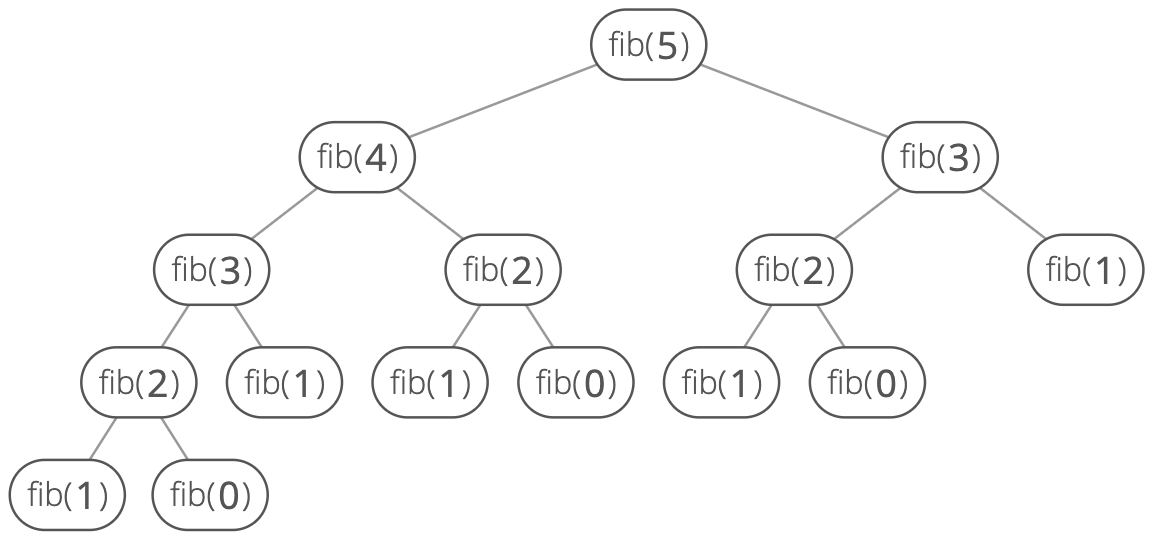
We can imagine the recursive calls of this function as a tree, where the two children of a node are the two recursive calls it makes. We can see that the tree quickly branches out of control:
To avoid the duplicate work caused by the branching, we can wrap the function in a class that stores an instance property, memo, that maps inputs to outputs. Then we simply
- check
memoto see if we can avoid computing the answer for any given input, and - save the results of any calculations to
memo.
class Fibber {
constructor() {
this.memo = {};
}
fib(n) {
if (n < 0) {
throw new Error('Index was negative. No such thing as a negative index in a series.');
// Base cases
} else if (n === 0 || n === 1) {
return n;
}
// See if we've already calculated this
if (this.memo.hasOwnProperty(n)) {
console.log(`grabbing memo[${n}]`);
return this.memo[n];
}
console.log(`computing fib(${n})`);
const result = this.fib(n - 1) + this.fib(n - 2);
// Memoize
this.memo[n] = result;
return result;
}
}
We save a bunch of calls by checking the memo:
❯ new Fibber().fib(5)
computing fib(5)
computing fib(4)
computing fib(3)
computing fib(2)
grabbing memo[2]
grabbing memo[3]
❯ 5
Now in our recurrence tree, no node appears more than twice:
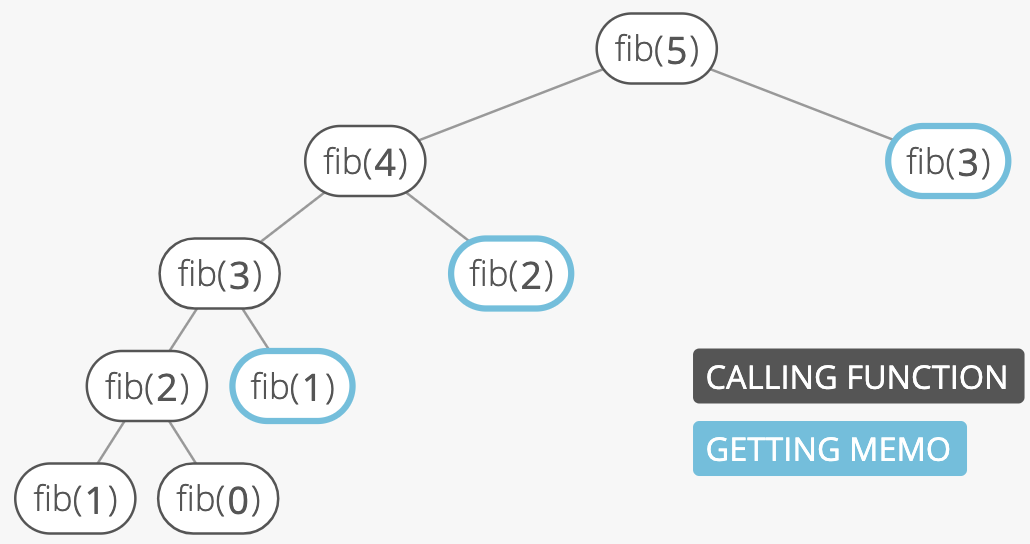
Memoization is a common strategy for dynamic programming problems, which are problems where the solution is composed of solutions to the same problem with smaller inputs (as with the Fibonacci problem, above). The other common strategy for dynamic programming problems is going bottom-up, which is usually cleaner and often more efficient.
Bottom-Up Algorithms
Going bottom-up is a way to avoid recursion, saving the memory cost that recursion incurs when it builds up the call stack. Put simply, a bottom-up algorithm "starts from the beginning," while a recursive algorithm often "starts from the end and works backwards." For example, if we wanted to multiply all the numbers in the range 1 to , we could use this cute, top-down, recursive one-liner:
function product1ToN(n) {
// We assume n >= 1
return (n > 1) ? (n * product1ToN(n-1)) : 1;
}
This approach has a problem: it builds up a call stack of size , which makes our total memory cost . This makes it vulnerable to a stack overflow error, where the call stack gets too big and runs out of space. To avoid this, we can instead go bottom-up:
function product1ToN(n) {
// We assume n >= 1
let result = 1;
for (let num = 1; num <= n; num++) {
result *= num;
}
return result;
}
This approach uses space ( time).
Some compilers and interpreters will do what's called tail call optimization (TCO), where it can optimize some recursive functions to avoid building up a tall call stack. Python and Java decidedly do not use TCO. Some Ruby implementations do, but most don't. Some C implementations do, and the JavaScript spec recently allowed TCO. Scheme is one of the few languages that guarantee TCO in all implementations. In general, best not to assume your compiler/interpreter will do this work for you.
Going bottom-up is a common strategy for dynamic programming problems, which are problems where the solution is composed of solutions to the same problem with smaller inputs (as with multiplying the numbers 1 to above). The other common strategy for dynamic programming problems is memoization.
Practice
Recursive String Permutations
Write a recursive function for generating all permutations of an input string. Return them as a set.
Don't worry about time or space complexity—-if we wanted efficiency we'd write an iterative version.
To start, assume every character in the input string is unique.
Your function can have loops—-it just needs to also be recursive.
Hint 1
Let's break the problem into subproblems. How could we re-phrase the problem of getting all permutations for "cats" in terms of a smaller but similar subproblem?
