General Programming
Readings
Short Circuit Evaluation
Short-circuit evaluation is a strategy most programming languages (including JavaScript) use to avoid unnecessary work. For example, say we had a conditional like this:
if (itIsFriday && itIsRaining) {
console.log('board games at my place!');
}
Let's say itIsFriday is false. Because JavaScript short-circuits evaluation, it wouldn't bother checking the value of itIsRaining—-it knows that either way the condition is false and we won't print the invitation to board game night.
We can use this to our advantage. For example, say we have a check like this:
if (friends['Becky'].isFreeThisFriday()) {
inviteToBoardGameNight(friends['Becky']);
}
What happens if 'Becky' isn't in our friends object? Since friends['Becky'] is undefined, when we try to call isFreeThisFriday() we'll get a TypeError. Instead, we could first confirm that Becky and I are still on good terms:
if (friends.hasOwnProperty('Becky') && friends['Becky'].isFreeThisFriday()) {
inviteToBoardGameNight(friends['Becky']);
}
This way, if 'Becky' isn't in friends, JavaScript will ignore the rest of the conditional and avoid throwing the TypeError.
This is all hypothetical, of course. It's not like things with Becky are weird or anything. We're totally cool. She's still in my friends object for sure and I hope I'm still in hers and Becky if you're reading this I just want you to know you're still in my friends object.
Garbage Collection
A garbage collector automatically frees up memory that a program isn't using anymore. For example, say we did this in JavaScript:
function getMin(nums) {
// NOTE: this is *not* the fastest way to get the min!
const numsSorted = nums.slice().sort();
return numsSorted[0];
}
const myNums = [5, 3, 1, 4, 6];
console.log(getMin(myNums));
Look at numsSorted in getMin(). We allocate that whole array inside our function, and once the function returns we don't need the array anymore. In fact, once the function returns we don't have any references to it anymore! What happens to that array in memory? The JavaScript garbage collector will notice we don't need it anymore and free up that space.
How does a garbage collector know when something can be freed? One option is to start by figuring out what we can't free. For example, we definitely can't free local variables that we're going to need later on. And, if we have an array, then we also shouldn't free any of the array's elements. This is the main intuition behind one garbage collector strategy:
- Carefully figure out what things in memory we might still be using or need later on.
- Free everything else.
This strategy is often called tracing garbage collection, since we usually implement the first step by tracing references from one object (say, the array) to the next (an element within the array). A different option is to have each object keep track of the number of things that reference it-—like a variable holding the location of an array or multiple edges pointing to the same node in a graph. We call this number an object's reference count. In this case, a garbage collector can free anything with a reference count of zero. This strategy is called reference counting, since we are counting the number of times each object is referenced.
Some languages, like C, don't have a garbage collector. So we need to manually free up any memory we've allocated once we're done with it:
// make a string that can hold 15 characters
// including the terminating null byte ('\0')
str = malloc(15);
// ... do some stuff with it ...
// we're done. free that memory!
free(str);
We sometimes call this manual memory management. Some languages, like C++, have both manual and automatic memory management.
Closures
A closure is a function that accesses a variable "outside" itself. For example:
const message = 'The British are coming.';
function sayMessage(){
alert(message); // Here we have access to message,
// even though it's declared outside this function!
}
We'd say that message is "closed over" by sayMessage().
One useful thing to do with a closure is to create something like an "instance variable" that can change over time and can affect the behavior of a function.
// Function for getting the id of a dom element,
// giving it a new, unique id if it doesn't have an id yet
const getUniqueId = (() => {
let nextGeneratedId = 0;
return element => {
if (!element.id) {
element.id = `generated-uid-${nextGeneratedId}`;
nextGeneratedId++;
}
return element.id;
};
})();
Why did we put nextGeneratedId in an immediately-executed anonymous function? It makes nextGeneratedId private, which prevents accidental changes from the outside world:
// Function for getting the id of a dom element,
// giving it a new, unique id if it doesn't have an id yet
let nextGeneratedId = 0;
const getUniqueId = element => {
if (!element.id) {
element.id = `generated-uid-${nextGeneratedId}`;
nextGeneratedId++;
}
return element.id;
};
// ...
// Somewhere else in the codebase...
// ...
// WHOOPS--FORGOT I WAS ALREADY USING THIS FOR SOMETHING
nextGeneratedId = 0;
Mutable vs Immutable Objects
A mutable object can be changed after it's created, and an immutable object can't. In Javascript, everything (except for strings) is mutable by default:
const array = [4, 9];
array[0] = 1;
// array is now [1, 9]
Freezing an object makes it immutable, though:
const array = [4, 9];
// Make it immutable
Object.freeze(array);
array[0] = 1;
// array is still [4, 9]
Strings can be mutable or immutable depending on the language. Strings are immutable in Javascript:
const testString = 'mutable?';
testString[7] = '!';
// String is still 'mutable?'
