Specific Interview Questions
Bit Manipulation
Shifts
A bit shift moves each digit in a number's binary representation left or right. There are three main types of shifts:
Left Shifts
When shifting left, the most-significant bit is lost, and a 0 bit is inserted on the other end.
The left shift operator is usually written as "<<".
0010 << 1 → 0100
0010 << 2 → 1000
A single left shift multiplies a binary number by 2:
0010 << 1 → 0100
0010 is 2
0100 is 4
Logical Right Shifts
When shifting right with a logical right shift, the least-significant bit is lost and a 0 is inserted on the other end.
1011 >>> 1 → 0101
1011 >>> 3 → 0001
For positive numbers, a single logical right shift divides a number by 2, throwing out any remainders.
0101 >>> 1 → 0010
0101 is 5
0010 is 2
Arithmetic Right Shifts
When shifting right with an arithmetic right shift, the least-significant bit is lost and the most-significant bit is copied.
Languages handle arithmetic and logical right shifting in different ways. Javascript provides two right shift operators: >> does an arithmetic right shift and >>> does a logical right shift.
1011 >> 1 → 1101
1011 >> 3 → 1111
0011 >> 1 → 0001
0011 >> 2 → 0000
The first two numbers had a 1 as the most significant bit, so more 1's were inserted during the shift. The last two numbers had a 0 as the most significant bit, so the shift inserted more 0's.
If a number is encoded using two's complement, then an arithmetic right shift preserves the number's sign, while a logical right shift makes the number positive.
// Arithmetic shift
1011 >> 1 → 1101
1011 is -5
1101 is -3
// Logical shift
1111 >>> 1 → 0111
1111 is -1
0111 is 7
Bitwise AND
The AND operation takes two bits and returns 1 if both bits are 1. Otherwise, it returns 0.
1 & 1 → 1
1 & 0 → 0
0 & 1 → 0
0 & 0 → 0
Think of it like a hose with two knobs. Both knobs must be set to on for water to come out.
When performing AND on two integers, the AND operation is calculated on each pair of bits (the two bits at the same index in each number).
5 & 6 // gives 4
// at the bit level:
// 0101 (5)
// & 0110 (6)
// = 0100 (4)
Bitwise OR
The OR operation takes two bits and returns 1 if either of the bits are 1. Otherwise, it returns 0.
1 | 1 → 1
1 | 0 → 1
0 | 1 → 1
0 | 0 → 0
Think of it like a bucket with two holes in it. If both holes are closed, no water comes out. If either hole is open, or if both are open, water comes out.
When performing OR on two integers, the OR operation is calculated on each pair of bits (the two bits at the same index in each number).
5 | 6 // gives 7
// At the bit level:
// 0101 (5)
// | 0110 (6)
// = 0111 (7)
Bitwise NOT
The NOT bitwise operation inverts bits. A 0 becomes a 1. A 1 becomes a 0.
The NOT operator is often written as a tilde character ("~"):
~ 0000 0101
= 1111 1010
When numbers are printed in base-10, the result of a NOT operation can be surprising. In particular, positive numbers can become negative and negative numbers can become positive. For example:
~ 5 // gives -6
// At the bit level:
// ~ 0000 0101 (5)
// = 1111 1010 (-6)
This is because numbers are (usually) represented using two's complement, where the leftmost bit is actually negative. So flipping the leftmost bit usually flips the sign of the number.
Bitwise XOR
The XOR operation (or exclusive or) takes two bits and returns 1 if exactly one of the bits is 1. Otherwise, it returns 0.
1 ^ 1 → 0
1 ^ 0 → 1
0 ^ 1 → 1
0 ^ 0 → 0
Think of it like a bag of chips where only one hand can fit in at a time. If no one reaches for chips, no one gets chips, and if both people reach for chips, they can't fit and no one gets chips either!
When performing XOR on two integers, the XOR operation is calculated on each pair of bits (the two bits at the same index in each number).
5 ^ 6 // gives 3
// At the bit level:
// 0101 (5)
// ^ 0110 (6)
// = 0011 (3)
Mask
Values used in bitwise operations are sometimes called masks. (The nickname comes from the fact that the values often hide certain bits and reveal others, like a costume mask.)
Here's a mask that can be or'd with a number to set its fifth bit: 0010 0000.
And, here's a mask that can be and'd with a number to clear its third bit: 1111 0111
Problems
Under the hood, numbers are just bits set to 0 or 1. Try some of these common and trickier questions involving bit operations.
Test Bit
Given a number, write a function that tests if its ith bit is set.
def test_bit_set(number, index):
'''
Returns True if number has the index'th bit set
and False otherwise.
'''
We'll say that the bits are numbered from the least significant bit (on the right) to the most significant bit (on the left).
So, the binary number 0000 0001 has the 0th bit set and all the rest of its bits are clear (not set).
Answer
We can test if the value has a specific bit set using a left shift with an and. First, we'll create a mask by taking 1 and shifting it left until the set bit is at the index we want to test.