Hint 2
Let's make our subproblem be getting all permutations for all characters except the last one. If we had all permutations for "cat," how could we use that to generate all permutations for "cats"?
Hint 3
We could put the "s" in each possible position for each possible permutation of "cat"!
These are our permutations of "cat":
cat
cta
atc
act
tac
tca
For each of them, we add "s" in each possible position. So for "cat":
cat
scat
csat
cast
cats
And for "cta":
cta
scta
csta
ctsa
ctas
And so on.
Hint 4
Now that we can break the problem into subproblems, we just need a base case and we have a recursive algorithm!
Hint 5 (solution)
If we're making all permutations for "cat," we take all permutations for "ca" and then put "t" in each possible position in each of those permutations. We use this approach recursively:
def get_permutations(string):
# Base case
if len(string) <= 1:
return set([string])
all_chars_except_last = string[:-1]
last_char = string[-1]
# Recursive call: get all possible permutations for all chars except last
permutations_of_all_chars_except_last = get_permutations(all_chars_except_last)
# Put the last char in all possible positions for each of
# the above permutations
permutations = set()
for permutation_of_all_chars_except_last in permutations_of_all_chars_except_last:
for position in range(len(all_chars_except_last) + 1):
permutation = (
permutation_of_all_chars_except_last[:position]
+ last_char
+ permutation_of_all_chars_except_last[position:]
)
permutations.add(permutation)
return permutations
Bonus
How does the problem change if the string can have duplicate characters?
What if we wanted to bring down the time and/or space costs?
What We Learned
This is one where playing with a sample input is huge. Sometimes it helps to think of algorithm design as a two-part process: first figure out how you would solve the problem "by hand," as though the input was a stack of paper on a desk in front of you. Then translate that process into code.
Compute the nth Fibonacci Number
Write a function fib() that takes an integer and returns the th Fibonacci number.
Let's say our Fibonacci series is 0-indexed and starts with 0. So:
fib(0) # => 0
fib(1) # => 1
fib(2) # => 1
fib(3) # => 2
fib(4) # => 3
...
Hint 1
The th Fibonacci number is defined in terms of the two previous Fibonacci numbers, so this seems to lend itself to recursion.
fib(n) = fib(n - 1) + fib(n - 2)
Can you write up a recursive solution?
Hint 2
As with any recursive function, we just need a base case and a recursive case:
- Base case: is 0 or 1. Return .
- Recursive case: Return
fib(n - 1) + fib(n - 2)
def fib(n):
if n in [1, 0]:
return n
return fib(n - 1) + fib(n - 2)
Okay, this'll work! What's our time complexity?
Hint 3
It's not super obvious. We might guess , but that's not quite right. Can you see why?
Hint 4
Each call to fib() makes two more calls. Let's look at a specific example. Let's say . If we call fib(5), how many calls do we make in total?
Hint 5
Try drawing it out as a tree where each call has two child calls, unless it's a base case.
Hint 6
Here's what the tree looks like:
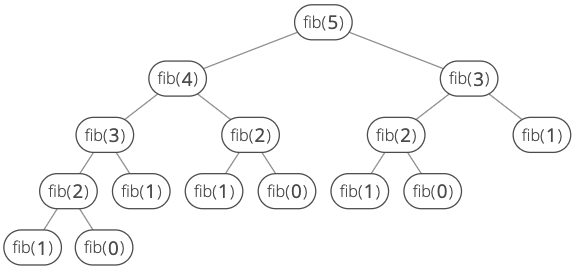
We can notice this is a binary tree whose height is , which means the total number of nodes is .
So our total runtime is . That's an "exponential time cost," since the is in an exponent. Exponential costs are terrible. This is way worse than or even .
Our recurrence tree above essentially gets twice as big each time we add 1 to . So as gets really big, our runtime quickly spirals out of control.
The craziness of our time cost comes from the fact that we're doing so much repeat work. How can we avoid doing this repeat work?
Hint 7
We can memoize!
Let's wrap fib() in a class with an instance variable where we store the answer for any that we compute:
class Fibber(object):
def __init__(self):
self.memo = {}
def fib(self, n):
if n < 0:
# Edge case: negative index
raise ValueError('Index was negative. No such thing as a '
'negative index in a series.')
elif n in [0, 1]:
# Base case: 0 or 1
return n
# See if we've already calculated this
if n in self.memo:
return self.memo[n]
result = self.fib(n - 1) + self.fib(n - 2)
# Memoize
self.memo[n] = result
return result
What's our time cost now?
Hint 8
Our recurrence tree will look like this:
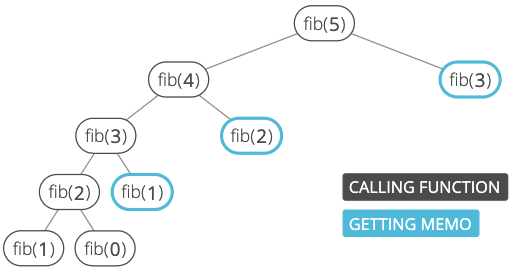
The computer will build up a call stack with fib(5), fib(4), fib(3), fib(2), fib(1). Then we'll start returning, and on the way back up our tree we'll be able to compute each node's 2nd call to fib() in constant time by just looking in the memo. time in total.
What about space? memo takes up space. Plus we're still building up a call stack that'll occupy space. Can we avoid one or both of these space expenses?
Hint 9
Look again at that tree. Notice that to calculate fib(5) we worked "down" to fib(4), fib(3), fib(2), etc.
What if instead we started with fib(0) and fib(1) and worked "up" to ?
Hint 10
We use a bottom-up approach, starting with the 0th Fibonacci number and iteratively computing subsequent numbers until we get to .
def fib(n):
# Edge cases:
if n < 0:
raise ValueError('Index was negative. No such thing as a '
'negative index in a series.')
elif n in [0, 1]:
return n
# We'll be building the fibonacci series from the bottom up
# so we'll need to track the previous 2 numbers at each step
prev_prev = 0 # 0th fibonacci
prev = 1 # 1st fibonacci
for _ in range(n - 1):
# Iteration 1: current = 2nd fibonacci
# Iteration 2: current = 3rd fibonacci
# Iteration 3: current = 4th fibonacci
# To get nth fibonacci ... do n-1 iterations.
current = prev + prev_prev
prev_prev = prev
prev = current
return current
Complexity
time and space.
Bonus
If you're good with matrix multiplication you can bring the time cost down even further, to . Can you figure out how?
What We Learned
This one's a good illustration of the tradeoff we sometimes have between code cleanliness and efficiency.
We could use a cute, recursive function to solve the problem. But that would cost time as opposed to nn time in our final bottom-up solution. Massive difference!
In general, whenever you have a recursive solution to a problem, think about what's actually happening on the call stack. An iterative solution might be more efficient.
Making Change
Your quirky boss collects rare, old coins...
They found out you're a programmer and asked you to solve something they've been wondering for a long time.
Write a function that, given:
- an
amountof money - a list of coin
denominations
computes the number of ways to make the amount of money with coins of the available denominations.
Example: for amount=4 (4¢) and denominations=[1,2,3] (1¢, 2¢ and 3¢), your program would output 4—-the number of ways to make 4¢ with those denominations:
- 1¢, 1¢, 1¢, 1¢
- 1¢, 1¢, 2¢
- 1¢, 3¢
- 2¢, 2¢
Hint 1
We need to find some way to break this problem down into subproblems.