// (but no error is raised!)
But in some other languages, like Swift, strings can be mutable:
var testString = "mutable?"
if let range = testString.range(of: "?") {
testString.replaceSubrange(range, with: "!")
// testString is now "mutable!"
}
Mutable objects are nice because you can make changes in-place, without allocating a new object. But be careful—whenever you make an in-place change to an object, all references to that object will now reflect the change.
Practice
Rectangular Love
A crack team of love scientists from OkEros (a hot new dating site) have devised a way to represent dating profiles as rectangles on a two-dimensional plane.
They need help writing an algorithm to find the intersection of two users' love rectangles. They suspect finding that intersection is the key to a matching algorithm so powerful it will cause an immediate acquisition by Google or Facebook or Obama or something.
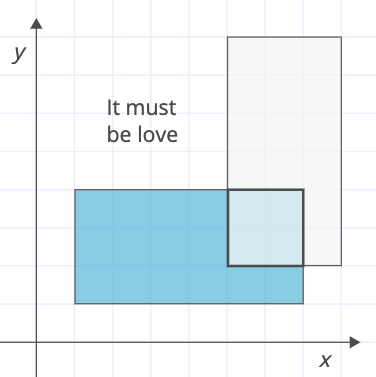
Write a function to find the rectangular intersection of two given love rectangles.
As with the example above, love rectangles are always "straight" and never "diagonal." More rigorously: each side is parallel with either the x-axis or the y-axis.
They are defined as dictionaries like this:
my_rectangle = {
# Coordinates of bottom-left corner
'left_x' : 1,
'bottom_y' : 1,
# Width and height
'width' : 6,
'height' : 3,
}
Your output rectangle should use this format as well.
Hint 1
Let's break this problem into subproblems. How can we divide this problem into smaller parts?
Hint 2
We could look at the two rectangles' "horizontal overlap" or "x overlap" separately from their "vertical overlap" or "y overlap."
Let's start with a helper function find_x_overlap().
Hint 3
Need help finding the x overlap?
Since we're only working with the x dimension, we can treat the two rectangles' widths as ranges on a 1-dimensional number line.
What are the possible cases for how these ranges might overlap or not overlap? Draw out some examples!
Hint 4
There are four relevant cases:
1) The ranges partially overlap:

2) One range is completely contained in the other:

3) The ranges don't overlap:

4) The ranges "touch" at a single point:

Let's start with the first 2 cases. How do we compute the overlapping range?
Hint 5
One of our ranges starts "further to the right" than the other. We don't know ahead of time which one it is, but we can check the starting points of each range to see which one has the highest_start_point. That highest_start_point is always the left-hand side of the overlap, if there is one.
Not convinced? Draw some examples!
Similarly, the right-hand side of our overlap is always the lowest_end_point. That may or may not be the end point of the same input range that had the highest_start_point—-compare cases (1) and (2).
This gives us our x overlap! So we can handle cases (1) and (2). How do we know when there is no overlap?
Hint 6
If highest_start_point > lowest_end_point, the two rectangles do not overlap.
But be careful—-is it just greater than or is it greater than or equal to?
Hint 7
It depends how we want to handle case (4) above.
If we use greater than, we treat case (4) as an overlap. This means we could end up returning a rectangle with zero width, which ... may or may not be what we're looking for. You could make an argument either way.
Let's say a rectangle with zero width (or zero height) isn't a rectangle at all, so we should treat that case as "no intersection."
Can you finish find_x_overlap()?
Hint 8
Here's one way to do it:
def find_x_overlap(x1, width1, x2, width2):
# Find the highest ("rightmost") start point and
# lowest ("leftmost") end point
highest_start_point = max(x1, x2)
lowest_end_point = min(x1 + width1, x2 + width2)
# Return null overlap if there is no overlap
if highest_start_point >= lowest_end_point:
return (None, None)
# Compute the overlap width
overlap_width = lowest_end_point - highest_start_point
return (highest_start_point, overlap_width)
How can we adapt this for the rectangles' ys and heights?
Hint 9
Can we just make one find_range_overlap() function that can handle x overlap and y overlap?