1 << 0 → 0000 0001 // for the 0th bit
1 << 1 → 0000 0010 // for the 1st bit
1 << 2 → 0000 0100 // for the 2nd bit
...
1 << 7 → 1000 0000 // for the 7th bit
Then, we'll & the shifted 1 with the value we're testing. If the result is zero, then the bit isn't set; otherwise, it is.
& 0101 1101
0010 0000
-----------
0000 0000
& 0101 1101
0100 0000
-----------
0100 0000
Here's an implementation in code:
def test_bit_set(number, index):
'''
Returns True if number has the index'th bit set
and False otherwise.
'''
mask = 1 << index
return number & mask != 0
You could squish this into a one-liner if you wanted. We tend to prefer clarity over brevity though.
Set Bit
Given a number, write a function that sets its ith bit to 1.
def set_bit(number, index):
'''
Set the index'th bit of number to 1, and return
the result.
'''
Answer
We can set a specific bit using a left shift with an or. First, we'll make a mask by taking a 1 and shifting it left until the set bit is at the index we want to set.
1 << 0 → 0000 0001 // for the 0th bit
1 << 1 → 0000 0010 // for the 1st bit
1 << 2 → 0000 0100 // for the 2nd bit
...
1 << 7 → 1000 0000 // for the 7th bit
Then, we'll | the shifted 1 with the value. This sets the bit to 1, leaving all the other bits unchanged.
| 0101 1101
0010 0000
-----------
0111 1101
Here's an implementation in code:
def set_bit(number, index):
'''
Set the index'th bit of number to 1, and return
the result.
'''
mask = 1 << index
return number | mask
Again, this could be a one-liner if you wanted.
Clear Bit
Given a number, write a function that clears its ith bit by setting it to 0.
def clear_bit(number, index):
'''
Set the index'th bit of number to 0, and return
the result.
'''
Answer
We can clear a specific bit set using a left shift, a not, and an and.
First, we'll make our mask by taking 1, shifting it left until the set bit is at the index we want to clear, and not'ing the result. This makes a mask where every bit is set except for the one we want to clear.
~(1 << 0) → 1111 1110 // for the 0th bit
~(1 << 1) → 1111 1101 // for the 1st bit
~(1 << 2) → 1111 1011 // for the 2nd bit
...
~(1 << 7) → 0111 1111 // for the 7th bit
Then, we'll & the shifted 1 with the value we're testing. This clears the bit that we left as 0 and leaves all the other bits unchanged.
& 0101 1101
1011 1111
-----------
0001 1101
Here's an implementation in code:
def clear_bit(number, index):
'''
Set the index'th bit of number to 0, and return
the result.
'''
mask = ~(1 << index)
return number & mask
Toggle Bit
Given a number, write a function that toggles its ith bit. (If the bit is 1, set it to 0. If it's 0, set it to 1.)
def toggle_bit(number, index):
'''
Toggle the index'th bit of number. (If it's 0, set it to
1; if it's 1, set it to 0.)
'''
Answer
We can set a specific bit using a left shift with an exclusive or.
First, we'll take 1 and shift it left until the set bit is at the index we want to set.
1 << 0 → 0000 0001 // for the 0th bit
1 << 1 → 0000 0010 // for the 1st bit
1 << 2 → 0000 0100 // for the 2nd bit
...
1 << 7 → 1000 0000 // for the 7th bit
Then, we'll ^ the shifted 1 with the value. If the bit was a 1, then the ^ with a 1 sets it to zero. If the bit was a 0, then the ^ with a 1 sets it to one. All the other bits are xor'd with zero, leaving them unchanged.
^ 0101 1101
0010 0000
-----------
0111 1101
^ 0101 1101
0100 0000
-----------
0001 1101
Here's an implementation in code:
def toggle_bit(number, index):
'''
Toggle the index'th bit of number. (If it's 0, set it to
1; if it's 1, set it to 0.)
'''
mask = 1 << index
return number ^ mask
Single Bit Set
Given a number, write a function that determines if the number has exactly one bit set.
def single_bit_set(number):
'''
Return True if number has exactly one bit set to 1; False
if it has any other number of bits set to 1.
'''
Sometimes, you'll hear this problem framed in terms of powers of two: "Write a function that determines if a number is a power of two."
All powers of two have exactly one bit set, so these questions are identical.
Answer
We can determine if a number has exactly one bit set with an and.
First, we'll take the number and subtract 1.
0100 0000 - 0000 0001 → 0011 1111
0000 1000 - 0000 0001 → 0000 0111
0101 0111 - 0000 0001 → 0101 0110
1110 1010 - 0000 0001 → 1110 1001
Notice how the subtraction clears the least-significant set bit and sets all the lower bits to 1. Everything to the left of the least-significant set bit is unchanged.

Look what happens when we & number with number - 1:

This clears the least-significant set bit and leaves the rest of the number unchanged.
If there is exactly one bit set, then the result of the & will be zero.
If there are multiple bits set, then the & will only clear the lowest bit, leaving the other bits set.
Here's how we'd write this in code:
def single_bit_set(number):
'''
Return True if number has exactly one bit set to 1; False
if it has any other number of bits set to 1.