Hint 2
Here's one way: for each denomination, we can use it once, or twice, or...as many times as it takes to reach or overshoot the amount with coins of that denomination alone.
Hint 3
For each of those choices of how many times to include coins of each denomination, we're left with the subproblem of seeing how many ways we can get the remaining amount from the remaining denominations.
Here's that approach in pseudocode:
def number_of_ways(amount, denominations):
answer = 0
for each denomination in denominations:
for each num_times_to_use_denomination in \
possible_num_times_to_use_denomination_without_overshooting_amount:
answer += number_of_ways(amount_remaining, other_denominations)
return answer
The answer for some of those subproblems will of course be 0. For example, there's no way to get 1¢ with only 2¢ coins.
Hint 4
As a recursive function, we could formalize this as:
def change_possibilities_top_down(amount_left, denominations, current_index=0):
# Base cases:
# We hit the amount spot on. yes!
if amount_left == 0:
return 1
# We overshot the amount left (used too many coins)
if amount_left < 0:
return 0
# We're out of denominations
if current_index == len(denominations):
return 0
print("checking ways to make %i with %s" % (
amount_left,
denominations[current_index:],
))
# Choose a current coin
current_coin = denominations[current_index]
# See how many possibilities we can get
# for each number of times to use current_coin
num_possibilities = 0
while amount_left >= 0:
num_possibilities += change_possibilities_top_down(
amount_left,
denominations,
current_index + 1,
)
amount_left -= current_coin
return num_possibilities
But there's a problem-—we'll often duplicate the work of checking remaining change possibilities. Note the duplicate calls with the input 4, [1,2,3]:
>>> change_possibilities_top_down(4, [1, 2, 3])
checking ways to make 4 with [1, 2, 3]
checking ways to make 4 with [2, 3]
checking ways to make 4 with [3]
checking ways to make 2 with [3]
checking ways to make 3 with [2, 3]
checking ways to make 3 with [3]
checking ways to make 1 with [3]
checking ways to make 2 with [2, 3]
checking ways to make 2 with [3]
checking ways to make 1 with [2, 3]
checking ways to make 1 with [3]
4
For example, we check ways to make 2 with [3] twice.
We can do better. How do we avoid this duplicate work and bring down the time cost?
Hint 5
One way is to memoize.
Hint 6
Here's what the memoization might look like:
class Change(object):
def __init__(self):
self.memo = {}
def change_possibilities_top_down(self, amount_left, denominations,
current_index=0):
# Check our memo and short-circuit if we've already solved this one
memo_key = str((amount_left, current_index))
if memo_key in self.memo:
print("grabbing memo[%s]" % memo_key)
return self.memo[memo_key]
# Base cases:
# We hit the amount spot on. yes!
if amount_left == 0:
return 1
# We overshot the amount left (used too many coins)
if amount_left < 0:
return 0
# We're out of denominations
if current_index == len(denominations):
return 0
print("checking ways to make %i with %s" % (
amount_left,
denominations[current_index:],
))
# Choose a current coin
current_coin = denominations[current_index]
# See how many possibilities we can get
# for each number of times to use current_coin
num_possibilities = 0
while amount_left >= 0:
num_possibilities += self.change_possibilities_top_down(
amount_left,
denominations,
current_index + 1,
)
amount_left -= current_coin
# Save the answer in our memo so we don't compute it again
self.memo[memo_key] = num_possibilities
return num_possibilities
And now our checking has no duplication:
>>> Change().change_possibilities_top_down(4, [1, 2, 3])
checking ways to make 4 with [1, 2, 3]
checking ways to make 4 with [2, 3]
checking ways to make 4 with [3]
checking ways to make 2 with [3]
checking ways to make 3 with [2, 3]
checking ways to make 3 with [3]
checking ways to make 1 with [3]
checking ways to make 2 with [2, 3]
grabbing memo[(2, 2)]
checking ways to make 1 with [2, 3]
grabbing memo[(1, 2)]
4
This answer is quite good. It certainly solves our duplicate work problem. It takes time and space, where is the size of amount and is the number of items in denominations. (Except we'd need to remove the line where we log "checking ways to make..." because making all those sublists will take space!)
However, we can do better. Because our method is recursive it will build up a large call stack of size . Of course, this cost is eclipsed by the memory cost of memo, which is . But it's still best to avoid building up a large stack like this, because it can cause a stack overflow (yes, that means recursion is usually better to avoid for functions that might have arbitrarily large inputs).
It turns out we can get additional space.
Hint 7
A great way to avoid recursion is to go bottom-up.
Hint 8
Our recursive approach was top-down because it started with the final value for amount and recursively broke the problem down into subproblems with smaller values for amount. What if instead we tried to compute the answer for small values of amount first, and use those answers to iteratively compute the answer for higher values until arriving at the final amount?
Hint 9
We can start by making a list ways_of_doing_n_cents, where the index is the amount and the value at each index is the number of ways of getting that amount.
This list will take space, where is the size of amount.
Hint 10
To further simplify the problem, we can work with only the first coin in denominations, then add in the second coin, then the third, etc.
What would ways_of_doing_n_cents look like for just our first coin: 1¢? Let's call this ways_of_doing_n_cents_1.
ways_of_doing_n_cents_1 = [
1, # 0c: no coins
1, # 1c: 1 1c coin
1, # 2c: 2 1c coins
1, # 3c: 3 1c coins
1, # 4c: 4 1c coins
1, # 5c: 5 1c coins
]
Now what if we add a 2¢ coin?
ways_of_doing_n_cents_1_2 = [
1, # 0c: no change
1, # 1c: no change
1 + 1, # 2c: new [(2)]
1 + 1, # 3c: new [(2,1)]
1 + 2, # 4c: new [(2, 1, 1), (2, 2)]
1 + 2, # 5c: new [(2, 1, 1, 1), (2, 2, 1)]
]
How do we formalize this process of going from ways_of_doing_n_cents_1 to ways_of_doing_n_cents_1_2?
Hint 11
Let's suppose we're partway through already (this is a classic dynamic programming approach). Say we're trying to calculate ways_of_doing_n_cents_1_2[5]. Because we're going bottom-up, we know we already have:
ways_of_doing_n_cents_1_2for amounts less than 5- a fully-populated
ways_of_doing_n_cents_1
So how many new ways should we add to ways_of_doing_n_cents_1[5] to get ways_of_doing_n_cents_1_2[5]?
Hint 12
Well, if there are any new ways to get 5¢ now that we have 2¢ coins, those new ways must involve at least one 2¢ coin. So if we presuppose that we'll use one 2¢ coin, that leaves us with left to come up with. We already know how many ways we can get 3¢ with 1¢ and 2¢ coins: ways_of_doing_n_cents_1_2[3], which is 2.
So we can see that:
ways_of_doing_n_cents_1_2[5] = ways_of_doing_n_cents_1[5] + ways_of_doing_n_cents_1_2[5 - 2]
Why don't we also need to check ways_of_doing_n_cents_1_2[5 - 2 - 2] (two 2¢ coins)? Because we already checked ways_of_doing_n_cents_1_2[1] when calculating ways_of_doing_n_cents_1_2[3]. We'd be counting some arrangements multiple times. In other words, ways_of_doing_n_cents_1_2[k] already includes the full count of possibilities for getting , including possibilities that use 2¢ any number of times. We're only interested in how many more possibilities we might get when we go from to and thus have the ability to add one more 2¢ coin to each of the possibilities we have for .