Hint 10
Yes! We simply use more general parameter names:
def find_range_overlap(point1, length1, point2, length2):
# Find the highest start point and lowest end point.
# The highest ("rightmost" or "upmost") start point is
# the start point of the overlap.
# The lowest end point is the end point of the overlap.
highest_start_point = max(point1, point2)
lowest_end_point = min(point1 + length1, point2 + length2)
# Return null overlap if there is no overlap
if highest_start_point >= lowest_end_point:
return (None, None)
# Compute the overlap length
overlap_length = lowest_end_point - highest_start_point
return (highest_start_point, overlap_length)
We've solved our subproblem of finding the x and y overlaps! Now we just need to put the results together.
Hint 11 (solution)
Solution
We divide the problem into two halves:
- The intersection along the x-axis
- The intersection along the y-axis
Both problems are basically the same as finding the intersection of two "ranges" on a 1-dimensional number line.
So we write a helper function find_range_overlap() that can be used to find both the x overlap and the y overlap, and we use it to build the rectangular overlap:
def find_range_overlap(point1, length1, point2, length2):
# Find the highest start point and lowest end point.
# The highest ("rightmost" or "upmost") start point is
# the start point of the overlap.
# The lowest end point is the end point of the overlap.
highest_start_point = max(point1, point2)
lowest_end_point = min(point1 + length1, point2 + length2)
# Return null overlap if there is no overlap
if highest_start_point >= lowest_end_point:
return (None, None)
# Compute the overlap length
overlap_length = lowest_end_point - highest_start_point
return (highest_start_point, overlap_length)
def find_rectangular_overlap(rect1, rect2):
# Get the x and y overlap points and lengths
x_overlap_point, overlap_width = find_range_overlap(rect1['left_x'],
rect1['width'],
rect2['left_x'],
rect2['width'])
y_overlap_point, overlap_height = find_range_overlap(rect1['bottom_y'],
rect1['height'],
rect2['bottom_y'],
rect2['height'])
# Return null rectangle if there is no overlap
if not overlap_width or not overlap_height:
return {
'left_x' : None,
'bottom_y' : None,
'width' : None,
'height' : None,
}
return {
'left_x' : x_overlap_point,
'bottom_y' : y_overlap_point,
'width' : overlap_width,
'height' : overlap_height,
}
Complexity
time and space.
Bonus
What if we had a list of rectangles and wanted to find all the rectangular overlaps between all possible pairs of two rectangles within the list? Note that we'd be returning a list of rectangles.
What if we had a list of rectangles and wanted to find the overlap between all of them, if there was one? Note that we'd be returning a single rectangle.
What We Learned
This is an interesting one because the hard part isn't the time or space optimization—-it's getting something that works and is readable.
For problems like this, I often see candidates who can describe the strategy at a high level but trip over themselves when they get into the details.
Don't let it happen to you. To keep your thoughts clear and avoid bugs, take time to:
- Think up and draw out all the possible cases. Like we did with the ways ranges can overlap.
- Use very specific and descriptive variable names.
Temperature Tracker
You decide to test if your oddly-mathematical heating company is fulfilling its All-Time Max, Min, Mean and Mode Temperature Guarantee™.
Write a class TempTracker with these methods:
insert()-—records a new temperatureget_max()-—returns the highest temp we've seen so farget_min()-—returns the lowest temp we've seen so farget_mean()-—returns the mean of all temps we've seen so farget_mode()-—returns a mode of all temps we've seen so far
Optimize for space and time. Favor speeding up the getter methods get_max(), get_min(), get_mean(), and get_mode() over speeding up the insert() method.
get_mean() should return a float, but the rest of the getter methods can return integers. Temperatures will all be inserted as integers. We'll record our temperatures in Fahrenheit, so we can assume they'll all be in the range .
If there is more than one mode, return any of the modes.
Hint 1
The first thing we want to optimize is our getter methods (per the instructions).
Our first thought might be to throw our temperatures into a list or linked list as they come in. With this method, getting the max_temp and min_temp would take time. It would also cost us space. But we can do better.
What if we kept track of the max_temp and min_temp as each new number was inserted?
Hint 2
That's easy enough:
class TempTracker(object):
def __init__(self):
self.min_temp = float('inf')
self.max_temp = float('-inf')
def insert(self, temperature):
if temperature > self.max_temp:
self.max_temp = temperature
if temperature < self.min_temp:
self.min_temp = temperature
def get_max(self):
return self.max_temp
def get_min(self):
return self.min_temp
This wins us time for get_max() and get_min(), while keeping time for insert() and removing the need to store all the values.
Can we do something similar for get_mean()?
Hint 3
Unlike with min_temp and max_temp, the new temp and the previous mean won't give us enough information to calculate the new mean. What other information will we need to track?