'''
# Special case for zero
if number == 0:
return False
return number & (number - 1) == 0
SQL
All code below assumes usage of MySQL.
We'll be going through six questions covering topics like query performance, joins, and SQL injection. They'll refer to the same database for cakes, customers, and orders at a bakery. Here's the schema:
CREATE TABLE cakes (
cake_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
flavor VARCHAR(100) NOT NULL
);
CREATE TABLE customers (
customer_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
first_name VARCHAR(100) NOT NULL,
last_name VARCHAR(100) NOT NULL,
phone VARCHAR(15),
street_address VARCHAR(255),
city VARCHAR(255),
zip_code VARCHAR(5),
referrer_id INT,
FOREIGN KEY (referrer_id) REFERENCES customers (customer_id)
);
CREATE TABLE orders (
order_id INT NOT NULL AUTO_INCREMENT PRIMARY KEY,
cake_id INT NOT NULL,
customer_id INT,
pickup_date DATE NOT NULL,
FOREIGN KEY (cake_id) REFERENCES cakes (cake_id),
FOREIGN KEY (customer_id) REFERENCES customers (customer_id)
);
How can we make this query faster?
We want the order ID of every order in January and February, 2017. This is the query we've got so far:
SELECT order_id FROM orders WHERE DATEDIFF(orders.pickup_date, '2017-03-01') < 0;
-- 161314 rows in set (0.25 sec)
Answer
First, we could consider adding an index on pickup_date. This'll make our inserts less efficient, but will drastically make this query faster.
Bringing up the tradeoffs of your suggestions will impress your interviewer. Excellent answers always consider the bigger picture—-side effects or downsides, and any alternative solutions.
ALTER TABLE orders ADD INDEX (pickup_date);
SELECT order_id FROM orders WHERE DATEDIFF(orders.pickup_date, '2017-03-01') < 0;
-- 161314 rows in set (0.24 sec)
Whoa! What happened? We added an index but didn't get an improvement.
This is because we're using the DATEDIFF function in the WHERE clause. Functions evaluate for every row in a table without using the index!
Easy fix here—-we can just compare the pickup date and March 1 directly:
SELECT order_id FROM orders WHERE orders.pickup_date < '2017-03-01';
-- 161314 rows in set (0.07 sec)
There we go, about 0.25 seconds down to about 0.07 seconds.
How can we get the nth highest number of orders a single customer has?
We made a view of the number of orders each customer has:
CREATE VIEW customer_order_counts AS
SELECT customers.customer_id, first_name, count(orders.customer_id) AS order_count
FROM customers LEFT OUTER JOIN orders
ON (customers.customer_id = orders.customer_id)
GROUP BY customers.customer_id;
A note about views
A view in SQL is a stored query that acts like a virtual table.
As a simple example, if we build this view:
CREATE VIEW order_flavors AS
SELECT order_id, customer_id, pickup_date, flavor
FROM orders INNER JOIN cakes
ON orders.cake_id = cakes.cake_id;
We can query order_flavors like a table:
SELECT last_name, flavor, pickup_date
FROM order_flavors INNER JOIN customers
ON order_flavors.customer_id = customers.customer_id
So for example, Nancy has 3 orders:
SELECT * FROM customer_order_counts ORDER BY RAND() LIMIT 1;
+-------------+------------+-------------+
| customer_id | first_name | order_count |
+-------------+------------+-------------+
| 9118 | Nancy | 3 |
+-------------+------------+-------------+
Answer
Let's start by solving a simpler problem-—how would we just get the highest number of orders? Pretty trivial since we have a built-in function:
SELECT MAX(order_count) FROM customer_order_counts;
-- 1 row in set (1.89 sec)
Now can we adapt this to get the second highest number of orders?
Well, if we can get the highest order count, we can get "the highest order count that's not the highest order count":
SELECT MAX(order_count) FROM customer_order_counts WHERE order_count NOT IN (
SELECT MAX(order_count) FROM customer_order_counts);
-- 1 row in set (3.89 sec)
This works, but it's pretty slow. Any ideas for a faster query?
We could also sort the order_counts. Then we don't have to scan the whole table twice. We just jump down to the second row:
SELECT order_count FROM customer_order_counts ORDER BY order_count DESC LIMIT 1, 1;
-- 1 row in set (1.93 sec)
If LIMIT has one argument, that argument is the number of rows to return starting with the first row. With 2 arguments, the first argument is the row offset and the second argument is the number of rows to return. So in our query with "1, 1" we're saying "starting one row down from the top, give us one row."
Now, how do we get the nth highest order count?
Easy—-we just change the row offset in our LIMIT clause:
SELECT order_count FROM customer_order_counts ORDER BY order_count DESC LIMIT N-1, 1;
As a bonus, how would you do this with pure SQL, not relying on MySQL's handy LIMIT clause? It's tricky!
What ways can we use wildcard characters in LIKE clauses?
See the answer below.
Answer
LIKE lets you use two wildcard characters, "%" and "_".