Hint 13 (solution)
Solution
We use a bottom-up algorithm to build up a table ways_of_doing_n_cents such that ways_of_doing_n_cents[k] is how many ways we can get to cents using our denominations. We start with the base case that there's one way to create the amount zero, and progressively add each of our denominations.
The number of new ways we can make a higher_amount when we account for a new coin is simply ways_of_doing_n_cents[higher_amount - coin], where we know that value already includes combinations involving coin (because we went bottom-up, we know smaller values have already been calculated).
def change_possibilities_bottom_up(amount, denominations):
ways_of_doing_n_cents = [0] * (amount + 1)
ways_of_doing_n_cents[0] = 1
for coin in denominations:
for higher_amount in range(coin, amount + 1):
higher_amount_remainder = higher_amount - coin
ways_of_doing_n_cents[higher_amount] += (
ways_of_doing_n_cents[higher_amount_remainder]
)
return ways_of_doing_n_cents[amount]
Here's how ways_of_doing_n_cents would look in successive iterations of our function for amount=5 and denominations=[1,3,5].
===========
key:
a = higher_amount
r = higher_amountRemainder
===========
============
for coin = 1:
============
[1, 1, 0, 0, 0, 0]
r a
[1, 1, 1, 0, 0, 0]
r a
[1, 1, 1, 1, 0, 0]
r a
[1, 1, 1, 1, 1, 0]
r a
[1, 1, 1, 1, 1, 1]
r a
============
for coin = 3:
=============
[1, 1, 1, 2, 1, 1]
r a
[1, 1, 1, 2, 2, 1]
r a
[1, 1, 1, 2, 2, 2]
r a
============
for coin = 5:
=============
[1, 1, 1, 2, 2, 3]
r a
final answer: 3
Complexity
time and additional space, where is the amount of money and is the number of potential denominations.
What We Learned
This question is in a broad class called "dynamic programming." We have a bunch more dynamic programming questions we'll go over later.
Dynamic programming is kind of like the next step up from greedy. You're taking that idea of "keeping track of what we need in order to update the best answer so far," and applying it to situations where the new best answer so far might not just have to do with the previous answer, but some other earlier answer as well.
So as you can see in this problem, we kept track of all of our previous answers to smaller versions of the problem (called "subproblems") in a big list called ways_of_doing_n_cents.
Again, same idea of keeping track of what we need in order to update the answer as we go, like we did when storing the max product of 2, min product of 2, etc in the highest product of 3 question. Except now the thing we need to keep track of is all our previous answers, which we're keeping in a list.
We built that list bottom-up, but we also talked about how we could do it top-down and memoize. Going bottom-up is cleaner and usually more efficient, but often it's easier to think of the top-down version first and try to adapt from there.
Dynamic programming is a weak point for lots of candidates. If this one was tricky for you, don't fret. We have more coming later.
The Cake Thief
You are a renowned thief who has recently switched from stealing precious metals to stealing cakes because of the insane profit margins. You end up hitting the jackpot, breaking into the world's largest privately owned stock of cakes—-the vault of the Queen of England.
While Queen Elizabeth has a limited number of types of cake, she has an unlimited supply of each type.
Each type of cake has a weight and a value, stored in an object with two properties:
weight: the weight of the cake in kilogramsvalue: the monetary value of the cake in British shillings
For example:
# Weighs 7 kilograms and has a value of 160 shillings
(7, 160)
# Weighs 3 kilograms and has a value of 90 shillings
(3, 90)
You brought a duffel bag that can hold limited weight, and you want to make off with the most valuable haul possible.
Write a function max_duffel_bag_value() that takes a list of cake type objects and a weight capacity, and returns the maximum monetary value the duffel bag can hold.
For example:
cake_tuples = [(7, 160), (3, 90), (2, 15)]
capacity = 20
# Returns 555 (6 of the middle type of cake and 1 of the last type of cake)
max_duffel_bag_value(cake_tuples, capacity)
Weights and values may be any non-negative integer. Yes, it's weird to think about cakes that weigh nothing or duffel bags that can't hold anything. But we're not just super mastermind criminals—-we're also meticulous about keeping our algorithms flexible and comprehensive.
Hint 1
The brute force approach is to try every combination of cakes, but that would take a really long time-—you'd surely be captured.
What if we just look at the cake with the highest value?
Hint 2
We could keep putting the cake with the highest value into our duffel bag until adding one more would go over our weight capacity. Then we could look at the cake with the second highest value, and so on until we find a cake that's not too heavy to add.
Will this work?
Hint 3
Nope. Let's say our capacity is 100 kg and these are our two cakes:
[(1, 30), (50, 200)]
With our approach, we'll put in two of the second type of cake for a total value of 400 shillings. But we could have put in a hundred of the first type of cake, for a total value of 3000 shillings!
Just looking at the cake's values won't work. Can we improve our approach?
Hint 4
Well, why didn't it work?
Hint 5
We didn't think about the weight! How can we factor that in?
Hint 6
What if instead of looking at the value of the cakes, we looked at their value/weight ratio? Here are our example cakes again:
[(1, 30), (50, 200)]
The second cake has a higher value, but look at the value per kilogram.
The second type of cake is worth 4 shillings/kg (200/50), but the first type of cake is worth 30 shillings/kg (30/1)!
Ok, can we just change our algorithm to use the highest value/weight ratio instead of the highest value? We know it would work in our example above, but try some more tests to be safe.
Hint 7
We might run into problems if the weight of the cake with the highest value/weight ratio doesn't fit evenly into the capacity. Say we have these two cakes:
[(3, 40), (5, 70)]
If our capacity is 8 kg, no problem. Our algorithm chooses one of each cake, giving us a haul worth 110 shillings, which is optimal.
But if the capacity is 9 kg, we're in trouble. Our algorithm will again choose one of each cake, for a total value of 110 shillings. But the actual optimal value is 120 shillings-—three of the first type of cake!
So even looking at the value/weight ratios doesn't always give us the optimal answer!
Let's step back. How can we ensure we get the optimal value we can carry?
Hint 8
Try thinking small. How can we calculate the maximum value for a duffel bag with a weight capacity of 1 kg? (Remember, all our weights and values are integers.)
Hint 9
If the capacity is 1 kg, we'll only care about cakes that weigh 1 kg (for simplicity, let's ignore zeroes for now). And we'd just want the one with the highest value.
We could go through every cake, using a greedy approach to keep track of the max value we've seen so far.
Hint 10
Here's an example solution:
def max_duffel_bag_value_with_capacity_1(cake_tuples):
max_value_at_capacity_1 = 0
for cake_weight, cake_value in cake_tuples:
if cake_weight == 1:
max_value_at_capacity_1 = max(max_value_at_capacity_1, cake_value)
return max_value_at_capacity_1
Ok, now what if the capacity is 2 kg? We'll need to be a bit more clever.
Hint 11
It's pretty similar. Again we'll track a max value, let's say with a variable max_value_at_capacity_2. But now we care about cakes that weigh 1 or 2 kg. What do we do with each cake? And keep in mind, we can lean on the code we used to get the max value at weight capacity 1 kg.