Hint 4
To calculate a mean we need to know:
- how many values there are
- the sum of all the values
Hint 5
So we can augment our class to keep track of the number_of_readings and total_sum. Then we can compute the mean as values are inserted:
class TempTracker(object):
def __init__(self):
# For mean
self.number_of_readings = 0
self.total_sum = 0.0 # Mean should be float
self.mean = None
# For min and max
self.min_temp = float('inf')
self.max_temp = float('-inf')
def insert(self, temperature):
# For mean
self.number_of_readings += 1
self.total_sum += temperature
self.mean = self.total_sum / self.number_of_readings
# For min and max
if temperature > self.max_temp:
self.max_temp = temperature
if temperature < self.min_temp:
self.min_temp = temperature
def get_max(self):
return self.max_temp
def get_min(self):
return self.min_temp
def get_mean(self):
return self.mean
Can we do something similar for the mode? What other information will we need to track to compute the mode?
Hint 6
To calculate the mode, we need to know how many times each value has been inserted.
How can we track this? What data structures should we use?
Hint 7
Solution
We maintain the max_temp, min_temp, mean, and mode as temperatures are inserted, so that each getter method simply returns a property.
To maintain the mean at each insert, we track the number_of_readings and the total_sum of numbers inserted so far.
To maintain the mode at each insert, we track the total occurrences of each number, as well as the max_occurrences we've seen so far.
class TempTracker(object):
def __init__(self):
# For mode
self.occurrences = [0] * 111 # List of 0s at indices 0..110
self.max_occurrences = 0
self.mode = None
# For mean
self.number_of_readings = 0
self.total_sum = 0.0 # Mean should be float
self.mean = None
# For min and max
self.min_temp = float('inf')
self.max_temp = float('-inf')
def insert(self, temperature):
# For mode
self.occurrences[temperature] += 1
if self.occurrences[temperature] > self.max_occurrences:
self.mode = temperature
self.max_occurrences = self.occurrences[temperature]
# For mean
self.number_of_readings += 1
self.total_sum += temperature
self.mean = self.total_sum / self.number_of_readings
# For min and max
if temperature > self.max_temp:
self.max_temp = temperature
if temperature < self.min_temp:
self.min_temp = temperature
def get_max(self):
return self.max_temp
def get_min(self):
return self.min_temp
def get_mean(self):
return self.mean
def get_mode(self):
return self.mode
We don't really need the getter methods since they all return properties. We could directly access the properties!
# Method
temp_tracker.get_mean()
# Attribute
temp_tracker.mean
We'll leave the getter methods in our solution because the question specifically asked for them.
But otherwise, we probably would use properties instead of methods. In JavaScript we usually don't make getters if we don't have to, to avoid unnecessary layers of abstraction. But in Java we would use getters because they give us flexibility-—if we wanted to change how we calculate values (for example, we might want to calculate a value just-in-time), it won't change how other people interact with our class—-they wouldn't have to switch from using a property to using a getter method. Different languages, different conventions.
Complexity
time for each method, and space related to input! (Our occurrences list's size is bounded by our range of possible temps, in this case 0-110)
What We Learned
This question brings up a common design decision: whether to do work just-in-time or ahead-of-time.
Our first thought for this question might have been to use a just-in-time approach: have our insert() method simply put all of the temperatures in a list as they are recorded, and then have our getters compute e.g. the mode just-in-time, at the moment the getter is called.
Instead, we used an ahead-of-time approach: have our insert method compute and store our mean, mode, max, and min ahead of time (that is, before they're asked for). So our getter just returns the precomputed value in time.
In this case, the ahead-of-time approach doesn't just speed up our getters...it also reduces our space cost. If we stored all the temperatures as they came in and computed each metric just-in-time, we'd need space for insert()s.
As an added bonus, the ahead-of-time approach didn't increase our asymptotic time cost for inserts, even though we added more work. With some cleverness (channeling some greedy thinking to figure out what we needed to store in order to update the answer in time), we were able to keep it at time.
It doesn't always happen this way. Sometimes there are trade-offs between just-in-time and ahead-of-time. Sometimes to save time in our getters, we have to spend more time in our insert.
In those cases, whether we should prefer a just-in-time approach or an ahead-of-time approach is a nuanced question. Ultimately it comes down to your usage patterns. Do you expect to get more inserts than gets? Do slow inserts have a stronger negative effect on users than slow gets?
We have some more questions dealing with this stuff coming up later.
Whenever you're designing a data structure with inserts and getters, think about the advantages and disadvantages of a just-in-time approach vs an ahead-of-time approach.
Bonus
There's at least one way to use a just-in-time approach, have time for each operation, and keep our space cost at for inserts. How could we do that?