"%" matches any amount of characters (including zero characters). So if we want all our customers whose last name starts with "A", we could query:
SELECT customer_id, last_name FROM customers WHERE last_name LIKE 'a%';
(We could use the BINARY keyword if we wanted a case-sensitive comparison. It would treat the string we're comparing as a binary string, so we'd compare bytes instead of characters.)
"_" matches exactly one character. If we want all our customers who live on the 200 block of Flatley Avenue in Dover, we could query:
SELECT first_name, street_address FROM customers
WHERE street_address LIKE '2__ Flatley Avenue' AND city = 'Dover';
And some databases (like SQL Server, but not MySQL or PostgreSQL) support sets or ranges of characters. So we could get every customer whose city starts with either "m" or "d":
SELECT customer_id FROM customers WHERE city LIKE '[md]%';
Or whose last name starts with any character in the range "a" through "m" ("a", "b", "c"..."k", "l", "m"):
SELECT customer_id FROM customer WHERE last_name LIKE '[a-m]%'
Now how can we make this query faster?
We're mailing a promotion to all our customers named Sam who live in Dover. Since some customers go by names that aren't exactly Sam, like Samuel or Sammy, we use names like Sam. Here's how we find them:
SELECT first_name, last_name, street_address, city, zip_code FROM customers
WHERE first_name LIKE '%sam%' AND city = 'Dover';
-- 1072 rows in set (0.42 sec)
That's pretty slow. How can we speed it up?
Answer
First, do we need to get the city and zip code for every customer? The search is constructed using the city Dover, so we know the city. And we know that the zip code for Dover is 33220. If we can complete the addresses efficiently somewhere else in our code, there's no reason to get that information from the database for every result.
SELECT first_name, last_name, street_address FROM customers
WHERE first_name LIKE '%sam%' AND city = 'Dover';
-- 1072 rows in set (0.40 sec)
A little better, but only a little.
Let's look at that wildcard % before "sam." Wildcards at the beginning of comparisons can slow down performance because instead of just looking at names that start with "sam" the query has to look at every character in every first name.
Do we really need the wildcard % before sam? Should our customers with "sam" in their name but not at the start of their name, like Rosamond, be included in a Sam Promotion?
Probably not. Let's just try removing the % at the beginning and adding an index on first_name:
ALTER TABLE customers ADD INDEX (first_name);
SELECT first_name, last_name, street_address FROM customers
WHERE first_name LIKE 'sam%' AND city = 'Dover';
-- 1065 rows in set (0.02 sec)
0.42 seconds down to 0.02 seconds!
This is a huge improvement. But-—these changes are a big deal because we're changing functionality. This isn't just faster, it's different. Some customers won't be getting a promotion in the mail now. The decision of who's included in the promotion would probably be made independent of database performance. But it's always a good idea to look out for wildcard characters at the beginning of a pattern.
What are all the SQL joins?
Answer
First, let's talk about the keywords "inner" and "outer." They're optional—-INNER JOIN is the same as JOIN, and LEFT OUTER JOIN is the same as LEFT JOIN. These keywords are added for clarity because they make the joins easier to understand conceptually. Some developers leave them out, arguing there's no reason to have extra nonfunctional words in a database query. The most important thing is to be consistent. We'll use them.
Inner joins give only the rows where all the joined tables have related data. If we inner join our customers and orders, we'll get all the related customers and orders. We won't get any customers without orders or any orders without customers.
SELECT first_name, phone, orders.cake_id, pickup_date
FROM customers INNER JOIN orders
ON customers.customer_id = orders.customer_id;
+------------+------------+---------+-------------+
| first_name | phone | cake_id | pickup_date |
+------------+------------+---------+-------------+
| Linda | 8095550114 | 4 | 2017-10-12 |
| May | 8015550130 | 4 | 2017-02-03 |
| Frances | 8345550120 | 1 | 2017-09-16 |
| Matthew | 8095550122 | 3 | 2017-07-20 |
| Barbara | 8015550157 | 2 | 2017-07-07 |
...
If we wanted the cake flavor, not just the cake ID, we could also join the cake table:
SELECT first_name, phone, cakes.flavor, pickup_date
FROM customers
INNER JOIN orders ON customers.customer_id = orders.customer_id
INNER JOIN cakes ON orders.cake_id = cakes.cake_id;
+------------+------------+-----------+-------------+
| first_name | phone | flavor | pickup_date |
+------------+------------+-----------+-------------+
| Frances | 8345550120 | Chocolate | 2017-09-16 |
| Theodore | 8015550175 | Chocolate | 2017-08-13 |
| James | 8015550165 | Chocolate | 2017-10-12 |
| Kathleen | 8095550157 | Chocolate | 2017-09-24 |
| Jennifer | 8015550153 | Chocolate | 2017-06-22 |
...
Left outer joins give all the rows from the first table, but only related rows in the next table. So if we run a left outer join on customers and orders, we'll get all the customers, and their orders if they have any.