Hint 12
- If the cake weighs 2 kg, it would fill up our whole capacity if we just took one. So we just need to see if the cake's value is higher than our current
max_value_at_capacity_2. - If the cake weighs 1 kg, we could take one, and we'd still have 1 kg of capacity left. How do we know the best way to fill that extra capacity? We can use the max value at capacity 1. We'll see if adding the cake's value to the max value at capacity 1 is better than our current
max_value_at_capacity_2.
Does this apply more generally? If we can use the max value at capacity 1 to get the max value at capacity 2, can we use the max values at capacity 1 and 2 to get the max value at capacity 3?
Looks like this problem might have overlapping subproblems!
Hint 13
Let's see if we can build up to the given weight capacity, one capacity at a time, using the max values from previous capacities. How can we do this?
Hint 14
Well, let's try one more weight capacity by hand—-3 kg. So we already know the max values at capacities 1 and 2. And just like we did with max_value_at_capacity_1 and max_value_at_capacity_2, now we'll track max_value_at_capacity_3 and loop through every cake:
max_value_at_capacity_3 = 0
for cake_weight, cake_value in cake_tuples:
# Only care about cakes that weigh 3 kg or less
...
What do we do for each cake?
Hint 15
If the current cake weighs 3 kg, easy—-we see if it's more valuable than our current max_value_at_capacity_3.
What if the current cake weighs 2 kg?
Hint 16
Well, let's see what our max value would be if we used the cake. How can we calculate that?
Hint 17
If we include the current cake, we can only carry 1 more kilogram. What would be the max value we can carry?
Hint 18
We already know the max_value_at_capacity_1! We can just add that to the current cake's value!
Hint 19
Now we can see which is higher-—our current max_value_at_capacity_3, or the new max value if we use the cake:
max_value_using_cake = max_value_at_capacity_1 + cake_value
max_value_at_capacity_3 = max(max_value_at_capacity_3, max_value_using_cake)
Finally, what if the current cake weighs 1 kg?
Hint 20
Basically the same as if it weighs 2 kg:
max_value_using_cake = max_value_at_capacity_2 + cake_value
max_value_at_capacity_3 = max(max_value_at_capacity_3, max_value_using_cake)
There's gotta be a pattern here. We can keep building up to higher and higher capacities until we reach our input capacity. Because the max value we can carry at each capacity is calculated using the max values at previous capacities, we'll need to solve the max value for every capacity from 0 up to our duffel bag's actual weight capacity.
Can we write a function to handle all the capacities?
Hint 21
To start, we'll need a way to store and update all the max monetary values for each capacity.
We could use an object, where the keys represent capacities and the values represent the max possible monetary values at those capacities. Objects are built on lists, so we can save some overhead by just using a list.
def max_duffel_bag_value(cake_tuples, weight_capacity):
# List to hold the maximum possible value at every
# integer capacity from 0 to weight_capacity
# starting each index with value 0
max_values_at_capacities = [0] * (weight_capacity + 1)
What do we do next?
Hint 22
We'll need to work with every capacity up to the input weight capacity. That's an easy loop:
# Every integer from 0 to the input weight_capacity
for current_capacity in range(weight_capacity + 1):
...
What will we do inside this loop? This is where it gets a little tricky.
Hint 23
We care about any cakes that weigh the current capacity or less. Let's try putting each cake in the bag and seeing how valuable of a haul we could fit from there.
Hint 24
So we'll write a loop through all the cakes (ignoring cakes that are too heavy to fit):
for cake_weight, cake_value in cake_tuples:
# If the cake weighs as much or less than the current capacity
# see what our max value could be if we took it!
if cake_weight <= current_capacity:
# Find max_value_using_cake
...
And put it in our function body so far:
def max_duffel_bag_value(cake_tuples, weight_capacity):
# We make a list to hold the maximum possible value at every
# duffel bag weight capacity from 0 to weight_capacity
# starting each index with value 0
max_values_at_capacities = [0] * (weight_capacity + 1)
for current_capacity in range(weight_capacity + 1):
for cake_weight, cake_value in cake_tuples:
# If the cake weighs as much or less than the current capacity
# see what our max value could be if we took it!
if cake_weight <= current_capacity:
# Find max_value_using_cake
...
How do we compute max_value_using_cake?
Hint 25
Remember when we were calculating the max value at capacity 3kg and we "hard-coded" the max_value_using_cake for cakes that weigh 3kg, 2kg, and 1kg?
# cake weighs 3 kg
max_value_using_cake = cake_value
# cake weighs 2 kg
max_value_using_cake = max_value_at_capacity_1 + cake_value
# cake weighs 1 kg
max_value_using_cake = max_value_at_capacity_2 + cake_value
How can we generalize this? With our new function body, look at the variables we have in scope:
max_values_at_capacitiescurrent_capacitycake_weightcake_value
Can we use these to get max_value_using_cake for any cake?
Hint 26
Well, let's figure out how much space would be left in the duffel bag after putting the cake in:
remaining_capacity_after_taking_cake = current_capacity - cake_weight
So max_value_using_cake is:
- the current cake's value, plus
- the best value we can fill the
remaining_capacity_after_taking_cakewith
remaining_capacity_after_taking_cake = current_capacity - cake_weight
max_value_using_cake = cake_value + max_values_at_capacities[remaining_capacity_after_taking_cake]
We can squish this into one line:
max_value_using_cake = cake_value + max_values_at_capacities[current_capacity - cake_weight]
Since remaining_capacity_after_taking_cake is a lower capacity, we'll have always already computed its max value and stored it in our max_values_at_capacities!
Now that we know the max value if we include the cake, should we include it? How do we know?
Hint 27
Let's allocate a variable current_max_value that holds the highest value we can carry at the current capacity. We can start it at zero, and as we go through all the cakes, any time the value using a cake is higher than current_max_value, we'll update current_max_value!
current_max_value = max(max_value_using_cake, current_max_value)
What do we do with each value for current_max_value? What do we need to do for each capacity when we finish looping through all the cakes?
Hint 28
We save each current_max_value in the max_values_at_capacities list. We'll also need to make sure we set current_max_value to zero in the right place in our loops—-we want it to reset every time we start a new capacity.
So here's our function so far:
def max_duffel_bag_value(cake_tuples, weight_capacity):
# We make a list to hold the maximum possible value at every
# duffel bag weight capacity from 0 to weight_capacity
# starting each index with value 0
max_values_at_capacities = [0] * (weight_capacity + 1)
for current_capacity in range(weight_capacity + 1):
# Set a variable to hold the max monetary value so far for
# the current weight capacity
current_max_value = 0
for cake_weight, cake_value in cake_tuples:
# If the current cake weighs as much or less than the
# current weight capacity it's possible taking the cake
# would get a better value
if cake_weight <= current_capacity:
# Should we use the cake or not?
# If we use the cake, the most kilograms we can include in
# addition to the cake we're adding is the current capacity
# minus the cake's weight. We find the max value at that
# integer capacity in our list max_values_at_capacities
max_value_using_cake = (
cake_value
+ max_values_at_capacities[current_capacity - cake_weight]
)
# Now we see if it's worth taking the cake. How does the
# value with the cake compare to the current_max_value?
current_max_value = max(max_value_using_cake,
current_max_value)
# Add each capacity's max value to our list so we can use them
# when calculating all the remaining capacities
max_values_at_capacities[current_capacity] = current_max_value
Looking good! But what's our final answer?
Hint 29
Our final answer is max_values_at_capacities[weight_capacity]!
Okay, this seems complete. What about edge cases?
Hint 30
Remember, weights and values can be any non-negative integer. What about zeroes? How can we handle duffel bags that can't hold anything and cakes that weigh nothing?
Hint 31
Well, if our duffel bag can't hold anything, we can just return 0. And if a cake weighs 0 kg, we return infinity. Right?
Hint 32
Not that simple!
What if our duffel bag holds 0 kg, and we have a cake that weighs 0 kg. What do we return?
Hint 33
And what if we have a cake that weighs 0 kg, but its value is also 0. If we have other cakes with positive weights and values, what do we return?
Hint 34
If a cake's weight and value are both 0, it's reasonable to not have that cake affect what we return at all.
If we have a cake that weighs 0 kg and has a positive value, it's reasonable to return infinity, even if the capacity is 0.
For returning infinity, we have several choices. We could return:
- Python's
float('inf'). - Return a custom response, like the string
'infinity'. - Raise an exception indicating the answer is infinity.
What are the advantages and disadvantages of each option?
Hint 35
For the first option the advantage is we get the behavior of infinity. Compared to any other integer, float('inf') will be greater. And it's a number, which can be an advantage or disadvantage—-we might want our result to always be the same type, but without manually checking we won't know if we mean an actual value or the special case of infinity.
For the second option the advantage is we can create a custom behavior that we—-or our function's users—-could know to expect. The disadvantage is we'd have to explicitly check for that behavior, otherwise we might end up trying to parse the string "infinity" as an integer, which could give us an error or (perhaps worse) a random number. In a production system, a function that sometimes returns an integer and sometimes returns a string would probably be seen as sloppy.
The third option is a good choice if we decide infinity is usually an "unacceptable" answer. For example, we might decide an infinite answer means we've probably entered our inputs wrong. Then, if we really wanted to "accept" an infinite answer, we could always "catch" this exception when we call our function.
Any option could be reasonable. We'll go with the first one here.
Hint 36 (solution)
Solution
This is a classic computer science puzzle called "the unbounded knapsack problem."
We use a bottom-up approach to find the max value at our duffel bag's weight_capacity by finding the max value at every capacity from 0 to weight_capacity.
We allocate a list max_values_at_capacities where the indices are capacities and each value is the max value at that capacity.
For each capacity, we want to know the max monetary value we can carry. To figure that out, we go through each cake, checking to see if we should take that cake.
The best monetary value we can get if we take a given cake is simply:
- that cake's value, plus
- the best monetary value we can carry in our remaining duffel bag capacity after taking the cake—-which we'll already have stored in
max_values_at_capacities
To handle weights and values of zero, we return infinity only if a cake weighs nothing and has a positive value.
def max_duffel_bag_value(cake_tuples, weight_capacity):
# We make a list to hold the maximum possible value at every
# duffel bag weight capacity from 0 to weight_capacity
# starting each index with value 0
max_values_at_capacities = [0] * (weight_capacity + 1)
for current_capacity in range(weight_capacity + 1):
# Set a variable to hold the max monetary value so far
# for current_capacity
current_max_value = 0
for cake_weight, cake_value in cake_tuples:
# If a cake weighs 0 and has a positive value the value of
# our duffel bag is infinite!
if cake_weight == 0 and cake_value != 0:
return float('inf')
# If the current cake weighs as much or less than the
# current weight capacity it's possible taking the cake
# would get a better value
if cake_weight <= current_capacity:
# So we check: should we use the cake or not?
# If we use the cake, the most kilograms we can include in
# addition to the cake we're adding is the current capacity
# minus the cake's weight. We find the max value at that
# integer capacity in our list max_values_at_capacities
max_value_using_cake = (
cake_value
+ max_values_at_capacities[current_capacity - cake_weight]
)
# Now we see if it's worth taking the cake. how does the
# value with the cake compare to the current_max_value?
current_max_value = max(max_value_using_cake,
current_max_value)
# Add each capacity's max value to our list so we can use them
# when calculating all the remaining capacities
max_values_at_capacities[current_capacity] = current_max_value
return max_values_at_capacities[weight_capacity]
Complexity
time, and space, where is number of types of cake and is the capacity of the duffel bag. We loop through each cake ( cakes) for every capacity ( capacities), so our runtime is , and maintaining the list of capacities gives us the space.
Congratulations! Because of dynamic programming, you have successfully stolen the Queen's cakes and made it big.
Keep in mind: in some cases, it might not be worth using our optimal dynamic programming solution. It's a pretty slow algorithm—-without any context (not knowing how many cake types we have, what our weight capacity is, or just how they compare) it's easy to see growing out of control quickly if or is large.
If we cared about time, like if there was an alarm in the vault and we had to move quickly, it might be worth using a faster algorithm that gives us a good answer, even if it's not always the optimal answer. Some of our first ideas in the breakdown were to look at cake values or value/weight ratios. Those algorithms would probably be faster, taking time (we'd have to start by sorting the input).
Sometimes an efficient, good answer might be more practical than an inefficient, optimal answer.
Bonus
- We know the max value we can carry, but which cakes should we take, and how many? Try adjusting your answer to return this information as well.
- What if we check to see if all the cake weights have a common denominator? Can we improve our algorithm?
- A cake that's both heavier and worth less than another cake would never be in the optimal solution. This idea is called dominance relations. Can you apply this idea to save some time? Hint: dominance relations can apply to sets of cakes, not just individual cakes.
- What if we had an object for every individual cake instead of types of cakes? So now there's not an unlimited supply of a type of cake-—there's exactly one of each. This is a similar but harder problem, known as the 0/1 Knapsack problem.
What We Learned
This question is our spin on the famous "unbounded knapsack problem"—-a classic dynamic programming question.
If you're struggling with dynamic programming, we have reference pages for the two main dynamic programming strategies: memoization and going bottom-up.
Balanced Binary Tree
Write a function to see if a binary tree is "superbalanced" (a new tree property we just made up).
A tree is "superbalanced" if the difference between the depths of any two leaf nodes is no greater than one. (A leaf node is a tree node with no children. It's the "end" of a path to the bottom, from the root.)
Here's a sample binary tree node class:
class BinaryTreeNode(object):
def __init__(self, value):
self.value = value
self.left = None
self.right = None
def insert_left(self, value):
self.left = BinaryTreeNode(value)
return self.left
def insert_right(self, value):
self.right = BinaryTreeNode(value)
return self.right
Hint 1
Sometimes it's good to start by rephrasing or "simplifying" the problem.
The requirement of "the difference between the depths of any two leaf nodes is no greater than 1" implies that we'll have to compare the depths of all possible pairs of leaves. That'd be expensive—-if there are leaves, there are possible pairs of leaves.
But we can simplify this requirement to require less work. For example, we could equivalently say:
- "The difference between the min leaf depth and the max leaf depth is 1 or less"
- "There are at most two distinct leaf depths, and they are at most 1 apart"
Hint 2
If you're having trouble with a recursive approach, try using an iterative one.
Hint 3
To get to our leaves and measure their depths, we'll have to traverse the tree somehow. What methods do we know for traversing a tree?
Hint 4
Depth-first and breadth-first are common ways to traverse a tree. Which one should we use here?
Hint 5
The worst-case time and space costs of both are the same-—you could make a case for either.
But one characteristic of our algorithm is that it could short-circuit and return false as soon as it finds two leaves with depths more than 1 apart. So maybe we should use a traversal that will hit leaves as quickly as possible...