SELECT cake_id, pickup_date, customers.customer_id, first_name
FROM orders LEFT OUTER JOIN customers
ON orders.customer_id = customers.customer_id
ORDER BY pickup_date;
+---------+-------------+-------------+------------+
| cake_id | pickup_date | customer_id | first_name |
+---------+-------------+-------------+------------+
| 2 | 2017-01-01 | NULL | NULL |
| 3 | 2017-01-01 | 108548 | Eve |
| 1 | 2017-01-01 | 857831 | Neil |
| 4 | 2017-01-01 | NULL | NULL |
| 3 | 2017-01-01 | 168516 | Maria |
...
Right outer joins include any related rows in the first table, and all the rows in the next table. Right outer joining our customers and orders would give the customer if there is one, and then every order.
In our schema, customer_id isn't NOT NULL on orders. This may be seem unintuitive, but maybe we don't require customers to register with us to place an order, or orders can be associated with other models like restaurant or vendor. In any case, with our schema, we can have orders without customers.
SELECT customers.customer_id, first_name, pickup_date
FROM customers RIGHT OUTER JOIN orders
ON customers.customer_id = orders.customer_id
ORDER BY pickup_date;
+-------------+------------+-------------+
| customer_id | first_name | pickup_date |
+-------------+------------+-------------+
| NULL | NULL | 2017-01-01 |
| 108548 | Eve | 2017-01-01 |
| 857831 | Neil | 2017-01-01 |
| NULL | NULL | 2017-01-01 |
| NULL | NULL | 2017-01-01 |
...
Right outer joins give the same result as left outer joins with the order of the tables switched:
SELECT customers.customer_id, first_name, pickup_date
FROM orders LEFT OUTER JOIN customers
ON customers.customer_id = orders.customer_id
ORDER BY pickup_date;
# same results as right outer join we just did!
+-------------+------------+-------------+
| customer_id | first_name | pickup_date |
+-------------+------------+-------------+
| NULL | NULL | 2017-01-01 |
| 108548 | Eve | 2017-01-01 |
| 857831 | Neil | 2017-01-01 |
| NULL | NULL | 2017-01-01 |
| NULL | NULL | 2017-01-01 |
...
Full outer joins take all the records from every table. Related data are combined like the other joins, but no rows from any table are left out. For customers and orders, we'll get all the related customers and orders, and all the customers without orders, and all the orders without customers.
The standard SQL syntax is:
SELECT order_id, pickup_date, customers.customer_id, first_name
FROM orders FULL OUTER JOIN customers
ON orders.customer_id = customers.customer_id;
But MySQL doesn't support full outer joins! No problem, we can get the same result with a UNION of left and right outer joins:
SELECT order_id, pickup_date, customers.customer_id, first_name
FROM orders LEFT OUTER JOIN customers
ON orders.customer_id = customers.customer_id
UNION
SELECT order_id, pickup_date, customers.customer_id, first_name
FROM orders RIGHT OUTER JOIN customers
ON orders.customer_id = customers.customer_id;
+----------+-------------+-------------+------------+
| order_id | pickup_date | customer_id | first_name |
+----------+-------------+-------------+------------+
| 900075 | 2017-05-17 | NULL | NULL |
| 900079 | 2017-12-26 | 487996 | Frances |
| 900057 | 2017-10-25 | 498546 | Loretta |
| NULL | NULL | 640804 | Whitney |
| NULL | NULL | 58405 | Zoe |
...
Using UNION or UNION ALL with this strategy generally emulates a full outer join. But things get complicated for some schemas, like if a column in the ON clause isn't NOT NULL.
Cross joins give every row from the first table paired with every row in the next table, ignoring any relationship. With customers and orders, we'd get every customer paired with every order. Cross joins are sometimes called Cartesian joins because they return the cartesian product of data sets-—every combination of elements in every set.
This isn't used often because the results aren't usually useful. But sometimes you might actually need every combination of the rows in your tables, or you might need a large table for performance testing. If you cross join 2 tables with 10,000 rows each, you get a table with 100,000,000 rows!
Self joins refer to any join that joins data in the same table. For example, some of our customers were referred to our bakery by other customers. We could do a left outer join to get every customer and their referrer if they have one:
SELECT customer.first_name, referrer.first_name
FROM customers AS customer LEFT OUTER JOIN customers AS referrer
ON customer.referrer_id = referrer.customer_id;
+------------+------------+
| first_name | first_name |
+------------+------------+
| Tim | NULL |
| Mattie | Wendy |
| Kurtis | NULL |
| Jared | NULL |
| Lucille | Tim |
...
What's an example of SQL injection and how can we prevent it?
Answer
SQL injection is when a hacker gains access to our database because we used their malicious user input to build a dynamic SQL query.
Let's say we have an input field that takes a phone number, and we use it to build this SQL query:
const sqlText = `SELECT * FROM customers WHERE phone = '${phoneInput}';`;
We're expecting something like "8015550198" which would neatly build:
SELECT * FROM customers WHERE phone = '8015550198';
But what if a user enters "1' OR 1=1;--"?
Then we'd have:
SELECT * FROM customers WHERE phone = '1' OR 1=1;--';
Which will return the data for every customer because the WHERE clause will always evaluate to true! (1 always equals 1, and the "--" comments out the last single quotation mark.)
With the right input and queries, SQL injection can let hackers create, read, update and destroy data.
So to prevent SQL injection, we'll need to look at how we build and run our SQL queries. And we can think about some smart technical design in our application.
Here are five ways to protect ourselves:
1. Use stored procedures or prepared SQL statements. So do not build dynamic SQL. This is the most effective way to prevent SQL injection.
For example, we could build a prepared statement:
// MySQL client for node.js (node-mysql2)
const mysql = require('mysql2');
// Connect to the database
const connection = mysql.createConnection({user: 'root@localhost', database: 'bakery'});
const statement = 'SELECT * FROM customers WHERE phone = ?';
connection.execute(statement, [phoneInput], (err, rows) => {
// Process resulting rows
});
Or we could build a stored procedure get_customer_from_phone() with a string parameter inputPhone:
DELIMITER //
CREATE PROCEDURE get_customer_from_phone
(IN input_phone VARCHAR(15))
BEGIN
SELECT * FROM customers
WHERE phone = input_phone;
END //
DELIMITER ;
which we could call like this:
const sql = require('mssql');
sql.connect('mssql://username:password@host/database').then(() => {
new sql.Request()
.input('phone_input', sql.VarChar(15), phone_input)
.execute('get_customer_from_phone').then(recordsets => {
console.dir(recordsets);
})
.catch(err => {
// Error checks
});
});
2. Validate the type and pattern of input. If you know you're looking for specific data—-like an ID, name, or email address-—validate any user input based on type, length, or other attributes.
For example, here's one way we could validate a phone number:
function isValidPhone(phoneNumber) {
// Check for null, empty or undefined string
if (!phoneNumber) {
return false;
}
// Contains only valid phone characters
// has exactly 10 digits
return phoneNumber.match(
/^\(?([0-9]{3})\)?[-. ]?([0-9]{3})[-. ]?([0-9]{4})$/);
}
3. Escape special characters like quotes. This approach is a quick and easy way to reduce the chances of SQL injection, but it's not fully effective.
For example, let's say we want to escape backslashes, single and double quotes, new lines (\n and \r), and null (\0):
function escapeInput(input) {
// Escape backslashes first so we don't escape the
// backslashes we'll add to escape other special characters
let escapedInput = input.replace('\\', '\\\\');
const charToReplacement = {
'\0': '\\0',
'\n': '\\n',
'\r': '\\r',
'\'': '\\\'',
'\"': '\\\"',
};
Object.entries(charToReplacement).forEach(([charToReplace, replacement]) => {
if (escapedInput.indexOf(charToReplace) < 0) {
return;
}
escapedInput = escapedInput.replace(charToReplace, replacement);
});
return escapedInput;
}
(See table 10.1 in the MySQL String Literals docs for a full list of special character escape sequences.)
In Node, you could also use the mysql client's escape() function (which additionally escapes tabs and backspace characters):
// MySQL client for node.js (node-mysql)
const mysql = require('mysql');
const phoneParam = mysql.escape(phoneInput);
When we escape our input, now our query will be:
SELECT * FROM customers WHERE phone = '1\' OR 1=1;--';
which isn't a valid query.
4. Limit database privileges. Application accounts that connect to the database should have as few privileges as possible. It's unlikely, for example, that your application will ever have to delete a table. So don't allow it.
5. Don't display database error messages to users. Error messages contain information that could tell hackers a lot of information about your data. Best practice is to give generic database error messages to users, and log detailed errors where developers can access them. Even better, send an alert to the dev team when there's an error.
Testing and QA
What tests would you write for this function?
A bakery is using software to fine tune how many pies to bake each day. It doesn't want to run out of pies to sell, but it also doesn't want too many pies left unsold at the end of the day.
Test a function getChangeInNumberOfPiesToBake(). The function:
- Takes the number of pies leftover at the end of the day yesterday
- Returns the change in the number of pies we should bake today
The algorithm for the change in the number of pies to bake is:
- If 0 pies were left over, increase the number of pies we bake by 40
- If 1-20 pies were left over, don't change how many pies we bake
- If more than 20 pies were left over, reduce the number of pies we bake today by: the amount of pies left over yesterday, minus 20
Examples:
getChangeInNumberOfPiesToBake(0); // 40
getChangeInNumberOfPiesToBake(9); // 0
getChangeInNumberOfPiesToBake(31); // -11
Input and output are both integers.
Answer
For this function, different ranges of inputs lead to different behavior. This'll help us choose which inputs to test.
Specifically, we care about these ranges of the number of pies left over:
- Below 0
- 0
- 1 to 20
- Above 20
We should also ask the interviewer if there's an upper bound on the input. Having 50 pies left over might be a normal disappointing day, but something's seriously wrong if we have a billion unsold pies, right? Let's say the most pies we can bake in a day is 900, so we'll treat anything over 900 as invalid input.
Ok, so these are our ranges:
- Below 0
- 0
- 1 to 20
- 21 to 900
- Above 900
Identifying these ranges is useful because testing only the five numbers -1, 0, 10, 50, and 901 would be more effective than testing hundreds of numbers between 21 and 900. To our function, all the numbers between 21 and 900 are effectively equivalent. This technique of identifying ranges is called equivalence partitioning.