Hint 6
Depth-first traversal will generally hit leaves before breadth-first, so let's go with that. How could we write a depth-first walk that also keeps track of our depth?
Hint 7 (solution)
We do a depth-first walk through our tree, keeping track of the depth as we go. When we find a leaf, we add its depth to a list of depths if we haven't seen that depth already.
Each time we hit a leaf with a new depth, there are two ways that our tree might now be unbalanced:
- There are more than 2 different leaf depths
- There are exactly 2 leaf depths and they are more than 1 apart.
Why are we doing a depth-first walk and not a breadth-first one? You could make a case for either. We chose depth-first because it reaches leaves faster, which allows us to short-circuit earlier in some cases.
def is_balanced(tree_root):
# A tree with no nodes is superbalanced, since there are no leaves!
if tree_root is None:
return True
# We short-circuit as soon as we find more than 2
depths = []
# We'll treat this list as a stack that will store tuples of (node, depth)
nodes = []
nodes.append((tree_root, 0))
while len(nodes):
# Pop a node and its depth from the top of our stack
node, depth = nodes.pop()
# Case: we found a leaf
if (not node.left) and (not node.right):
# We only care if it's a new depth
if depth not in depths:
depths.append(depth)
# Two ways we might now have an unbalanced tree:
# 1) more than 2 different leaf depths
# 2) 2 leaf depths that are more than 1 apart
if ((len(depths) > 2) or
(len(depths) == 2 and abs(depths[0] - depths[1]) > 1)):
return False
else:
# Case: this isn't a leaf - keep stepping down
if node.left:
nodes.append((node.left, depth + 1))
if node.right:
nodes.append((node.right, depth + 1))
return True
Complexity
time and space.
For time, the worst case is the tree is balanced and we have to iterate over all nodes to make sure.
For the space cost, we have two data structures to watch: depths and nodes.
depths will never hold more than three elements, so we can write that off as .
Because we're doing a depth first search, nodes will hold at most nodes where is the depth of the tree (the number of levels in the tree from the root node down to the lowest node). So we could say our space cost is .
But we can also relate to . In a balanced tree, is . And the more unbalanced the tree gets, the closer gets to .
In the worst case, the tree is a straight line of right children from the root where every node in that line also has a left child. The traversal will walk down the line of right children, adding a new left child to nodes at each step. When the traversal hits the rightmost node, nodes will hold half of the total nodes in the tree. Half is , so our worst case space cost is .
What We Learned
This is an intro to some tree basics. If this is new to you, don't worry—-it can take a few questions for this stuff to come together. We have a few more coming up.
Particular things to note:
Focus on depth-first vs breadth-first traversal. You should be very comfortable with the differences between the two and the strengths and weaknesses of each.
You should also be very comfortable coding each of them up.
One tip: Remember that breadth-first uses a queue and depth-first uses a stack (could be the call stack or an actual stack object). That's not just a clue about implementation, it also helps with figuring out the differences in behavior. Those differences come from whether we visit nodes in the order we see them (first in, first out) or we visit the last-seen node first (last in, first out).
Binary Search Tree Checker
Write a function to check that a binary tree is a valid binary search tree.
Here's a sample binary tree node class:
class BinaryTreeNode(object):
def __init__(self, value):
self.value = value
self.left = None
self.right = None
def insert_left(self, value):
self.left = BinaryTreeNode(value)
return self.left
def insert_right(self, value):
self.right = BinaryTreeNode(value)
return self.right
Hint 1
One way to break the problem down is to come up with a way to confirm that a single node is in a valid place relative to its ancestors. Then if every node passes this test, our whole tree is a valid BST.
Hint 2
What makes a given node "correct" relative to its ancestors in a BST? Two things:
- if a node is in the ancestor's left subtree, then it must be less than the ancestor, and
- if a node is in the ancestor's right subtree, then it must be greater than the ancestor.
Hint 3
So we could do a walk through our binary tree, keeping track of the ancestors for each node and whether the node should be greater than or less than each of them. If each of these greater-than or less-than relationships holds true for each node, our BST is valid.
The simplest ways to traverse the tree are depth-first and breadth-first. They have the same time cost (they each visit each node once). Depth-first traversal of a tree uses memory proportional to the depth of the tree, while breadth-first traversal uses memory proportional to the breadth of the tree (how many nodes there are on the "level" that has the most nodes).
Because the tree's breadth can as much as double each time it gets one level deeper, depth-first traversal is likely to be more space-efficient than breadth-first traversal, though they are strictly both additional space in the worst case. The space savings are obvious if we know our binary tree is balanced—its depth will be and its breadth will be .
But we're not just storing the nodes themselves in memory, we're also storing the value from each ancestor and whether it should be less than or greater than the given node. Each node has ancestors ( for a balanced binary tree), so that gives us additional memory cost ( for a balanced binary tree). We can do better.
Hint 4
Let's look at the inequalities we'd need to store for a given node:
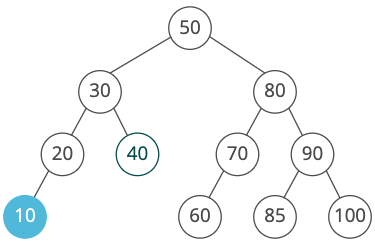
Notice that we would end up testing that the blue node is <20, <30, and <50. Of course, <30 and <50 are implied by <20. So instead of storing each ancestor, we can just keep track of a lower_bound and upper_bound that our node's value must fit inside.
Hint 5 (solution)
Solution
We do a depth-first walk through the tree, testing each node for validity as we go. If a node appears in the left subtree of an ancestor, it must be less than that ancestor. If a node appears in the right subtree of an ancestor, it must be greater than that ancestor.
Instead of keeping track of every ancestor to check these inequalities, we just check the largest number it must be greater than (its lower_bound) and the smallest number it must be less than (its upper_bound).
def is_binary_search_tree(root):
# Start at the root, with an arbitrarily low lower bound
# and an arbitrarily high upper bound
node_and_bounds_stack = [(root, -float('inf'), float('inf'))]
# Depth-first traversal
while len(node_and_bounds_stack):
node, lower_bound, upper_bound = node_and_bounds_stack.pop()
# If this node is invalid, we return false right away
if (node.value <= lower_bound) or (node.value >= upper_bound):
return False
if node.left:
# This node must be less than the current node
node_and_bounds_stack.append((node.left, lower_bound, node.value))
if node.right:
# This node must be greater than the current node
node_and_bounds_stack.append((node.right, node.value, upper_bound))
# If none of the nodes were invalid, return true
# (at this point we have checked all nodes)
return True
Instead of allocating a stack ourselves, we could write a recursive function that uses the call stack. This would work, but it would be vulnerable to stack overflow. However, the code does end up quite a bit cleaner:
def is_binary_search_tree(root,
lower_bound=-float('inf'),
upper_bound=float('inf')):
if not root:
return True
if (root.value >= upper_bound or root.value <= lower_bound):
return False
return (is_binary_search_tree(root.left, lower_bound, root.value)
and is_binary_search_tree(root.right, root.value, upper_bound))
Checking if an in-order traversal of the tree is sorted is a great answer too, especially if you're able to implement it without storing a full list of nodes.
Complexity
time and space.
The time cost is easy: for valid binary search trees, we'll have to check all nodes.
Space is a little more complicated. Because we're doing a depth first search, nodeAndBoundsStack will hold at most nodes where is the depth of the tree (the number of levels in the tree from the root node down to the lowest node). So we could say our space cost is .
But we can also relate to . In a balanced tree, is . And the more unbalanced the tree gets, the closer gets to .
In the worst case, the tree is a straight line of right children from the root where every node in that line also has a left child. The traversal will walk down the line of right children, adding a new left child to the stack at each step. When the traversal hits the rightmost node, the stack will hold half of the total nodes in the tree. Half is , so our worst case space cost is .
Bonus
What if the input tree has duplicate values?
What if -float('inf') or float('inf') appear in the input tree?
What We Learned
We could think of this as a greedy approach. We start off by trying to solve the problem in just one walk through the tree. So we ask ourselves what values we need to track in order to do that. Which leads us to our stack that tracks upper and lower bounds.
We could also think of this as a sort of "divide and conquer" approach. The idea in general behind divide and conquer is to break the problem down into two or more subproblems, solve them, and then use that solution to solve the original problem.
In this case, we're dividing the problem into subproblems by saying, "This tree is a valid binary search tree if the left subtree is valid and the right subtree is valid." This is more apparent in the recursive formulation of the answer above.
Of course, it's just fine that our approach could be thought of as greedy or could be thought of as divide and conquer. It can be both. The point here isn't to create strict categorizations so we can debate whether or not something "counts" as divide and conquer.
Instead, the point is to recognize the underlying patterns behind algorithms, so we can get better at thinking through problems.
Sometimes we'll have to kinda smoosh together two or more different patterns to get our answer.
2nd Largest Item in a Binary Search Tree
Write a function to find the 2nd largest element in a binary search tree.
Here's a sample binary tree node class:
class BinaryTreeNode(object):
def __init__(self, value):
self.value = value
self.left = None
self.right = None
def insert_left(self, value):
self.left = BinaryTreeNode(value)
return self.left
def insert_right(self, value):
self.right = BinaryTreeNode(value)
return self.right
Hint 1
Let's start by solving a simplified version of the problem and see if we can adapt our approach from there. How would we find the largest element in a BST?
Hint 2
A reasonable guess is to say the largest element is simply the "rightmost" element.
So maybe we can start from the root and just step down right child pointers until we can't anymore (until the right child is null). At that point the current node is the largest in the whole tree.
Is this sufficient? We can prove it is by contradiction:
If the largest element were not the "rightmost," then the largest element would either:
- be in some ancestor node's left subtree, or
- have a right child.
But each of these leads to a contradiction:
- If the node is in some ancestor node's left subtree it's smaller than that ancestor node, so it's not the largest.
- If the node has a right child that child is larger than it, so it's not the largest.
So the "rightmost" element must be the largest.
How would we formalize getting the "rightmost" element in code?
Hint 3
We can use a simple recursive approach. At each step:
- If there is a right child, that node and the subtree below it are all greater than the current node. So step down to this child and recurse.
- Else there is no right child and we're already at the "rightmost" element, so we return its value.
def find_largest(root_node):
if root_node.right:
return find_largest(root_node.right)
return root_node.value
Okay, so we can find the largest element. How can we adapt this approach to find the second largest element?
Hint 4
Our first thought might be, "it's simply the parent of the largest element!" That seems obviously true when we imagine a nicely balanced tree like this one:
. ( 5 )
/ \
(3) (8)
/ \ / \
(1) (4) (7) (9)
But what if the largest element itself has a left subtree?
. ( 5 )
/ \
(3) (8)
/ \ / \
(1) (4) (7) (12)
/
(10)
/ \
(9) (11)
Here the parent of our largest is 8, but the second largest is 11.
Drat, okay so the second largest isn't necessarily the parent of the largest...back to the drawing board...
Wait. No. The second largest is the parent of the largest if the largest does not have a left subtree. If we can handle the case where the largest does have a left subtree, we can handle all cases, and we have a solution.
So let's try sticking with this. How do we find the second largest when the largest has a left subtree?
Hint 5
It's the largest item in that left subtree! Whoa, we freaking just wrote a function for finding the largest element in a tree. We could use that here!
How would we code this up?
Hint 6
def find_largest(root_node):
if root_node is None:
raise ValueError('Tree must have at least 1 node')
if root_node.right is not None:
return find_largest(root_node.right)
return root_node.value
def find_second_largest(root_node):
if (root_node is None or
(root_node.left is None and root_node.right is None)):
raise ValueError('Tree must have at least 2 nodes')
# Case: we're currently at largest, and largest has a left subtree,
# so 2nd largest is largest in said subtree
if root_node.left and not root_node.right:
return find_largest(root_node.left)
# Case: we're at parent of largest, and largest has no left subtree,
# so 2nd largest must be current node
if (root_node.right and
not root_node.right.left and
not root_node.right.right):
return root_node.value
# Otherwise: step right
return find_second_largest(root_node.right)
Okay awesome. This'll work. It'll take time (where is the height of the tree) and space.
But that space in the call stack is avoidable. How can we get this down to constant space?
Hint 7 (solution)
We start with a function for getting the largest value. The largest value is simply the "rightmost" one, so we can get it in one walk down the tree by traversing rightward until we don't have a right child anymore:
def find_largest(root_node):
current = root_node
while current:
if not current.right:
return current.value
current = current.right
With this in mind, we can also find the second largest in one walk down the tree. At each step, we have a few cases:
- If we have a left subtree but not a right subtree, then the current node is the largest overall (the "rightmost") node. The second largest element must be the largest element in the left subtree. We use our
find_largest()function above to find the largest in that left subtree! - If we have a right child, but that right child node doesn't have any children, then the right child must be the largest element and our current node must be the second largest element!
- Else, we have a right subtree with more than one element, so the largest and second largest are somewhere in that subtree. So we step right.
def find_largest(root_node):
current = root_node
while current:
if not current.right:
return current.value
current = current.right
def find_second_largest(root_node):
if (root_node is None or
(root_node.left is None and root_node.right is None)):
raise ValueError('Tree must have at least 2 nodes')
current = root_node
while current:
# Case: current is largest and has a left subtree
# 2nd largest is the largest in that subtree
if current.left and not current.right:
return find_largest(current.left)
# Case: current is parent of largest, and largest has no children,
# so current is 2nd largest
if (current.right and
not current.right.left and
not current.right.right):
return current.value
current = current.right
Complexity
We're doing one walk down our BST, which means time, where is the height of the tree (again, that's if the tree is balanced, otherwise). space.
What We Learned
Here we used a "simplify, solve, and adapt" strategy.
The question asks for a function to find the second largest element in a BST, so we started off by simplifying the problem: we thought about how to find the first largest element.
Once we had a strategy for that, we adapted that strategy to work for finding the second largest element.
It may seem counter-intuitive to start off by solving the wrong question. But starting off with a simpler version of the problem is often much faster, because it's easier to wrap our heads around right away.
One more note about this one:
Breaking things down into cases is another strategy that really helped us here.
Notice how simple finding the second largest node got when we divided it into two cases:
- The largest node has a left subtree.
- The largest node does not have a left subtree.
Whenever a problem is starting to feel complicated, try breaking it down into cases.
It can be really helpful to actually draw out sample inputs for those cases. This'll keep your thinking organized and also help get your interviewer on the same page.