So is testing any 5 numbers in our 5 ranges enough?
No. It would give us a good idea that the basic logic works, but we might miss off-by-one errors if we're not careful about the edges of the ranges.
At a minimum we should test all these inputs at the boundaries of our ranges:
-1, 0, 1, 20, 21, 900, 901
Testing these values is called boundary value analysis.
Next, we should ensure we don't accept or return decimals. The input and output were specified as integers (which makes sense—we can't bake a fraction of a pie).
What if we get an invalid input type, like a string? Different languages handle this differently. Java, C#, C++ and C wouldn't let you pass the wrong type of argument, Python and Ruby might give you a TypeError (or worse, might not give you an error), and JavaScript will let you get away with almost anything. So the importance of making sure we get an error for invalid input types depends on our language.
Now how would you test this function?
We have a function to find the nth decimal digit of Pi, and we want to make sure it works.
The function is one-based starting with the first decimal. So the first decimal digit is 1, the second is 4, the third is 1, and so on:
3.14159265... // Pi
12345678... // n
Examples:
getNthDigitOfPi(1); // 1
getNthDigitOfPi(4); // 5
getNthDigitOfPi(71); // 0
getNthDigitOfPi(900); // 3
getNthDigitOfPi(-4); // RangeError: no nonpositive digits
getNthDigitOfPi(0); // RangeError: no nonpositive digits
Answer
We kind of have ranges like the last question-—"above zero" and "zero or below." But other than that we don't have any bounds on the input or any changes in behavior based on the input. Sure, 0 and 1 will be important to test, but those aren't enough on their own.
In general for any function that takes numbers as input, it's a good idea to consider testing:
- Negative numbers
- 0
- 1
- 2
- 10, and higher by orders of magnitude
- The highest Integer (like the highest 32 bit integer, or something more specific to your system or language)
This generally covers a basic set of edge cases, potential special cases, base cases, and a reasonable range of values.
The bakery got a new POS system. How would you test checking out with a credit card?
It won't be enough to see if the system takes a valid credit card and processes a payment. We need to also make sure the system rejects invalid cards and gracefully handles cases when things go wrong.
Tests that check if the system works with valid input are called positive tests, and tests that check if the system gives the correct behavior for invalid input are called negative tests.
Let's get started. We should test a few areas:
Credit card information
From swiping and manual entry, the system should correctly handle:
- Credit card numbers that are valid, invalid, an invalid length, and blank.
- Expiration dates that are valid, expired, not expired but incorrect, and blank.
- CVV numbers that are correct, incorrect, an invalid length, and blank.
Physical things about the card
A card might have an unreadable strip or be damaged. Or it might be swiped incorrectly. If the system has a chip reader, we should cover that too.
Limits and restrictions
Do we have a self-imposed limit on the amount we can charge? Or the amount of times we can run the same card? Do we reject certain credit card companies, like American Express?
Failure
Finally, we should make sure we get safe, expected, reasonable behavior when the system fails. What should happen when the internet or bank communication system goes down? What about after an improper shutdown, like a power outage or if the terminal is suddenly unplugged? And should something happen if the terminal is in the middle of a transaction and there's no activity for an unexpectedly long amount of time?
How many scenarios do we need to test for this function?
getCakePrice() determines what to charge for a cake. It has 3 parameters:
size // String, either '1-10 guests' or '11-20 guests'
writing // String, max 30 characters, blank allowed
pickupTime // Date object
(writing is what we'll write on the cake.)
Here's how the values are set by the user:
sizeis a radio button. 1-10 guests is selected by default.writingis a text input field, limited to 30 characters. The field is blank by default.pickupTimeis selected from a calendar, limited to times when the bakery is open. The calendar does not go back in time. Tomorrow at 6:00 pm is selected by default.
And here's how we determine the cost of a cake:
$45for 1 to 10 guests$75for 11 to 20 guests+$15for writing and same day pickup
Answer
Let's start by looking at the possible values for each parameter.
The size of the cake is easy—-it can only be one of two options, '1-10 guests' or '11-20 guests'. The radio button with a default is nice because we know we don't have to worry about invalid or blank input.
But wait—-do we know we don't have to worry about invalid or blank input? We got specifications of the field types and defaults in the UI, but what if we have an API and someone directly hits it?
This is a good question to ask your interviewer because it shows an ability to think of things that could go wrong. In this case, the spirit of the question doesn't involve catching edge cases, so we'll assume the arguments are reliably and intentionally restricted, and you can count on valid input.
The writing on the cake can be blank or present. We don't have to worry about it being too long because the input is already limited to 30 characters. We might want to ask our interviewer if we allow any 30 characters. What about obscure special characters or offensive words? We'll say there's no restriction—-these problems are rare enough and messy enough that we can just follow up by phone if we're concerned about the message.
For pickup time, looks like we only have 2 values to look for. Times today or times later than today. We know the input is a calendar, has a default, and doesn't allow times when the bakery is closed. So we don't have to worry about blank or invalid input. Although a reasonable question would be to ask about a limit in the future-—how far in advance can someone order a cake? We'll say there's no limit here.
Ok, let's lay this all out. What are all the combinations of inputs we can have?
Well, we have 2 possibilities for size, 2 possibilities for writing, and 2 possibilities for pickup time. So that's 8 combinations (2 x 2 x 2 = 8).

We know enough to answer the question now, but let's take it a step further and look at the price for each scenario.

This kind of table—-showing the possible combination of values for a set of conditions, and identifying the actions we take-—is called a decision table. This kind of thinking will get even more helpful as the total number of parameters and possible values grows. What if we had different prices for different flavors? What if the inputs could be blank or invalid? Decision tables help us methodically design comprehensive tests.
Sometimes decision tables can also help combine scenarios that have the same action (for example, we could combine the first 2 columns and say "if a cake is for 1-10 guests and writing is blank, it doesn't matter what the pickup time is—we charge $45"). But this can be dangerous for testing-—what if a bug factors in the pickup time when it shouldn't?
So for this this function, we should test 8 scenarios—-every possible combination of inputs.
What types of tests should we write?
This question is intentionally vague. It's designed to see if you have an organized way of thinking about test design.
Answer
We should make sure we consider these kinds of tests:
Unit tests and Integration tests
Unit tests cover single functions or small testable units. Integration tests cover how larger components work together. Unit tests can detect low level bugs before they affect other areas of a program, and can help with design and development. Integration tests catch a broader range of bugs because they cover interactions and can be designed around actual use cases. A good test suite usually involves a mix of both integration and unit tests.
Regression tests
Regression tests cover bugs after they're caught and fixed. Many teams have a standard that whenever a bug is fixed, a test should be added that fails without the fix and passes with the fix. The idea here is that we found something wrong and we fixed it—-let's not break it again
Load and stress testing
Load testing puts a system under a high but realistic load, usually to make sure the system can handle it without any serious impacts on performance. Stress testing looks at what happens when a system is overwhelmed beyond what it can handle, usually to make sure the system fails gracefully (say, by giving useful error messages instead of freezing). Load and stress tests are both important for scaling.
Security testing
Software should never expose sensitive data, have unprotected authentication credentials, or carelessly trust user input. Penetration testing (or just pen testing), for example, tries to harmlessly exploit vulnerabilities in a system so they can be patched. The more sensitive the data you hold, the more important security testing is.
What to test and what not to test?
Our program is complex enough that it's infeasible for us to test every combination of inputs or every path. How should we choose what to test and what not to test?
One way to start deciding what to test is risk-based testing, focusing on what's most likely to have a bad impact. For example, failure in the signup flow might completely halt new business. Or if we charge customers the wrong amount we could make users angry and even get in legal trouble.
We can also break down the severity and priority of potential problems. Sometimes there's a tricky balance between the two-—for example, are we more worried about a feature that fails occasionally for the 80% of users using Chrome or Safari, or a feature that's totally unusable to the 5% on Internet Explorer?
A specific way to get reasonable coverage with fewer tests is combinatorial testing. Let's say we have an app to regularly check and record our bakery's refrigerator temperatures. We have 2 digital thermometer models (T and TX), 2 app versions (iOS and Android), and 2 connection methods (bluetooth and USB). Similar to a decision table, we can lay out every possible combination. There are 8 configurations for getting refrigerator temperatures:
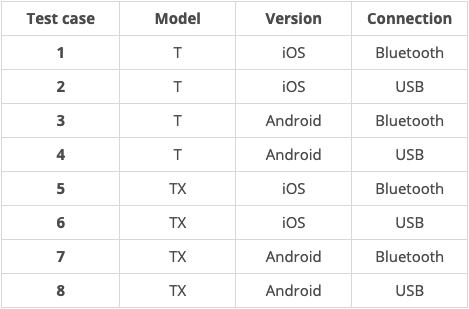
But with combinatorial testing, we can reduce this to 4 tests by just testing pairs. Instead of asking "Does every model work on every version with every connection?" we can separately ask:
- Do all the models and versions work together?
- Do all the models and connections work together?
- Do all the versions and connections work together?
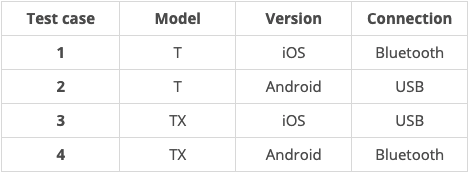
We've reduced our total tests by half, and this approach becomes even more powerful as the number of conditions and the possible values for each condition grows. It's not unrealistic to reduce a quintillion (a billion billion) possible combinations down to hundreds of tests.
If we're worried that just testing pairs isn't enough, we can test the interaction of 3 values or any values. Research shows that the interaction of 6 values is usually enough to find all the bugs in a system, even for complex and dangerous systems like air traffic collision avoidance, medical devices, and space flight.
So combinatorial testing can save us a huge amount of time with no cost or a low cost to effectiveness.